- Notas de versão
- Introdução
- Instalação
- Requisitos de hardware e software
- Instalação do servidor
- Atualizando a Licença
- Implantando o Profiler do UiPath Process Mining
- Implantando um conector (.mvp)
- Atualizando o UiPath Process Mining
- Atualizando uma versão personalizada de um aplicativo ou acelerador de descoberta
- Instalando um Ambiente de Treinamento
- Configuração
- Integrações
- Autenticação
- Working with Apps and Discovery Accelerators
- Menus e painéis do AppOne
- Configuração do AppOne
- Menus e painéis do TemplateOne 1.0.0
- Configuração do TemplateOne 1.0.0
- TemplateOne menus and dashboards
- Configuração do TemplateOne 2021.4.0
- Menus e painéis do Acelerador de Descoberta Purchase to Pay
- Configuração do acelerador Discovery de compra para pagamento
- Menus e painéis do Acelerador de Descoberta Order a Cash
- Order to Cash Discovery Accelerator Setup
- Basic Connector for AppOne
- Implantar o Conector Básico
- Introduction to Basic Connector
- Tabelas de entrada do Conector Básico
- Adicionando tags
- Adição de estimativas de automação
- Adicionando Datas de conclusão
- Adicionando modelos de referência
- Setting up Actionable Insights
- Configuração de gráficos recolhíveis
- Usando o conjunto de dados de saída no AppOne
- Output tables of the Basic Connector
- SAP Connectors
- Introduction to SAP Connector
- Entrada do SAP
- Verificando os dados no SAP Connector
- Adicionando tags específicas do processo ao SAP Connector para o AppOne
- Adição de datas de vencimento específicas do processo ao SAP Connector para o AppOne
- Adicionando estimativas de automação ao SAP Connector para o AppOne
- Adicionando atributos ao SAP Connector para o AppOne
- Adicionando atividades ao SAP Connector para o AppOne
- Adicionando entidades ao SAP Connector para o AppOne
- SAP Order to Cash Connector para AppOne
- SAP Purchase to Pay Connector para AppOne
- SAP Connector for Purchase to Pay Discovery Accelerator
- SAP Connector for Order-to-Cash Discovery Accelerator
- Superadmin
- Painéis e gráficos
- Tabelas e itens de tabela
- Integridade do aplicativo
- How to ....
- Como trabalhar com conectores SQL
- Introduction to SQL connectors
- Setting up a SQL connector
- CData Sync extractions
- Running a SQL connector
- Editing transformations
- Lançamento de um conector SQL
- Scheduling data extraction
- Estrutura das transformações
- Using SQL connectors for released apps
- Generating a cache with scripts
- Setting up a local test environment
- Separate development and production environments
- Recursos úteis
Guia do usuário do Process Mining
Geral
Código do aplicativo
P: Onde posso encontrar o código do aplicativo?
R: você pode encontrar o código do aplicativo (às vezes também chamado de código do módulo) em um aplicativo lançado ou no seu ambiente de desenvolvimento.
-
Siga estas etapas para encontrar o código do aplicativo em um aplicativo lançado.
Etapa Ação 1 Abra o aplicativo lançado no navegador da web. 2 Localize o URL na barra de endereços. O código do aplicativo é a parte após o module=option. Veja a ilustração abaixo para um exemplo.
No exemplo acima, o código do aplicativo é ProcessMining, enquanto o nome do módulo é Process Mining. O nome do módulo não é visível no link; no entanto, você pode encontrá-lo na guia Superadmin Os dados liberados. 2. Siga estas etapas para encontrar o código do aplicativo em seu ambiente de desenvolvimento. Na caixa de diálogo Módulos , você pode adicionar novos módulos. Você também pode alterar o nome e a descrição dos módulos existentes. Siga estas etapas para exibir a caixa de diálogo Módulos .
| Etapa | Ação |
|---|---|
| 1 | Clique no ícone Início em seu ambiente de desenvolvimento de aplicativos. |
| 2 | Selecionar Módulos.... |
A caixa de diálogo Módulos é exibida. Veja a ilustração abaixo.
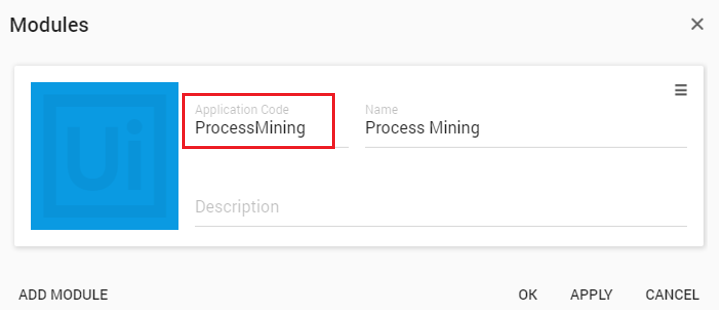
Tipos de arquivo de aplicativo
P: Qual é a diferença entre os arquivos .mvp e .mvtag ?
A: abaixo está uma descrição dos diferentes tipos de arquivos.
| Tipo de arquivo | Description |
|---|---|
.mvp | Formato de arquivo editável para conectores, aplicativos e aceleradores de descoberta. Os arquivos .mvp podem ser editados em um ambiente de desenvolvimento do Process Mining para criar novas versões (personalizadas) do conector, aplicativo ou acelerador de descobertas. Consulte A Aba Espaços de Trabalho. |
.mvtag | Formato de arquivo usado para uma versão lançada de um conector, aplicativo ou acelerador de descoberta. Arquivos .mvtag são criados ao lançar uma nova versão do conector, aplicativo ou acelerador de descoberta e não podem ser editados. Consulte a guia Versões. |
Carregamento de Dados
Dados ao vivo
P: A plataforma suporta dados em tempo real?
R: o UiPath Process Mining pode ler dados no momento em que o aplicativo é aberto por um usuário final por meio de tabelas ao vivo. Além disso, os dados podem ser lidos quando uma ação é disparada. No entanto, há vários pontos a serem considerados:
- Com o carregamento de dados em tempo real, existem muitas dependências que podem afetar o desempenho do usuário final (abertura dos painéis, mas também o cálculo dos painéis), pois os dados não são pré-armazenados em cache.
- Haverá uma carga no sistema de produção cada vez que o usuário abrir o aplicativo.
- Os usuários finais podem ver resultados diferentes dependendo do horário em que executaram o relatório.
Para evitar esses problemas, é possível adotar uma abordagem de tempo próximo, o que pode significar um intervalo de uma vez por hora. No entanto, vemos que o cliente escolhe principalmente por um intervalo diário.
Recomendamos o uso de dados ao vivo apenas quando isso for absolutamente necessário.
Qualquer tabela de dados ao vivo desabilita a plataforma para usar cache nesta tabela e em qualquer tabela dependente desta. Isso afetará significativamente o desempenho do aplicativo.
Além disso, as consultas de dados ao vivo serão executadas no banco de dados quando um usuário final fizer login no aplicativo. Dependendo da consulta e do número de usuários finais, isso pode sobrecarregar muito o banco de dados.
Carregamento de Dados Incrementais
P: a plataforma é compatível com carregamento de dados incremental?
R: Não, o UiPath Process Mining não é compatível com carga de dados incremental. Consulte Carregamento de dados: carga incremental
Intervalo de atualização dos dados
P: com que frequência o UiPath Process Mining atualiza os dados?
R: Isso depende das necessidades de negócios e da frequência com que novos dados ficam disponíveis no sistema de origem. A escolha é entre os insights desejados e a carga no sistema de produção.
Para alguns casos de uso, os dados são atualizados durante a noite, para minimizar o impacto no sistema de produção e garantir que todos os usuários vejam os mesmos resultados durante o dia. Porém, algumas organizações optam por um prazo maior, pois desejam que os dados permaneçam constantes por um mês para fazer uma análise minuciosa.
Limites de tamanho de arquivo
P: Há um limite de tamanho para arquivos de origem de dados?
R: o tamanho máximo de um arquivo em um espaço de trabalho é de 10 MB. Tamanhos de arquivo maiores são compatíveis apenas fora do escopo do espaço de trabalho e, portanto, não são confirmados no Git. Em Avançado -> Opções de tabela, o Escopo da tabela é definido como Servidor. Você pode usar a configuração ServerScopePath nas Configurações do servidor para especificar o caminho relativo para o arquivo de origem de dados.
Arquivamento de Dados
P: o UiPath Process Mining suporta o arquivamento de dados?
R: Com nosso sistema de gerenciamento de versões, sempre podemos reverter para as versões anteriores. O número de versões mais antigas a serem mantidas pode ser configurado por sua organização. Isso pode ser necessário se ocorrer algum problema de dados. No entanto, o UiPath Process Mining não deve ser o armazenamento de dados primário, usado para arquivamento de dados. Para a retenção de dados a longo prazo, você deve usar outros sistemas.
Tipos de arquivos de entrada
P: Que tipos de arquivos de entrada são suportados?
R: a plataforma UiPath Process Mining é compatível com arquivos de texto como.txt,.csv,.tsv para os quais o delimitador e as aspas podem ser selecionados. Arquivos de texto ASCII são compatíveis na codificação Latin-1 (ISO-8859-1), e arquivos UTF-8 são compatíveis com e sem BOM.
A plataforma UiPath Process Mining também é compatível com arquivos do Excel, tanto arquivos .XLSX quanto arquivos .XLS podem ser importados. É possível especificar a planilha ou o intervalo no arquivo. Para planilhas, uma detecção automática é executada para o intervalo de dados real, ou se a detecção automática falhar, o intervalo precisa ser especificado no Excel e depois usado. O Unicode dentro do Excel é totalmente suportado.
Ficheiros de Entrada XES
P: A plataforma é compatível com arquivos de entrada XES?
R: Sim, o UiPath Process Mining é uma plataforma de suporte oficialmente certificada para XES. Se o XES for necessário, um script de dados que pode ser usado para ler arquivos XES está disponível.
Segurança
Proteger dados importados
P: Como podemos garantir que os dados importados estejam protegidos contra manipulação não autorizada?
R: a plataforma UiPath Process Mining é testada regularmente quanto à segurança (com ferramentas como Owasp ZAP, OpenVAS etc.). Para aumentar a segurança, sempre recomendamos o uso de túnels VPN para limitar o acesso à plataforma. As análises de risco são realizadas regularmente para garantir que a segurança esteja sempre atualizada, usamos o Guia de Testes OWASP 4. Fora da plataforma UiPath Process Mining , a segurança também depende de quão seguro é o próprio servidor. A segurança do próprio servidor é de responsabilidade da parte que hospeda.
Proteção de dados
P: Quando o UiPath Process Mining processa os dados, os dados são armazenados em um local seguro ou criptografados para protegê-los contra conhecimento não autorizado?
R: após os dados serem processados pelo UiPath Process Mining, os dados são armazenados em um formato de arquivo proprietário. Esses arquivos são criptografados e só podem ser lidos pelo software UiPath Process Mining . Na própria plataforma, o acesso a determinados dados pode ser restrito por usuário, ou seja permita que os usuários vejam apenas dados que eles têm permissão para ver.
Isso se aplica apenas a usuários finais. Os desenvolvedores têm acesso irrestrito aos dados.
Proteção de arquivo de registro
P: como os arquivos de log são protegidos contra modificação ou exclusão não autorizada?
(É fornecido um buffer suficientemente grande para os dados de log e é possível configurar uma mensagem de aviso se a capacidade de armazenamento estiver baixa/esgotada?)
R: o UiPath Process Mining não oferece nenhuma proteção contra a modificação de arquivos no disco. Se uma pessoa tiver acesso ao próprio servidor, ela poderá modificar os arquivos de log no disco. O monitoramento do servidor é de responsabilidade da parte de hospedagem.
Algoritmo de criptografia
P: Quais algoritmos e força de criptografia específicos são usados para criptografar dados em repouso?
R: a plataforma UiPath Process Mining não criptografa dados prontos para uso. A criptografia do disco de dados é de responsabilidade da parte de hospedagem. É recomendável usar o BitLocker.
Armazenamento de senha
P: como as senhas dos usuários são armazenadas?
R: o campo Senha é criptografado usando uma função hash. Usa-se PBKDF2 com HMAC-SHA512 como função pseudoaleatória e 10.000 iterações, juntamente com um salt.
Um salt é usado para estender a entrada da função hash. O sal consiste em uma parte fixa (específica do aplicativo) e um sal de 128 bits gerado aleatoriamente que é armazenado no banco de dados. A semente aleatória é gerada na inicialização do aplicativo em uma sessão.
Como uma função hash criptográfica é usada, uma chave de criptografia não é necessária. Nenhum vetor de inicialização é usado na função hash.
Verificando uma compilação assinada
P: Como posso verificar se o arquivo de compilação é assinado pela UiPath?
R: o SignTool pode ser usado para verificar se o arquivo de compilação é assinado pela UiPath.
Siga estas etapas para verificar o arquivo <build>.exe baixado, por exemplo UiPathProcessMining-21.4.exe usando SignTool.
| Etapa | Ação |
|---|---|
| 1 | Baixe e instale o SignTool . |
| 2 | Abrir um Prompt de comando. |
| 3 | Execute o seguinte comando: SignTool verify /pa /v <path to build> . |
| 4 | Verifique a saída. Certifique-se de que:
|
Consulte a ilustração abaixo para obter um exemplo de saída.
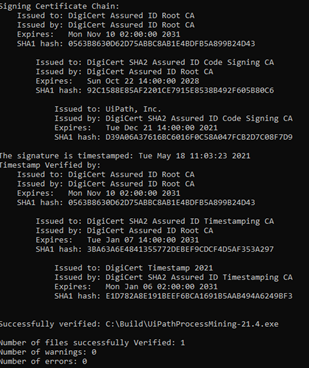
Para obter mais informações, consulte a documentação da Microsoft no SignTool.
Acesso do usuário
Contas de usuário nomeado
P: É possível combinar usuários do AD com contas de usuários nomeados?
R: É possível adicionar contas de usuário nomeadas ao lado de usando LDAP. Essas contas de usuário também podem ser restritas a determinados endereços IP. Também é possível habilitar a autenticação de dois fatores (TOTP) para essas contas.
Número da porta LDAP
P: É possível definir um número de porta diferente para LDAP?
R: Por padrão, a plataforma usa o número da porta LDAP padrão. É possível usar um número de porta diferente. Você pode especificar o número da porta, por exemplo porta 123, na URL da seguinte forma:
ldap": {
"url": "ldap://PROCESSMININGTEST.pmtest.local:123",
"base": "DC=pmtest,DC=local",
"bindDN": "PMTEST\\testuser",
"bindCredentials": "Passw0rd!",
}
ldap": {
"url": "ldap://PROCESSMININGTEST.pmtest.local:123",
"base": "DC=pmtest,DC=local",
"bindDN": "PMTEST\\testuser",
"bindCredentials": "Passw0rd!",
}
Proteção de Força Bruta
P: O UiPath Process Mining fornece uma proteção de força bruta?
R: Sim, o UiPath Process Mining limita o número de tentativas de login.
Acesso do usuário final
P: como posso disponibilizar a plataforma UiPath Process Mining aos usuários?
R: Para disponibilizar a plataforma para usuários pela internet, é preciso disponibilizar o site em IIS. Consulte seu departamento de TI para obter ajuda com isso. As seguintes etapas precisam ser realizadas:
- Crie um nome de (sub)domínio para o site.
- Obtenha um certificado SSL para esse nome de domínio e o instale no servidor do UiPath Process Mining. (Consulte a documentação do fornecedor de seu certificado SSL para obter informações sobre como solicitar e instalar um certificado SSL para sua versão específica do IIS.)
Observação:
O departamento de TI já pode ter certificados SSL curingas para o nome de domínio da sua empresa.
- Criar um vínculo HTTPS para o site no IIS. Para uma descrição detalhada de como criar uma associação SSL, visite a documentação oficial da Microsoft.
- Certifique-se de que sua rede esteja configurada corretamente:
- o nome de domínio aponta para o servidor do UiPath Process Mining;
- o tráfego HTTPS para o servidor do UiPath Process Mining e vindo dele está permitido.
Conexões do Banco de Dados
Database Connection
P: Como a conexão com o banco de dados pode ser configurada?
R: a plataforma UiPath Process Mining suporta o acesso a bancos de dados por ODBC. ODBC é a maneira padronizada de acessar bancos de dados no Windows e consiste em duas partes:
- um driver adequado para o banco de dados precisa ser instalado. A plataforma UiPath Process Mining está disponível apenas em 64 bits e requer um driver ODBC de 64 bits.
- um DSN (Nome da fonte de dados) precisa ser configurado para conter as informações sobre como acessar o banco de dados e fornecer um nome que o aplicativo pode usar para acessar o banco de dados. O DSN precisa ser um DSN do sistema ou criado para o usuário que é usado para executar a plataforma.
Observação:
JDBC e ODBC são padrões diferentes. A maioria dos bancos de dados tem unidades JDBC e ODBC, mas a plataforma do UiPath Process Mining é compatível apenas com ODBC.
ODBC DSN
P: O ODBC DSN não pode ser usado a partir da plataforma. O que devo fazer?
Certifique -se de usar um driver ODBC de 64 bits e que o DSN seja um DSN do sistema ou configurado para o usuário correto.
Bancos de dados suportados
P: Quais bancos de dados são compatíveis?
R: Todos os bancos de dados que podem ser acessados por meio de um driver de 64 bits do ODBC podem ser usados.
Conector
Loop Recorrente
P: Após criar meu conector, o processo tem apenas atividades que fazem loop com ele mesmo. E o que isso quer dizer?
R: Se este for um resultado inesperado, você deve verificar os IDs do caso em seus arquivos de entrada. É possível que os IDs do caso não sejam exclusivos. Nesse caso, não é possível detectar qual é o ID de caso correto e todas as atividades com IDs de caso não exclusivos ocorrerão várias vezes.
- Geral
- Código do aplicativo
- Tipos de arquivo de aplicativo
- Carregamento de Dados
- Dados ao vivo
- Carregamento de Dados Incrementais
- Intervalo de atualização dos dados
- Limites de tamanho de arquivo
- Arquivamento de Dados
- Tipos de arquivos de entrada
- Ficheiros de Entrada XES
- Segurança
- Proteger dados importados
- Proteção de dados
- Proteção de arquivo de registro
- Algoritmo de criptografia
- Armazenamento de senha
- Verificando uma compilação assinada
- Acesso do usuário
- Contas de usuário nomeado
- Número da porta LDAP
- Proteção de Força Bruta
- Acesso do usuário final
- Conexões do Banco de Dados
- Database Connection
- ODBC DSN
- Bancos de dados suportados
- Conector
- Loop Recorrente