- Release notes
- Getting started
- Installation
- Configuration
- Integrations
- Authentication
- Working with Apps and Discovery Accelerators
- AppOne menus and dashboards
- AppOne setup
- TemplateOne 1.0.0 menus and dashboards
- TemplateOne 1.0.0 setup
- Getting Started with TemplateOne
- Steps to roll-out TemplateOne 1.0.0
- Input tables of TemplateOne 1.0.0
- Adding custom attributes
- Configuring the context bar
- TemplateOne menus and dashboards
- TemplateOne 2021.4.0 setup
- Purchase to Pay Discovery Accelerator menus and dashboards
- Purchase to Pay Discovery Accelerator Setup
- Order to Cash Discovery Accelerator menus and dashboards
- Order to Cash Discovery Accelerator Setup
- Basic Connector for AppOne
- SAP Connectors
- Introduction to SAP Connector
- SAP input
- Checking the data in the SAP Connector
- Adding process specific tags to the SAP Connector for AppOne
- Adding process specific Due dates to the SAP Connector for AppOne
- Adding automation estimates to the SAP Connector for AppOne
- Adding attributes to the SAP Connector for AppOne
- Adding activities to the SAP Connector for AppOne
- Adding entities to the SAP Connector for AppOne
- SAP Order to Cash Connector for AppOne
- SAP Purchase to Pay Connector for AppOne
- SAP Connector for Purchase to Pay Discovery Accelerator
- SAP Connector for Order-to-Cash Discovery Accelerator
- Superadmin
- Dashboards and charts
- Tables and table items
- Application integrity
- How to ....
- Working with SQL connectors
- Introduction to SQL connectors
- Setting up a SQL connector
- CData Sync extractions
- Running a SQL connector
- Editing transformations
- Releasing a SQL Connector
- Scheduling data extraction
- Structure of transformations
- Using SQL connectors for released apps
- Generating a cache with scripts
- Setting up a local test environment
- Separate development and production environments
- Useful resources
Process Mining user guide
Introduction
This page describes the necessary steps to roll out a customized version of TemplateOne to end-users. It starts with the input data and covers all the steps that are needed to provide the data in a meaningful way to end-users.
Step 1: Set up the TemplateOne for development.
Step 2: Customize TemplateOne.
Step 3: Release the customized version of TemplateOne.
Step 4: Configure the database connection for TemplateOne.
Step 5: Run the transformations and load the data.
Step 1: Set up TemplateOne for development
Follow these steps to set up TemplateOne for development.
| Step | Action |
|---|---|
| 1 | Upload the TemplateOne release (.mvtag) to the Superadmin Releases Tab. |
| 2 | Create a new app and use the released TemplateOne app as the base app. See Creating Apps - Creating an app from a base app. Make sure that you select the Git repository you created for the app. |
| 3 | Go to the Git repository and create a local checkout of the TemplateOne branch. This enables you to work on the content outside of Process Mining. It is advised to use a Git GUI client. For example GitKraken or GitHub Desktop. |
Release contents
The local checkout contains several files and folders. See the illustration below.
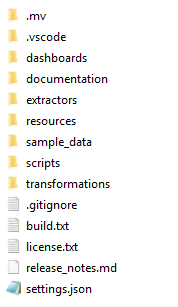
Below is an overview of the main contents of the release.
| Folder | Description |
|---|---|
.mv | Folder containing the information of the build of the Process Mining software. |
.vscode | Workspace settings that are relevant when working in Visual Studio Code. |
dashboards | The .mvp file containing the dashboards definitions. |
documentation | System and process specific documentation. For example, how to configure the specific SQL connector, an explanation of the process, and applicable design choices. |
extractors | Instructions on extracting data and loading it in the database. By default, CData Sync is used to extract data. A load-from-file extraction is included, that enables you to load raw data files that fit with the input of the connector. |
resources | Folder containing translation files and dashboard settings. |
sample_data | .csv files in the format of extracted data that you can use as a sample dataset in case you do not have a connection with the source system. This sample data fits with the input of the connector so that you can use it to validate your development setup, but also to preview the released app. |
scripts | Scripts to automatically extract, transform, and load the data, that you can schedule in your production environment. |
transformations | The dbt project containing the SQL statements to transform the data. |
.gitignore | Git specific file that lists the contents of the app which should be ignored in version control. |
build.txt | Info on the connector and dashboard part that were combined to create this app. |
license.txt | Standard license file of the UiPath Process Mining product. |
release_notes.md | Release notes of the app. |
settings.json | Internal settings for the app. The contents of this file do not have to be updated. |
See the illustration below for an overview of the setup.
Step 2: Customize TemplateOne
When TemplateOne is set up for development, you can customize the transformations and edit the dashboards as desired.
Step 3: Release the customized version of TemplateOne
Follow these steps to make the customized version of TemplateOne available to end-users.
These steps must be performed on the Process Mining server.
| Step | Action |
|---|---|
| 1 | Create a release. See Creating Releases. A release tag is created in the Git repository. This version is to be installed on the production server. |
| 2 | Deploy the release. See Deploying apps and discovery accelerators. |
Step 4: Configure the database connection for TemplateOne
To load data from the SQL Server database for use in TemplateOne you must configure the connection to the SQL Server database. You can do this by specifying the Configuration Settings in an external configuration file in .csv format. The TemplateOne.settings.csv file is included in TemplateOne release.
All SQL Server databases that have a 64-bit version can be accessed using an ODBC connection. The required 64-bit ODBC driver must be installed on the UiPath Process Mining server, and the server must be able to access that specific system.
Follow these steps to configure TemplateOne.
| Step | Action |
|---|---|
| 2 | Go to the Superadmin Workspaces tab, and locate the Dashboards folder. See the illustration below. |
| 3 | Download the TempateOne.settings.csv file and configure the settings as described below. |
| 4 | Go to the Superadmin Server data tab and upload the TemplateOne.settings.csv file. Important: Make sure you use the exact name of the file (TemplateOne.settings.csv). |
The TemplateOne.settings.csv file:
- uses
;as delimiter and“as quotation character. - must contain two lines: a header line with predetermined field names, and a line containing all values.
Configuration fields
Below is a list of the fields in the TemplateOne.settings.csv that can be used to configure TemplateOne, with a description and expected or example values.
| Setting | Description |
|---|---|
| Driver | The name of the ODBC driver used for the SQL Server database connection. For example, ODBC Driver 18 for SQL Server. The driver must be installed on the UiPath Process Mining server, and the server must be able to access that specific system. |
| Server | The name of the server on which the SQL Server database is installed. |
| Database | The name of the SQL Server database that is used for TemplateOne. |
| Schema | The name of the schema in the SQL Server database that is used for TemplateOne. |
| User | The user account that is used to log in to the SQL Server database. |
| Use credential store | Define whether the credential store is used. Possible values are true or false. If this setting is set to true, the password field must contain the identifier for the credential store password field you are trying to use. See Use a Credential Store. |
| Password | Password of the account that is used to log in to the SQL Server database, or the password identifier from the credential store. In case the credential store is used, Use credential store should be set to true. |
Using a Credential store for password storage
A credential store allows you to use passwords without showing the actual password. For the ODBC connection from the SAP Connector to the SAP database, it is also possible to use a Credential store to store the actual password of the SAP account in a secured way. For more information, see Use a Credential Store.
Step 5: Run the transformations and load the data
Perform the following steps on the production server to run the transformations and load the data into the SQL Server database.
| Step | Action |
|---|---|
| 1 | Check out the released version of the app on the production server. It is advised to use a Git GUI client. For example GitKraken or GitHub Desktop. |
| 2 | Configure the dbt project and the profiles. See. |
| 3 | Configure the scripts for CData Sync and dbt. . . |
| 4 | Run the SQL Connector: • Start Windows PowerShell as admin. • Go to the scripts/ directory. • Execute run.ps1. |
- Introduction
- Step 1: Set up TemplateOne for development
- Release contents
- Step 2: Customize TemplateOne
- Step 3: Release the customized version of TemplateOne
- Step 4: Configure the database connection for TemplateOne
- Configuration fields
- Using a Credential store for password storage
- Step 5: Run the transformations and load the data