- リリース ノート
- 基本情報
- インストール
- 構成
- Integrations
- 認証
- アプリおよびディスカバリー アクセラレータを使用する
- AppOne のメニューとダッシュボード
- AppOne の設定
- TemplateOne 1.0.0 のメニューとダッシュボード
- TemplateOne 1.0.0 セットアップ
- TemplateOne のメニューとダッシュボード
- TemplateOne 2021.4.0 のセットアップ
- Purchase-to-Pay Discovery Accelerator のメニューとダッシュボード
- Purchase to Pay Discovery Accelerator の設定
- Order to Cash Discovery Accelerator のメニューとダッシュボード
- Cash Discovery Accelerator の設定への注文
- 基本コネクタ (AppOne 用)
- SAP コネクタ
- SAP Order to Cash Connector for AppOne
- SAP Purchase to Pay Connector for AppOne
- SAP Connector for Purchase to Pay Discovery Accelerator
- SAP Connector for Order-to-Cash Discovery Accelerator
- Superadmin
- ダッシュボードとグラフ
- テーブルとテーブル項目
- アプリケーションの整合性
- 使い方 ....
- SQL コネクタを使用する
- 便利なリソース
TemplateOne やディスカバリー アクセラレータなどのリリース済みの Process Mining スタンドアロン アプリに含まれる SQL コネクタと、それらを開発で使用するための前提条件
はじめに
既存の Process Mining アプリ ( TemplateOne やディスカバリー アクセラレータなど) で SQL コネクタを使用できる場合は、その SQL コネクタがリリースされたアプリに含まれます。
前提条件
以下のことが前提です。
- 「ローカルのテスト環境を設定する」で説明されている開発ツールがインストールされている。
- コネクタのバージョン管理用の Git リポジトリがある。「 Git リポジトリを使用する」をご覧ください。ダッシュボードの開発およびアプリのリリースの作成には、Git リポジトリへのアクセス権を持つ UiPath Process Mining のインストールも必要です。
リリースされたアプリ
SQL コネクタを使用してリリースされたアプリの場合、すべての変換がグループ化され、SQL コネクタの一部となります。 SQL コネクタとアプリ ダッシュボードがアプリを形成します。 アプリの構造の概要は、以下の画像でご確認ください。
リリース済みのアプリにはダッシュボード定義が含まれており、ダッシュボードにデータを表示するすべての手順をカバーしています。 まず、ソース システムからデータを抽出して SQL Server データベースに読み込みます。 次に、SQL 変換を使用してダッシュボードで期待される形式で生データを変換します。 最後に、データがダッシュボードに読み込まれます。 以下の画像で概要をご確認ください。
開発用アプリを設定する
SQL コネクタまたはアプリ のダッシュボードをカスタマイズする場合は、開発用にアプリを設定する必要があります。
開発用アプリを設定するには、以下の手順に従います。
| 手順 | 操作 |
|---|---|
| 1 | リリース (.mvtag) を [リリース] タブにアップロードします。 |
| 2 | 新しいアプリを作成し、リリースされたアプリをベース アプリとして使用します。Appsをご覧ください。アプリ用に作成した Git リポジトリを必ず選択してください。 |
| 3 | Git リポジトリに移動し、アプリを含むブランチのローカル チェックアウトを作成します。これにより、Process Mining の外部でアプリのコンテンツを操作できます。Git GUI クライアントを使用することをお勧めします。たとえば、 GitKraken または GitHub Desktop などです。 |
リリース内容
ローカル チェックアウトには、複数のファイルとフォルダーが含まれます。 以下の画像に例を示します。
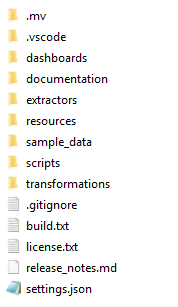
以下に、リリースの主要な内容の概要を示します。
| フォルダー | 次の値を含む |
|---|---|
.mv | フォルダーには、Process Mining ソフトウェアのビルドに関する情報が含まれます。 |
.vscode | Visual Studio コードで作業する際に関連するワークスペースの設定です。 |
dashboards | ダッシュボードの定義が含まれる .mvp ファイルです。 |
documentation | システムおよびプロセス固有のドキュメント。 たとえば、特定の SQL コネクタの構成方法、プロセスの説明、および適用できる設計上の選択肢です。 |
extractors | データを抽出し、データベースに読み込む手順です。既定では、CData Sync を使用してデータが抽出されます。load-from-file 抽出が含まれるため、コネクタの入力に適した生データ ファイルを読み込むことができます。また、 ソースからの読み込み 抽出も含まれます。 |
resources | 翻訳ファイルとダッシュボードの設定が含まれるフォルダーです。 |
sample_data | .csv ファイルは抽出されたデータの形式で、ソース システムに接続していない場合にサンプル データセットとして使用できます。このサンプル データはコネクタの入力と一致するため、開発設定の検証だけでなく、リリースされたアプリのプレビューにも使用できます。 |
scripts | 運用環境でスケジュール設定できる、データを自動的に抽出、変換、読み込むスクリプト |
transformations | データを変換する SQL ステートメントを含む dbt プロジェクト。 |
.gitignore | バージョン管理で無視する必要のある、アプリの内容を表示する Git 固有のファイルです。 |
build.txt | このアプリを作成するために結合されたコネクタとダッシュボードの部分に関する情報。 |
license.txt | UiPath Process Mining 製品の標準ライセンス ファイルです。 |
release_notes.md | アプリのリリース ノート。 |
settings.json | アプリの内部設定。 このファイルの内容を更新する必要はありません。 |
以下の画像でセットアップの概要を確認してください。
これで、変換をカスタマイズし、必要に応じてダッシュボードを編集するために必要なすべての手順を実行できます。
詳しくは、「 SQL コネクタをカスタマイズする」をご覧ください。
アプリをリリースする
Process Mining サーバーで次の手順を実行します。
| 手順 | 操作 |
|---|---|
| 1 | リリースを作成します。「リリースを作成する」をご覧ください。リリース タグが Git リポジトリに作成されます。このバージョンは、運用サーバーにインストールします。 |
| 2 | リリースをデプロイします。「アプリとディスカバリーアクセラレータをデプロイする」を参照してください。 |
| 3 | データベース接続を構成します。たとえば、 TemplateOne で TemplateOne.settings.csv ファイルをアップロードします。 |
運用サーバーで次の手順を実行し、変換を実行し、データを読み込みます。
| 手順 | 操作 |
|---|---|
| 4 | 運用環境のサーバーでアプリのリリース済みバージョンを確認します。Git GUI クライアントを使用することをお勧めします。たとえば、 GitKraken または GitHub Desktop などです。 |
| 5 | dbt プロジェクトとプロファイルを構成します。 |
| 6 | スクリプトを設定します。 |