- 概要
- UI Automation
- UI Automation アクティビティ パッケージについて
- UI Automation を使用して自動化されるアプリケーションと技術
- プロジェクトの対応 OS
- UI-ANA-016 - [ブラウザーを開く] に使用されている URL を検出
- UI-ANA-017 - [エラー発生時に実行を継続] の値が True
- UI-ANA-018 - OCR/画像関連のアクティビティのリスト
- UI-DBP-006 - コンテナーの使用
- UI-DBP-013 - Excel の自動化方法の誤用
- UI-DBP-030 - セレクター内での変数の使用禁止
- UI-DBP-031 - アクティビティの検証
- UI-PRR-001 - クリックをシミュレート
- UI-PRR-002 - 入力をシミュレート
- UI-PRR-003 - [アプリケーションを開く] の誤用
- UI-PRR-004 - ハードコードされた待機時間
- UI-REL-001 - セレクター内の大きいインデックス値
- UI-SEC-004 - メール アドレスのデータを含むセレクター
- UI-SEC-010 - アプリ/URL の制限
- UI-USG-011 - 許可されていない属性
- UX-SEC-010 - アプリ/URL の制限
- UX-DBP-029 - セキュリティで保護されていないパスワードの使用
- UI-PST-001 - [プロジェクト設定] の監査ログ レベル
- UiPath ブラウザー移行ツール
- クリッピング領域
- Computer Vision レコーダー
- アクティビティの索引
- アクティベート
- アンカー ベース
- ブラウザーにアタッチ
- ウィンドウにアタッチ
- ユーザー入力をブロック
- 吹き出し
- チェック
- クリック
- 画像をクリック
- 画像クリック トリガー
- OCR で検出したテキストをクリック
- テキストをクリック
- クリック トリガー
- アプリケーションを閉じる
- タブを閉じる
- ウィンドウを閉じる
- コンテキスト対応のアンカー
- 選択されたテキストをコピー
- 要素属性変更トリガー
- 要素の存在を確認
- 要素スコープ
- 要素ステート変更トリガー
- UI ツリーをエクスポート
- 構造化データを抽出
- 子要素を探す
- 要素を探す
- 画像を探す
- 一致する画像を探す
- OCR でテキスト位置を探す
- 相対要素を探す
- テキスト位置を探す
- アクティブ ウィンドウを取得
- 親要素を取得
- 属性を取得
- イベント情報を取得
- クリップボードから取得
- フル テキストを取得
- OCR でテキストを取得
- パスワードを取得
- 位置を取得
- ソース要素を取得
- テキストを取得
- 表示中のテキストを取得
- 前に戻る
- 次に進む
- ホームに移動
- Google Cloud Vision OCR
- ウィンドウを隠す
- 強調表示
- ホットキー トリガー
- ホバー
- 画像上でホバー
- OCR で検出したテキスト上でホバー
- テキスト上でホバー
- 画像の存在を確認
- 画面上で指定
- .NET コードを挿入
- JS スクリプトを挿入
- ActiveX メソッドを呼び出し
- キー操作トリガー
- 画像を読み込み
- ウィンドウを最大化
- Microsoft Azure ComputerVision OCR
- Microsoft OCR
- Microsoft Project Oxford Online OCR
- ウィンドウを最小化
- イベントを監視
- マウス トリガー
- ウィンドウを移動
- URL に移動
- OCR でテキストの存在を確認
- 要素が出現したとき
- 要素が消滅したとき
- 画像が出現したとき
- 画像が消滅したとき
- アプリケーションを開く
- ブラウザーを開く
- ブラウザーを更新
- ユーザー イベントを再生
- ウィンドウを復元
- 画像を保存
- 項目を選択
- 複数の項目を選択
- ホットキーを押下
- クリッピング領域を設定
- フォーカスを設定
- テキストを設定
- クリップボードに設定
- Web 属性を設定
- ウィンドウを表示
- プロセスを開始
- システム トリガー
- スクリーンショットを作成
- Tesseract OCR
- テキストの存在を確認
- ツールチップ
- 文字を入力
- SecureString で文字を入力
- フォアグラウンドを使用
- 属性を待つ
- 要素の消滅を待つ
- 画像の消滅を待つ
- アクセシビリティ チェック
- アプリケーション イベント トリガー
- ユーザー入力をブロック
- チェック/チェック解除
- アプリのステートを確認
- 要素を確認
- クリック
- クリック イベント トリガー
- ドラッグ アンド ドロップ
- 表データを抽出
- 要素を探す
- 繰り返し (各 UI 要素)
- ブラウザーのデータを取得
- クリップボードを取得
- テキストを取得
- URL を取得
- URL に移動
- 強調表示
- ホバー
- JS スクリプトを挿入
- キーボード ショートカット
- キー押下イベント トリガー
- マウス スクロール
- ブラウザー内を移動
- 画像を保存
- 項目を選択
- ブラウザーのデータを設定
- クリップボードに設定
- ランタイム ブラウザーを設定
- フォーカスを設定
- テキストを設定
- スクリーンショットを作成
- 文字を入力
- ユーザー入力のブロックを解除
- アプリケーション/ブラウザーを使用
- ウィンドウ操作
- UI Automation API を使用してブラウザー検索を実行し、結果を取得する
- Web の閲覧
- 画像を検索する
- 画像をクリックする
- イベントをトリガーおよび監視する
- ファイルを作成して上書きする
- HTML ページ: 情報を抽出して操作する
- ウィンドウの操作
- リスト項目の選択の自動化
- ウィンドウ要素を探して操作する
- テキスト操作の自動化を行う
- 画像を読み込んで処理する
- マウスでアクティブ化する操作を管理する
- アプリケーションランタイムの操作を自動化する
- ローカル アプリケーションの自動実行
- ブラウザーのナビゲーション
- Web オートメーション
- トリガー スコープの例
- DevExpress での UI Automation の有効化
- Computer Vision Local Server
- モバイル オートメーション
- ターミナル

UI Automation アクティビティ
出力メソッドまたは画面スクレイピング メソッド
出力メソッドまたは画面スクレイピング メソッドとは、指定した UI 要素や .pdf ファイルなどのドキュメントからデータを抽出することができるアクティビティのことです。
どのメソッドが業務プロセスの自動化に適しているのかを理解するため、各メソッドの違いを見てみましょう。
| 機能メソッド | 速度 | 精度 | バックグラウンドでの実行 | テキスト位置の抽出 | 隠されたテキストの抽出 | Citrix サポート |
|---|---|---|---|---|---|---|
| フルテキスト | 10/10 | 100% | ○ | × | ○ | × |
| ネイティブ | 8/10 | 100% | × | ○ | × | × |
| OCR | 3/10 | 98% | × | ○ | × | ○ |
[フルテキスト] は既定のメソッドです。高速で正確ですが、[ネイティブ] メソッドと違ってテキストの画面座標を抽出することはできません。
どちらのメソッドもデスクトップ アプリケーションでのみ機能しますが、[ネイティブ] メソッドは、グラフィックス デバイス インターフェイス (GDI) でテキストをレンダリングするように設計されたアプリケーションでのみ機能します。
OCR は 100% 正確というわけではありませんが、他の 2 つのメソッドでは抽出できないテキストを抽出するのに便利な場合があり、Citrix を含むすべてのアプリケーションで機能します。Studio は既定で、Tesseract と Microsoft Modi の 2 つの OCR エンジンを使用します。
OCR エンジンの言語は変更可能であり、「 OCR 言語をインストールする」をご覧ください。
| 機能メソッド | 多言語のサポート | 望ましい領域サイズ | 色反転のサポート | 予想されるテキスト書式の設定 | 許可された文字の絞り込み | Microsoft のフォントに最適であるか |
|---|---|---|---|---|---|---|
| Google Tesseract | 追加可能 | 小 | ○ | ○ | ○ | × |
| Microsoft MODI | 既定でサポート | 大 | × | × | × | ○ |
さまざまなソースからテキストを抽出する作業を始めるには、[デザイン] リボン タブの [ウィザード] グループにある [画面スクレイピング] ボタンをクリックします。
画面スクレイピング ウィザードでは、前述の 3 つのうちいずれかの出力メソッドを使用し、UI 要素を指定してそこからテキストを抽出することができます。Studio では画面スクレイピング メソッドが自動的に選択され、[画面スクレイピング ウィザード] ウィンドウの上部に表示されます。
画面スクレイピングのメソッドを変更するには、[オプション] パネルから別のメソッドを選択し、[更新] をクリックします。
スクレイピングの結果に問題がなければ、[ クリップボードにコピー ]、[ 完了] の順にクリックします。後者のオプションでは、抽出されたテキストがクリップボードにコピーされ、デザイナー パネルの [データ テーブルを生成] アクティビティに追加できます。デスクトップ記録と同様に、画面スクレイピングでも、アクティビティと各アクティビティの部分セレクターを含むコンテナー (トップレベル ウィンドウのセレクター付き) が生成されます。
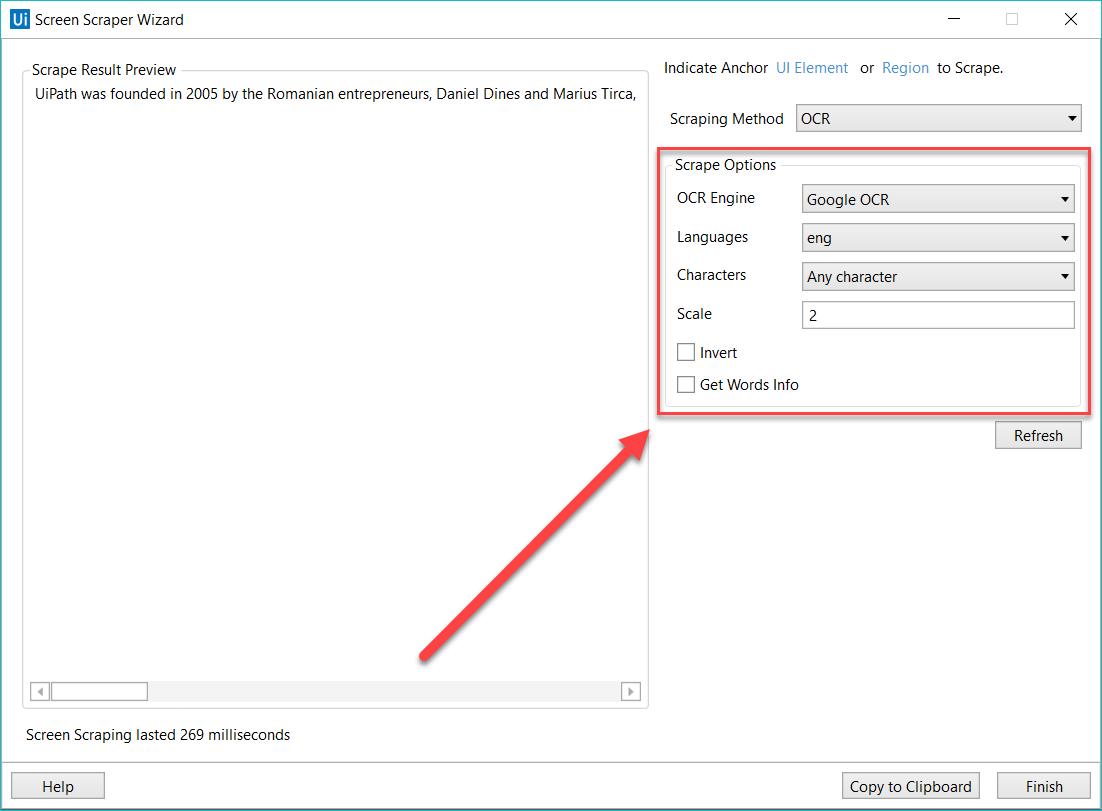
画面クレイピングは、種類ごとに異なる機能を 画面スクレイピング ウィザードの [オプション] パネルに備えています。
- フルテキスト

- [非表示のテキストを無視] – このチェックボックスをオンにすると、非表示のテキストが選択した UI 要素からコピーされません。
- ネイティブ

- [フォーマットなし] – このチェックボックスをオンにすると、コピーされるテキストに、テキストからの書式情報が抽出されません。オフにした場合は、抽出されるテキストの相対位置が保持されます。
- 文字情報を取得 – このチェックボックスをオンにすると、Studio は各単語の画面座標も取得します。さらに、[カスタム区切り文字] フィールドが表示されます。区切り文字として使用する文字を指定できます。このフィールドが空の場合は、既知のテキスト区切り文字がすべて使用されます。
- Google OCR

- 言語 – 既定では英語のみが使用できます。
- 文字の種類 – どの種類の文字を抽出するかを選択できます。次のオプションを使用できます。[任意の文字]、[数字のみ]、[文字]、[大文字]、[小文字]、[電話番号]、[通貨]、[日付]、[カスタム] です。[カスタム] を選択した場合は、さらに [許可] と [拒否] の 2 つのフィールドが表示され、どの種類の文字をスクレイピングし、どの種類の文字をスクレイピングしないのかを決める独自のルールを作成できます。
- 白黒反転 – このチェックボックスをオンにすると、スクレイピングの前に UI 要素の色が反転します。これは、背景色がテキストの色より暗い場合に便利です。
- 拡大縮小 – 選択した UI 要素または画像の倍率です。数字が大きいほど画像が拡大されます。これにより OCR の読み取り性能を高めることができるため、画像が小さい場合に利用することが推奨されます。
- 文字情報を取得 – スクレイピングした各単語の画面上の位置を取得します。
注:
Studio の一部のインスタンスでは、Google Tesseract エンジンにおいて英語以外の特定の言語で機能しないトレーニング ファイル (トレーニング ファイルについては Wikipedia、GitHub を参照) が使用される場合があります。こうした機能しないトレーニング ファイルを使用してプロジェクトを実行すると、エラーが発生する場合があります。この問題を修正するには、使用する言語に対応したトレーニング ファイルを こちらから ダウンロードして、UiPath のインストール ディレクトリの tessdata フォルダーにコピーしてください。ダウンロードしたトレーニング ファイルが機能するかどうかを確かめるには、こちらの テスト プロジェクトをダウンロードできます。
- UiPath Screen OCR
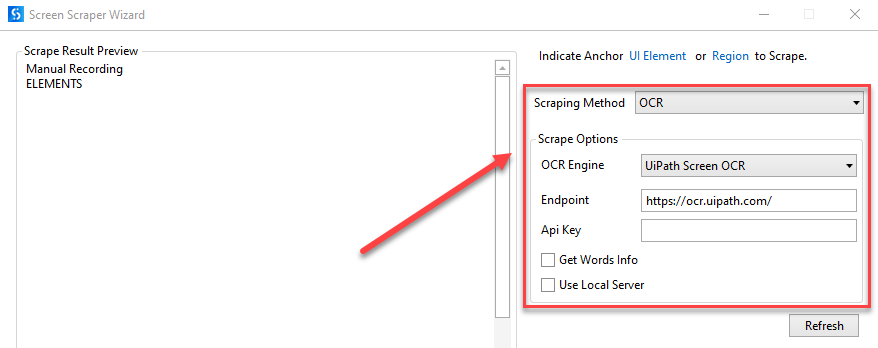
- エンドポイント - OCR モデルが公的に、または AI Center の ML Skill を通じてホストされているエンドポイントです。
- API キー - エンドポイントの API キーです。
- 文字情報を取得 – スクレイピングした各単語の画面上の位置を取得します。
- ローカル サーバーを使用 – OCR をローカルで実行する場合は、このオプションを選択します (UiPath.ComputerVision.LocalServer パッケージが必要です)。
- Microsoft OCR
重要:
Microsoft OCR スクレイピング エンジンは、.NET 5 ワークフローをサポートしていません。

- 言語 – スクレイピングするテキストの言語を変更できます。既定では英語が選択されています。
- 拡大縮小 – 選択した UI 要素または画像の倍率です。数字が大きいほど画像が拡大されます。これにより OCR の読み取り性能を高めることができるため、画像が小さい場合に利用することが推奨されます。
- 文字情報を取得 – スクレイピングした各単語の画面上の位置を取得します。
指定した UI 要素からのテキストの取得に加えて、複数種類の属性の値、UI 要素の画面上の正確な位置、UI 要素の親要素を抽出することもできます。
こうした情報は、[アクティビティ] パネルの [UI Automation] > [要素] > [検出] および [UI Automation] > [要素] > [属性] にある専用のアクティビティを通じて抽出できます。
これらのアクティビティを次に示します。
-
親要素を取得 – 指定した UI 要素から親要素を取得できます。UI 階層のどのレベルで親要素を検索するのかを指定でき、結果を UiElement 変数に格納できます。
-
属性を取得 – 指定した UI 要素の属性の値を取得します。画面上で UI 要素を指定すると、使用可能なすべての属性を含むドロップダウン リストが表示されます。
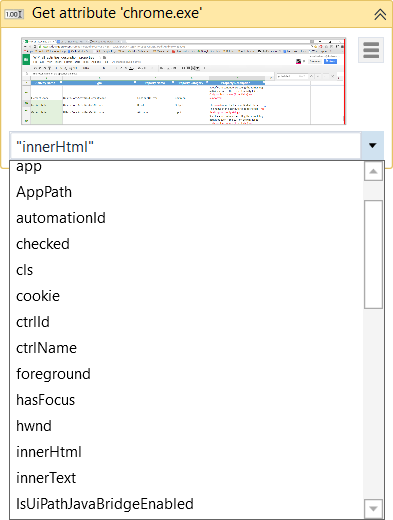
-
位置を取得 – 指定した UI 要素を囲む境界四角形を取得します。Rectangle 変数のみがサポートされています。
UiPath Studio には、アンカーを基準にして取得するテキストの場所を識別するスクレイピング メソッドである 相対スクレイピングもあります。詳しくは、「 相対スクレイピング」をご覧ください。
画面スクレイピング ウィザードを使用して、非構造化データから表を生成し、その情報を DataTable 型変数に格納することもできます。詳しくは、「 非構造化データからの表の生成」をご覧ください。