- Notas de versão
- Introdução
- Instalação
- Requisitos de hardware e software
- Instalação do servidor
- Atualizando a Licença
- Implantando o Profiler do UiPath Process Mining
- Implantando um conector (.mvp)
- Atualizando o UiPath Process Mining
- Atualizando uma versão personalizada de um aplicativo ou acelerador de descoberta
- Instalando um Ambiente de Treinamento
- Configuração
- Integrações
- Autenticação
- Working with Apps and Discovery Accelerators
- Menus e painéis do AppOne
- Configuração do AppOne
- Menus e painéis do TemplateOne 1.0.0
- Configuração do TemplateOne 1.0.0
- TemplateOne menus and dashboards
- Configuração do TemplateOne 2021.4.0
- Menus e painéis do Acelerador de Descoberta Purchase to Pay
- Configuração do acelerador Discovery de compra para pagamento
- Menus e painéis do Acelerador de Descoberta Order a Cash
- Order to Cash Discovery Accelerator Setup
- Basic Connector for AppOne
- Implantar o Conector Básico
- Introduction to Basic Connector
- Tabelas de entrada do Conector Básico
- Adicionando tags
- Adição de estimativas de automação
- Adicionando Datas de conclusão
- Adicionando modelos de referência
- Setting up Actionable Insights
- Configuração de gráficos recolhíveis
- Usando o conjunto de dados de saída no AppOne
- Output tables of the Basic Connector
- SAP Connectors
- Introduction to SAP Connector
- Entrada do SAP
- Verificando os dados no SAP Connector
- Adicionando tags específicas do processo ao SAP Connector para o AppOne
- Adição de datas de vencimento específicas do processo ao SAP Connector para o AppOne
- Adicionando estimativas de automação ao SAP Connector para o AppOne
- Adicionando atributos ao SAP Connector para o AppOne
- Adicionando atividades ao SAP Connector para o AppOne
- Adicionando entidades ao SAP Connector para o AppOne
- SAP Order to Cash Connector para AppOne
- SAP Purchase to Pay Connector para AppOne
- SAP Connector for Purchase to Pay Discovery Accelerator
- SAP Connector for Order-to-Cash Discovery Accelerator
- Superadmin
- Painéis e gráficos
- Tabelas e itens de tabela
- Integridade do aplicativo
- How to ....
- Como trabalhar com conectores SQL
- Introduction to SQL connectors
- Setting up a SQL connector
- CData Sync extractions
- Running a SQL connector
- Editing transformations
- Lançamento de um conector SQL
- Scheduling data extraction
- Estrutura das transformações
- Using SQL connectors for released apps
- Generating a cache with scripts
- Setting up a local test environment
- Separate development and production environments
- Recursos úteis
Conectores SQL incluídos com aplicativos independentes do Process Mining lançados, como TemplateOne e aceleradores de descoberta, e pré-requisitos para usá-los em desenvolvimento.
Introdução
Se um conector SQL estiver disponível para um aplicativo do Process Mining existente, por exemplo, TemplateOne ou um Acelerador de Descoberta, o conector SQL será incluído no aplicativo lançado.
Pré-requisitos
É assumido que:
- as ferramentas de desenvolvimento descritas em Configuração de um ambiente de teste local estão instaladas.
- você tem um repositório Git para controle de versão do conector. Consulte Usando um Repositório Git. Para o desenvolvimento de painéis e a criação de versões de aplicativos, você também precisa ter uma instalação do UiPath Process Mining com acesso ao repositório Git.
Aplicativo lançado
Para um aplicativo liberado com um conector SQL, todas as transformações são agrupadas e fazem parte do conector SQL. O conector SQL junto com os painéis do aplicativo formam o aplicativo. Consulte a ilustração abaixo para obter uma visão geral da estrutura do aplicativo.
Um aplicativo liberado contém as definições de painéis e cobre todas as etapas para exibir os dados nos painéis. A primeira etapa é extrair os dados do sistema de origem e carregá-los em um banco de dados SQL Server. A próxima etapa é transformar os dados brutos em um formato esperado pelos painéis usando transformações SQL. Finalmente, os dados são carregados nos painéis. Veja a ilustração abaixo para uma visão geral.
Configurando o aplicativo para desenvolvimento
Se você deseja personalizar o conector SQL ou os painéis do aplicativo, deve configurar o aplicativo para desenvolvimento.
Siga estas etapas para configurar o aplicativo para desenvolvimento.
| Etapa | Ação |
|---|---|
| 1 | Carregue a versão (.mvtag) para a guia Versões. |
| 2 | Crie um novo aplicativo e use o aplicativo lançado como o aplicativo base. Consulte Criação de Apps. Certifique-se de selecionar o repositório Git que você criou para o aplicativo. |
| 3 | Vá para o repositório do Git e crie uma verificação local da ramificação que contém o aplicativo. Isso permite que você trabalhe no conteúdo do aplicativo fora do Process Mining. É recomendável usar um cliente do Git GUI. Por exemplo, GitKraken ou GitHub Desktop. |
Conteúdo do lançamento
O checkout local contém vários arquivos e pastas. Veja a ilustração abaixo.
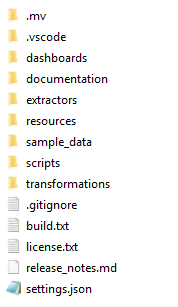
Abaixo está uma visão geral dos principais conteúdos do lançamento.
| Folder | Contém |
|---|---|
.mv | Pasta contendo as informações do build do software Process Mining. |
.vscode | Configurações do espaço de trabalho relevantes ao trabalhar no Visual Studio Code. |
dashboards | O arquivo .mvp que contém as definições dos painéis. |
documentation | Documentação específica do sistema e do processo. Por exemplo, como configurar o conector SQL específico, uma explicação do processo e opções de design aplicáveis. |
extractors | Instruções para extrair dados e carregá-los no banco de dados. Por padrão, o CData Sync é usado para extrair dados. Será incluída uma extração carregar de arquivo , habilitando você a carregar arquivos de dados brutos que sejam compatíveis com a entrada do conector. Além disso, será incluída uma extração de carga da origem . |
resources | Pasta contendo arquivos de tradução e configurações do painel. |
sample_data | .csv .zip no formato de dados extraídos que você pode usar como um conjunto de dados de amostra caso não tenha uma conexão com o sistema de origem. Esses dados amostrais se encaixam na entrada do conector, permitindo que você valide sua configuração de desenvolvimento e também visualize o aplicativo lançado. |
scripts | Scripts para extrair, transformar e carregar automaticamente os dados, que você pode agendar em seu ambiente de produção. |
transformations | O projeto dbt que contém as instruções SQL para transformar os dados. |
.gitignore | Git arquivo específico que lista o conteúdo do aplicativo que deve ser ignorado no controle de versão. |
build.txt | Informações sobre o conector e a parte do painel que foram combinadas para criar este aplicativo. |
license.txt | Arquivo de licença padrão do produto UiPath Process Mining. |
release_notes.md | Notas de lançamento do aplicativo. |
settings.json | Configurações internas do aplicativo. O conteúdo deste arquivo não precisa ser atualizado. |
Consulte a ilustração abaixo para obter uma visão geral da configuração.
Agora você pode executar todas as etapas necessárias para personalizar as transformações e editar os painéis conforme desejado.
Consulte Personalização de um conector SQL.
Liberando o aplicativo
Execute as etapas a seguir no servidor Process Mining.
| Etapa | Ação |
|---|---|
| 1 | Criar uma versão. Consulte Criando Versões. Uma tag de versão é criada no repositório do Git. Esta versão deve ser instalada no servidor de produção. |
| 2 | Implantar a versão. Consulte Implantação de aplicativos e Aceleradores de Descoberta. |
| 3 | Configure a conexão com banco de dados. Por exemplo, no TemplateOne carregando o arquivo TemplateOne.settings.csv . |
Execute as etapas a seguir no servidor de produção para executar as transformações e carregar os dados.
| Etapa | Ação |
|---|---|
| 4 | Confira a versão lançada do aplicativo no servidor de produção. É recomendável usar um cliente do Git GUI. Por exemplo, GitKraken ou GitHub Desktop. |
| 5 | Configurar o projeto dbt e os perfis. |
| 6 | Configure os scripts. |