- Notas relacionadas
- Primeros pasos
- Instalación
- Requisitos de hardware y software
- Instalación del servidor
- Actualizar la licencia
- Implementar el perfilador de UiPath Process Mining
- Implementar un conector (.mvp)
- Actualizar UiPath Process Mining
- Actualizar una versión personalizada de una aplicación o un acelerador de descubrimiento
- Instalar un entorno de pruebas
- Configuración
- Integraciones
- Autenticación
- Working with Apps and Discovery Accelerators
- Menús y paneles de AppOne
- Configuración de AppOne
- Menús y paneles de TemplateOne 1.0.0
- Configuración de TemplateOne 1.0.0
- TemplateOne menus and dashboards
- Configuración de TemplateOne 2021.4.0
- Menús y paneles de Purchase to Pay Discovery Accelerator
- Configuración del acelerador de compra para pagar
- Menús y paneles de Order to Cash Discovery Accelerator
- Orden de cobro de la configuración del Discovery Accelerator
- Basic Connector for AppOne
- Despliegue del Conector básico
- Introduction to Basic Connector
- Tablas de entrada del conector básico
- Añadir etiquetas
- Añadir estimaciones de automatización
- Añadir fechas de vencimiento
- Añadir modelos de referencia
- Setting up Actionable Insights
- Configurar gráficos contraíbles
- Utilizar el conjunto de datos de salida en AppOne
- Output tables of the Basic Connector
- SAP Connectors
- Introduction to SAP Connector
- Entrada de SAP
- Comprobación de los datos en el conector SAP
- Añadir etiquetas específicas del proceso al conector de SAP para AppOne
- Añadir fechas de vencimiento específicas del proceso al conector de SAP para AppOne
- Añadir estimaciones de automatización al conector de SAP para AppOne
- Añadir atributos al Conector SAP para AppOne
- Añadir actividades al Conector SAP para AppOne
- Añadir entidades al Conector SAP para AppOne
- Conector de pedido por cobro de SAP para AppOne
- Conector de SAP Purchase to Pay para AppOne
- Conector SAP para Purchase to Pay Discovery Accelerator
- SAP Connector for Order-to-Cash Discovery Accelerator
- Superadmin
- Paneles y gráficos
- Tablas y elementos de tabla
- Integridad de la aplicación
- How to ....
- Trabajar con conectores SQL
- Introduction to SQL connectors
- Setting up a SQL connector
- CData Sync extractions
- Running a SQL connector
- Editing transformations
- Publicar un conector SQL
- Scheduling data extraction
- Estructura de las transformaciones
- Using SQL connectors for released apps
- Generating a cache with scripts
- Setting up a local test environment
- Separate development and production environments
- Recursos útiles
Conectores SQL incluidos con las aplicaciones independientes de Process Mining lanzadas como TemplateOne y los aceleradores de descubrimiento, y los requisitos previos para utilizarlos en el desarrollo.
Introducción
Si un conector SQL está disponible para una aplicación de Process Mining existente, por ejemplo TemplateOne o un Discovery Accelerator, el conector SQL se incluye en la aplicación publicada.
Requisitos previos
Se asume que:
- las herramientas de desarrollo descritas en Configurar un entorno de prueba local están instaladas.
- tienes un repositorio Git para el control de versiones del conector. Consulta Utilizar un repositorio Git. Para el desarrollo de paneles y la creación de versiones de aplicaciones, también debes tener una instalación de UiPath Process Mining con acceso al repositorio Git.
Aplicación liberada
Para una aplicación publicada con un conector SQL, todas las transformaciones se agrupan y forman parte del conector SQL. El conector SQL junto con los paneles de la aplicación forman la aplicación. Consulta la siguiente ilustración para obtener una descripción general de la estructura de la aplicación.
Una aplicación publicada contiene las definiciones de los paneles y cubre todos los pasos para mostrar los datos en los paneles. El primer paso es extraer los datos del sistema de origen y cargarlos en una base de datos de SQL Server. El siguiente paso es transformar los datos sin procesar en el formato esperado por los paneles mediante transformaciones de SQL. Finalmente, los datos se cargan en los paneles. Consulte la siguiente ilustración para obtener una descripción general.
Configurar la aplicación para el desarrollo
Si quieres personalizar el conector SQL o los paneles de la aplicación, debes configurar la aplicación para el desarrollo.
Sigue estos pasos para configurar la aplicación para el desarrollo.
| Paso | Acción |
|---|---|
| 1 | Carga la versión (.mvtag) en la pestaña Versiones. |
| 2 | Crea una nueva aplicación y utiliza la aplicación liberada como aplicación base. Consulta Crear Apps. Asegúrate de seleccionar el repositorio Git que creaste para la aplicación. |
| 3 | Ve al repositorio Git y crea una comprobación local de la rama que contiene la aplicación. Esto te permite trabajar en el contenido de la aplicación fuera de Process Mining. Se recomienda utilizar un cliente de GUI de Git. Por ejemplo, GitKraken o GitHub Desktop. |
Contenidos de la versión
La comprobación local contiene varios archivos y carpetas. Consulta la siguiente ilustración.
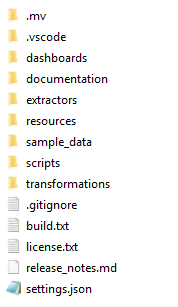
A continuación se muestra una descripción general de los contenidos principales de la versión.
| Carpeta | Contiene |
|---|---|
.mv | Carpeta que contiene la información de la compilación del software Process Mining. |
.vscode | Configuración del espacio de trabajo que es relevante cuando se trabaja en código de Visual Studio. |
dashboards | El archivo .mvp que contiene las definiciones de los paneles. |
documentation | Documentación específica de sistemas y procesos. Por ejemplo, cómo configurar el conector SQL específico, una explicación del proceso y las opciones de diseño aplicables. |
extractors | Instrucciones sobre la extracción de datos y su carga en la base de datos. De forma predeterminada, CData Sync se utiliza para extraer datos. Se incluirá una extracción de carga desde archivo , que te permite cargar archivos de datos sin procesar que se ajusten a la entrada del conector. Además, se incluirá una extracción de carga desde el origen . |
resources | Carpeta que contiene los archivos de traducción y la configuración del panel. |
sample_data | .csv en el formato de datos extraídos que puedes utilizar como conjunto de datos de muestra en caso de que no tengas conexión con el sistema de origen. Estos datos de muestra se ajustan a la entrada del conector para que puedas usarlos para validar tu configuración de desarrollo, pero también para obtener una vista previa de la aplicación lanzada. |
scripts | Scripts para extraer, transformar y cargar automáticamente los datos que puede programar en su entorno de producción. |
transformations | El proyecto dbt que contiene las instrucciones SQL para transformar los datos. |
.gitignore | Archivo específico de Git que enumera los contenidos de la aplicación que deben ignorarse en el control de versiones. |
build.txt | Información sobre el conector y la parte del panel que se combinaron para crear esta aplicación. |
license.txt | Archivo de licencia estándar del producto UiPath Process Mining. |
release_notes.md | Notas de la versión de la aplicación. |
settings.json | Configuración interna de la aplicación. No es necesario actualizar el contenido de este archivo. |
Consulta la siguiente ilustración donde se describe la configuración.
Ahora puedes seguir todos los pasos necesarios para personalizar las transformaciones y editar los paneles como desees.
Consulta Personalizar un conector SQL.
Liberar la aplicación
Realiza los siguientes pasos en el servidor de Process Mining.
| Paso | Acción |
|---|---|
| 1 | Crea una versión. Consulta Crear versiones. Se crea una etiqueta de versión en el repositorio Git. Esta versión debe instalarse en el servidor de producción. |
| 2 | Implementar la versión. Consulta Implementar aplicaciones y discovery accelerators. |
| 3 | Configura la conexión de la base de datos. Por ejemplo, en TemplateOne cargando el archivo TemplateOne.settings.csv . |
Realiza los siguientes pasos en el servidor de producción para ejecutar las transformaciones y cargar los datos.
| Paso | Acción |
|---|---|
| 4 | Comprueba la versión publicada de la aplicación en el servidor de producción. Se recomienda utilizar un cliente de GUI de Git. Por ejemplo, GitKraken o GitHub Desktop. |
| 5 | Configura el proyecto dbt y los perfiles. |
| 6 | Configure los scripts. |