- Versionshinweise
- Erste Schritte
- Installation
- Hard- und Softwareanforderungen
- Serverinstallation
- Aktualisierung der Lizenz
- Bereitstellen des UiPath Process Mining-Profilers
- Bereitstellen eines Connectors (.mvp)
- Aktualisieren von UiPath Process Mining
- Aktualisieren einer benutzerdefinierten Version einer App oder eines Discovery Accelerators
- Installieren einer Trainingsumgebung
- Konfiguration
- Integrationen
- Authentication
- Working with Apps and Discovery Accelerators
- AppOne-Menüs und -Dashboards
- AppOne-Einrichtung
- Menüs und Dashboards von TemplateOne 1.0.0
- Setup von TemplateOne 1.0.0
- TemplateOne menus and dashboards
- Setup von TemplateOne 2021.4.0
- Purchase-to-Pay Discovery Accelerator-Menüs und -Dashboards
- Einrichtung des Purchase-to-Pay-Discovery-Beschleunigers
- Menüs und Dashboards des Order-to-Cash Discovery Accelerators
- Einrichtung des Order-to-Cash Discovery-Beschleunigers
- Basic Connector for AppOne
- Bereitstellen des einfachen Connectors
- Einführung zu Basic Connector
- Eingabetabellen des Basic Connectors
- Hinzufügen von Tags
- Hinzufügen von Automatisierungsschätzungen
- Hinzufügen von Fälligkeitsdaten
- Hinzufügen von Referenzmodellen
- Einrichten von praktisch umsetzbaren Erkenntnissen
- Festlegen von reduzierbaren Diagrammen
- Verwenden des Ausgabe-Datasets in AppOne
- Output tables of the Basic Connector
- SAP Connectors
- Introduction to SAP Connector
- SAP-Eingabe
- Überprüfen der Daten im SAP Connector
- Hinzufügen von prozessspezifischen Tags zum SAP Connector für AppOne
- Hinzufügen von prozessspezifischen Fälligkeitsdaten zum SAP Connector für AppOne
- Hinzufügen von Automatisierungsschätzungen zum SAP Connector für AppOne
- Hinzufügen von Attributen zum SAP Connector für AppOne
- Hinzufügen von Aktivitäten zum SAP Connector für AppOne
- Hinzufügen von Entitäten zum SAP Connector für AppOne
- SAP Order to Cash Connector für AppOne
- SAP Purchase to Pay Connector für AppOne
- SAP Connector for Purchase to Pay Discovery Accelerator
- SAP Connector für den Order-to-Cash Discovery Accelerator
- Superadmin
- Die Registerkarte Arbeitsbereiche
- Die Registerkarte Entwicklungsdaten
- Die Registerkarte Versionen
- Die Registerkarte Freigegebene Daten
- The Builds tab
- Die Registerkarte Serverdaten
- Die Registerkarte Einstellungen (Settings)
- Die Registerkarte Superadmin-Benutzer
- Die Registerkarte Status
- Die Registerkarte Lizenz
- Erstellen von Releases
- Anzeigen des Verlaufs der Verzweigung
- Creating Apps
- Modules
- Dashboards und Diagramme
- Tabellen und Tabellenelemente
- Anwendungsintegrität
- How to ....
- Arbeiten mit SQL-Connectors
- Introduction to SQL connectors
- Setting up a SQL connector
- CData Sync extractions
- Running a SQL connector
- Editing transformations
- Freigeben eines SQL-Connectors
- Scheduling data extraction
- Struktur von Transformationen
- Using SQL connectors for released apps
- Generating a cache with scripts
- Setting up a local test environment
- Separate development and production environments
- Nützliche Ressourcen

Process Mining-Benutzerhandbuch
Running a SQL connector
Einleitung
Diese Seite enthält Anweisungen zum Ausführen eines SQL-Connectors mithilfe von Skripts.
Voraussetzungen
run.ps1 und load.ps1 müssen auf demselben Server wie die Process Mining-Installation für die Produktion ausgeführt werden. Die extraction_cdata.ps1 und transform.ps1 können auch an anderen Orten ausgeführt werden.
Es wird davon ausgegangen, dass:
- die unter Einrichten einer lokalen Testumgebung beschriebenen Entwicklungstools müssen installiert sein.
- Der SQL-Connector wird wie unter Einrichten eines SQL-Connectors beschrieben eingerichtet.
Hinweis:
Das
scripts/-Verzeichnis des Connectors enthält eine Reihe von Standardskripten zum Ausführen und Planen der Datenextraktion, Transformation und Laden.
Ausführen eines Connectors
Führen Sie diese Schritte aus, um einen Connector auszuführen, die Daten zu extrahieren, zu transformieren und zu laden.
| Schritt | Aktion |
|---|---|
| 1 | Starten Sie Windows PowerShell als Administrator. |
| 2 | Wechseln Sie zum Verzeichnis scripts/ . |
| 3 | Führen Sie run.ps1 aus. |
Nur Extraktion wird ausgeführt
Führen Sie diese Schritte aus, um nur die Extraktion auszuführen.
| Schritt | Aktion |
|---|---|
| 1 | Starten Sie Windows PowerShell. |
| 2 | Wechseln Sie zum Verzeichnis scripts/ . |
| 3 | Führen Sie extraction_cdata.ps1 aus. |
Wenn Ihr Connector CData Sync nicht für die Datenextraktion verwendet, ist der Name von extraction_ script anders.
Nur ausgeführte Transformationen
Führen Sie diese Schritte aus, um nur die Transformationsschritte auszuführen.
| Schritt | Aktion |
|---|---|
| 1 | Starten Sie Windows PowerShell. |
| 2 | Wechseln Sie zum Verzeichnis scripts/ . |
| 3 | Führen Sie transform.ps1 aus. |
Jeder Transformationsschritt kann auch einzeln ausgeführt werden.
Nur laufende Last
Führen Sie diese Schritte aus, um nur die Ladeschritte auszuführen.
| Schritt | Aktion |
|---|---|
| 1 | Starten Sie Windows PowerShell als Administrator. |
| 2 | Wechseln Sie zum Verzeichnis scripts/ . |
| 3 | Führen Sie load.ps1 aus. |
Debuggen von Fehlern
Beim Ausführen der Skripts wird eine Protokolldatei LogFile.log erstellt. Diese Protokolldatei enthält alle Phasen der Auftragsausführung und die zugehörigen Zeitstempel. Die Protokolldatei gibt auch einen minimalen Satz von Fehlercodes zurück, die weitere Hinweise geben können.
Laden
Weitere Informationen zur Cache-Generierung finden Sie unter cache_generation_output.log , das in dem Verzeichnis generiert wird, in dem sich Ihr Ladeskript befindet.
CData-Extraktionen
Weitere Informationen zu den CData Sync-Auftragsausführungen finden Sie in Ihrer CData Sync-Instanz und überprüfen Sie die Registerkarte Protokollierung und Verlauf Ihres Auftrags. Siehe Abbildung unten.
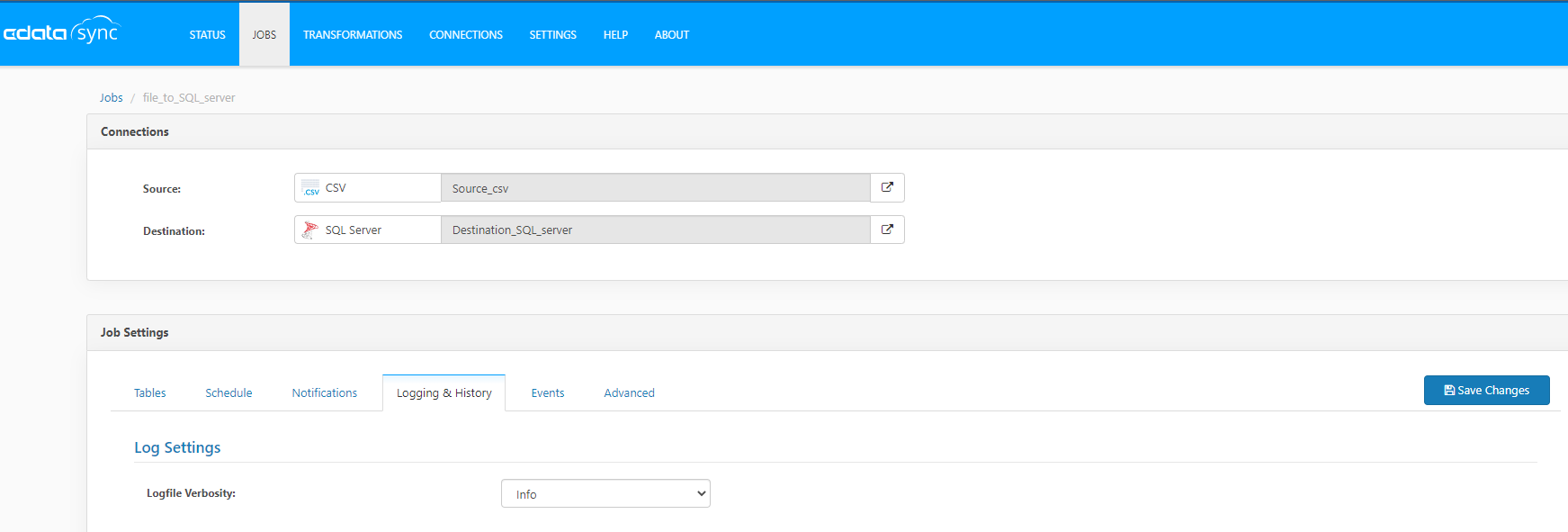
Um weitere Details zu protokollieren, legen Sie die Ausführlichkeit der Protokolldatei auf Verbose fest und führen Sie das Extraktionsskript extraction_cdata.ps1 erneut aus.
Nachfolgend finden Sie eine Übersicht über die Rückgabecodes eines CData Sync-Auftrags.
| Code | Protokollbeschreibung |
|---|---|
| 0 | Extraktion Erfolgreich für Auftrag. |
| –1 | Extraktion FEHLER für Auftrag. |
| -2 | Fehler beim Durchführen der Extraktion. Überprüfen Sie Ihre Einstellungen oder sehen Sie in der Registerkarte Protokollierung und Verlauf für Ihren Auftrag nach. |
Transformationen
Die Protokolldatei gibt auch eine Reihe von Fehlercodes des Transformationsskripts zurück. Nachfolgend finden Sie eine Übersicht über die Fehlercodes.
| Code | Protokollbeschreibung |
|---|---|
| –1 | Allgemeiner dbt run - oder dbt test -Fehler. Dies bedeutet, dass ein Problem mit dem aktuellen Setup oder der Konfiguration vorliegt. Weitere Informationen finden Sie unter LogFile.log . |
| 0* | Der dbt -Aufruf wurde ohne Fehler abgeschlossen. |
| 1* | Der dbt -Aufruf wurde mit mindestens einem behandelten Fehler abgeschlossen (z. B Modellsyntaxfehler, falsche Berechtigungen usw.). Die Ausführung wurde abgeschlossen, aber einige Modelle wurden möglicherweise übersprungen. LogFile.log enthält zusätzliche Informationen darüber, ob der Fehler in der dbt run oder in der dbt test -Phase aufgetreten ist. |
| 2* | Der dbt -Aufruf wurde mit einem nicht behandelten Fehler abgeschlossen (z. B. eine Netzwerkunterbrechung). |
- 0, 1 und 2 sind dbt–spezifische Rückgabecodes. In der offiziellen dbt-Dokumentation finden Sie weitere Informationen zu Exit-Codes.
Debuggen großer Dbt-Projekte
Wenn das Ausführen der Transformation viel Zeit in Anspruch nimmt, kann response.txt im Verzeichnis scripts/ überprüft werden. Dieses enthält die Echtzeitantworten aus dbt. Nachdem dbt test oder dbt run abgeschlossen sind, werden die Informationen an LogFile.log angehängt und die temporäre Datei wird gelöscht.
Planen von Datenextraktionen
Es ist auch möglich, Datenextraktionen in regelmäßigen Abständen zu planen. Siehe Planen der Datenextraktion.