- Introdução
- Configurando sua conta
- Balanceamento
- Clusters
- Desvio de conceito
- Cobertura
- Conjuntos de dados
- Campos gerais
- Rótulos (previsões, níveis de confiança, hierarquia do rótulo e sentimento do rótulo)
- Modelos
- Transmissões
- Classificação do Modelo
- Projetos
- Precisão
- Lembrar
- Mensagens anotadas e não anotadas
- Campos de extração
- Fontes
- Taxonomias
- Treinamento
- Previsões positivos e negativos verdadeiros e falsos
- Validação
- Mensagens
- Controle de acesso e administração
- Gerencie origens e conjuntos de dados
- Entender a estrutura de dados e permissões
- Criando ou excluindo uma origem de dados na GUI
- Preparando dados para carregamento de .CSV
- Carregar um arquivo CSV para uma origem
- Criação de um conjunto de dados
- Origens e conjuntos de dados multilíngues
- Habilitando o sentimento em um conjunto de dados
- Como corrigir as configurações do conjunto de dados
- Excluindo uma mensagem
- Exclusão de um conjunto de dados
- Exportação de um conjunto de dados
- Usando integrações do Exchange
- Treinamento e manutenção do modelo
- Noções Básicas sobre rótulos, campos gerais e metadados
- Hierarquia de rótulos e práticas recomendadas
- Comparação de casos de uso de análise e automação
- Transformando seus objetivos em rótulos
- Visão geral do processo de treinamento do modelo
- Anotação generativa
- Status do conjunto de dados
- Treinamento de modelos e práticas recomendadas de anotação
- Treinamento com análise de sentimento de rótulo habilitada
- Compreensão dos requisitos de dados
- Treinamento
- Introdução ao Refine
- Precisão e recall explicados
- Precisão e recall
- Como a validação funciona
- Compreender e melhorar o desempenho do modelo
- Motivos para baixa precisão média do rótulo
- Treinamento usando Check label e Perda de rótulo
- Treinamento usando Ensinar rótulo (Refinar)
- Treinamento usando a Pesquisa (Refinamento)
- Noções Básicas e Aumentando a Cobertura
- Melhorando o balanceamento e usando o Rebalanceamento
- Quando parar de treinar seu modelo
- Uso dos campos gerais
- Extração generativa
- Uso de análise e monitoramento
- Automations e Communications Mining™
- Desenvolvedor
- Carregamento de dados
- Baixando dados
- Integração do Exchange com usuário do serviço do Azure
- Integração do Exchange com Autenticação de Aplicativo do Azure
- Integração do Exchange com Autenticação de aplicativo e gráfico do Azure
- Guia de migração: Exchange Web Services (EWS) para a API do Microsoft Graph
- Como buscar dados para o Tableau com o Python
- Integração do Elasticsearch
- Extração de campo geral
- Integração auto-hospedada do Exchange
- Framework de automação da UiPath®
- Atividades oficiais da UiPath®
- Como as máquinas aprendem a entender as palavras: um guia para incorporações ao NLP
- Aprendizado baseado em solicitação com Transformers
- Efficient Transformers II: extração de conhecimento e ajustes finos
- Transformers eficientes I: mecanismos de atenção
- Modelagem de intenção hierárquica profunda não supervisionada: obtenção de valor sem dados de treinamento
- Corrigindo viés de anotação com o Communications Mining™
- Aprendizado ativo: melhores modelos de ML em menos tempo
- Está tudo nos números - avaliando o desempenho do modelo com métricas
- Por que a validação de modelos é importante
- Comparação do Communications Mining™ e do Google AutoML para inteligência de dados de conversa
- Licenciamento
- Perguntas frequentes e mais

Guia do usuário do Communications Mining
Framework de automação da UiPath®
O conteúdo das atividades foi realocado para o guia Atividades do Communications Mining™ .
Visão geral
A Estrutura do dispatcher do Communications Mining™ é um modelo do UiPath® Studio que você pode usar ao integrar o Communications Mining com implementações de RPA. Seu objetivo é pegar os comentários de um stream do Communications Mining e adicioná-los um por um, em uma ou várias filas de referências exclusivas do UiPath Orchestrator. Você deve definir uma fila para cada processo downstream que precisa dos dados de um stream como entrada. Por padrão, no arquivo de configuração, configuramos duas filas de processos (para os Processos A e B) e uma genérica, mas você pode configurar quantas forem necessárias.
Você pode obter a estrutura do Studio, em Modelos, procurando por Communications Mining Dispatcher.
Ao criar suas filas, selecione a opção Impor referências exclusivas .
O modelo é baseado na Estrutura Empresarial Robótica (REFramework), abrangendo todas as práticas recomendadas essenciais em projetos de RPA, como a configuração flexível por meio do arquivo Config.xlsx, tratamento de exceções, mecanismos de repetição e registros em log significativos.
Antes de trabalhar com o dispatcher do Communications Mining, certifique-se de consultar a documentação oficial do REFramework, se você não estiver familiarizado com ela.
Começando de um projeto REFramework, encapsulamos as duas operações principais que precisam ser realizadas ao consumir dados de um fluxo do Communications Mining: busca e progresso. Buscar é o processo de obter dados de um fluxo do Communications Mining e avançar é basicamente marcar os comentários como lidos, para que não retornemos os mesmos da próxima vez que buscarmos. Vamos discuti-los com mais detalhes na próxima seção.
Por padrão, a estrutura interromperá o ciclo de buscar e avançar quando passar do fim do stream, ou seja, quando o stream não tiver mais comentários não lidos. No entanto, você pode configurar a estrutura para ser executada continuamente, mesmo quando atingir o fim do fluxo. Para fazer isso, você pode marcar a configuração ExitOnEmptyStream como False no arquivo Config.xlsx. Essa configuração permite que a estrutura ciclo infinitamente e, sempre que novos dados estiverem disponíveis no stream, ele será processado instantaneamente, sem a necessidade de esperar para quando o processo da estrutura estiver agendado para ser executado.
O objetivo final é ter os comentários disponíveis em uma fila do Orchestrator utilizável, um item de fila por comentário, contendo seus dados correspondentes e rótulos previstos e campos gerais. Dessa forma, as automações downstream terão acesso às informações previstas.
A comunicação não é adicionada à sua fila correspondente sem passar nas regras de validação. Existem algumas regras básicas de validação já definidas na estrutura - principalmente para entender a qual processo cada item pertence - mas você pode adicionar seus próprios algoritmos de validação no código. Além disso, como exemplo, no arquivo Config.xlsx, temos planilhas de configurações de validação separadas para cada processo de automação downstream, ou seja, ProcessAValidations e ProcessBValidations. Como eles foram configurados apenas como exemplos para processos teóricos, fique à vontade para adicionar suas próprias planilhas e configurações.
-
Certifique-se de não ter várias configurações com o mesmo nome no arquivo de Configuração, mesmo que elas estejam em planilhas diferentes. Todos serão adicionados ao mesmo dicionário de configuração e substituirão entre si. No arquivo, oferecemos alguns exemplos de convenções de nomenclatura para as configurações de validação que podem ser úteis. A lógica no fluxo de trabalho que verifica as regras de validação segue as mesmas convenções; portanto, tenha cuidado ao implementar as suas próprias, caso queira alterá-las. Se a validação falhar, as informações são adicionadas a uma fila de humanos no loop, que também requer referências exclusivas para humanos validarem no Action Center. Você pode adicionar o nome da sua fila com influência humana no loop no arquivo de Configuração. config, mesmo que estejam em planilhas diferentes. Todos serão adicionados ao mesmo dicionário de configuração e substituirão entre si.
No arquivo, oferecemos alguns exemplos de convenções de nomenclatura para as configurações de validação que podem ser úteis. A lógica no fluxo de trabalho que verifica as regras de validação segue as mesmas convenções; portanto, tenha cuidado ao implementar as suas próprias, caso queira alterá-las.
Se a validação falhar, as informações são adicionadas a uma fila de humanos no loop, que também requer referências exclusivas para humanos validarem no Action Center. Você pode adicionar o nome da sua fila com influência humana no loop no arquivo de Configuração.
-
É recomendável definir um gatilho na fila com influência humana no loop, o que inicia um novo Processo de Orquestração para cada novo item, criando uma tarefa no Action Center. A tarefa conteria os dados recuperados do Communication Mining para o item atual, e o humano deve validá-lo antes de enviá-lo para sua fila de processo de automação downstream correspondente.
Transmissões
Depois de treinar com sucesso um modelo no Communications Mining™, podemos criar um novo fluxo e configurar os limites para cada um dos conceitos que treinamos. Um stream define uma coleção de comentários em um conjunto de dados. Ele permite a iteração persistente e com estado por meio dos comentários, com rótulos previstos e campos gerais calculados usando uma determinada versão do modelo.
Recomendamos que você siga a Documentação e a Academia oficiais do Communications Mining para obter as etapas de treinamento do modelo e detalhes sobre todos os conceitos envolvidos.
A integração do UiPath® Studio com o Communications Mining consiste no consumo de cada um dos comentários do stream do Communications Mining. Cada uma das previsões da comunicação pode ser usada em um ou vários processos downstream. No diagrama abaixo, a integração genérica do UiPath e do Communications Mining é descrita:
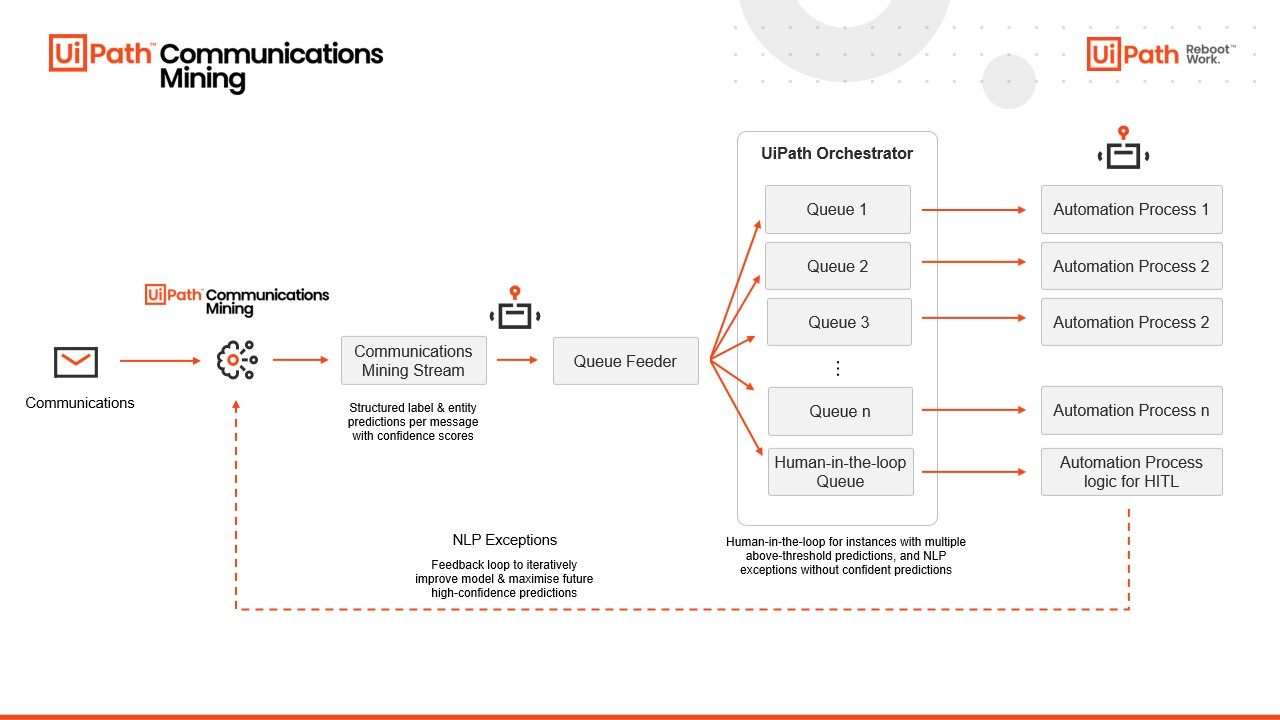
Nossa abordagem recomenda que, para n automações, n + 1 processos sejam configurados no UiPath: n processos de RPA e um Feeder de filas. Um único processo de feeder é introduzido que é responsável por ler as comunicações estruturadas de um stream do Communications Mining e distribuí-las para os processos de RPA relevantes por meio de filas do Orchestrator. Quaisquer exceções que possam ocorrer devido à extração do Communications Mining podem ser marcadas para Validação Humana manual. Os processos que obtém itens das filas serão automações UiPath padrão que leem seus dados de entrada dos dados do item de fila. A estrutura do dispatcher fornecida preenche a função do feed da fila.
Loop de busca avançada
Para consumir comentários de um stream, nossa estrutura precisa implementar o Loop Fetch e Advance, que é descrito da seguinte forma:
-
Todo fluxo tem um comentário atual:
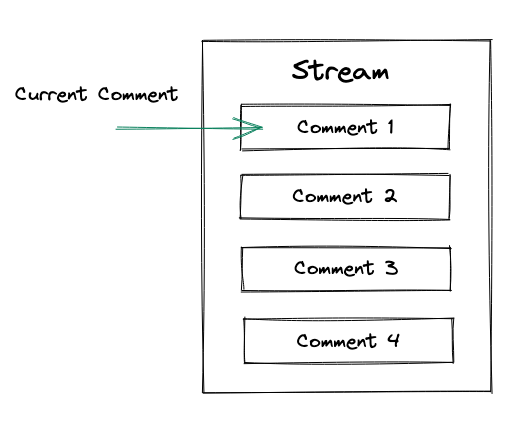
-
É possível buscar comentários a partir deste comentário atual. Na imagem a seguir, estamos buscando dois comentários:
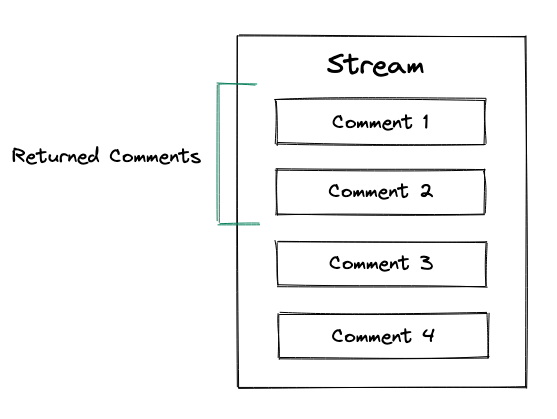
-
Cada comentário retornado de um fluxo terá um
sequence_id:{ "comment":{ "messages":[ ... ], "user_properties":{ ... }, "id":"comment 1" }, "entities":[ ... ], "labels":[ ... ], "sequence_id":"ABC123" }{ "comment":{ "messages":[ ... ], "user_properties":{ ... }, "id":"comment 1" }, "entities":[ ... ], "labels":[ ... ], "sequence_id":"ABC123" } -
Podemos usar esse
sequence_idpara avançar o comentário atual para o próximo na fila. Agora, ao buscarmos o 2, retornaremos os comentários 2 e 3: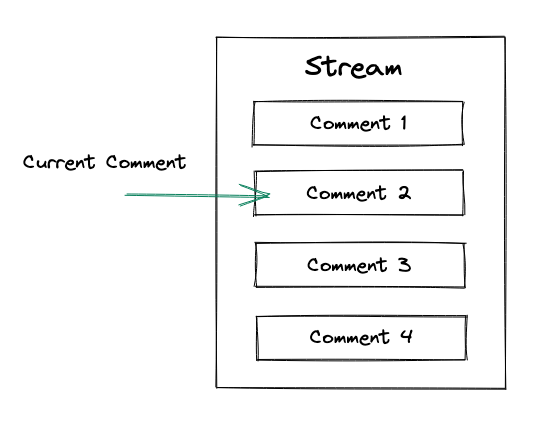
A Estrutura do Communications Mining implementa esse loop de buscar e avançar para você.
Visão geral da estrutura Dispatcher
Basta modificar as configurações necessárias para configurar a estrutura do dispatcher para consumir comentários do seu próprio fluxo, economizando tempo de implementação e garantindo que as melhores práticas sejam seguidas.
Assim como o REFramework, ele pode ser usado exatamente como está, como uma solução Plug and Play, pois sem qualquer modificação no código (apenas adicionando suas configurações no arquivo Configuração do Excel), ele obtém cada um dos comentários do arquivo definido stream (como objetos do tipo CommunicationsMining.Result, definido no pacote CommunicationsMining (verifique a seção Dependências), e adiciona seus dados em uma Fila correspondente. Como alternativa, pode ser completamente personalizada, e você pode adicionar sua própria lógica conforme necessário (as regras para validar as previsões do Communications Mining™, por exemplo).
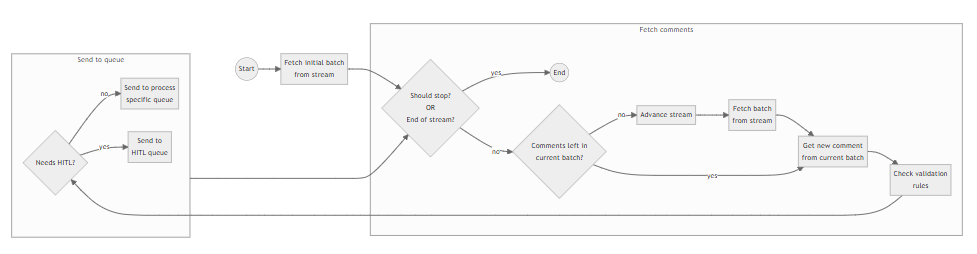
A estrutura do dispatcher do Communications Mining usa a abordagem Fetch e Advanced Loop conforme descrito anteriormente, e podemos avançar um comentário de cada vez ou um lote de comentários de cada vez (podemos configurar o tamanho do lote no arquivo de Configuração). Lembre-se que o Dispatcher é usado como feeder para um ou vários processos downstream, portanto, no arquivo Config também definimos a fila correspondente para cada um desses processos e as regras para adicionar o item à fila.
As etapas gerais são as seguintes:
- Buscamos um lote inicial de comentários. Isso retornará um lote de comentários do fluxo do Communications Mining, o
sequence_iddo último item do lote e o número de itens filtrados do lote atual. - Se nenhuma exceção ocorrer (conectados com sucesso ao fluxo) e não estivermos no final do fluxo, verificamos se há itens restantes para processar no lote atual. Podemos até buscar lotes sem comentários, se houver filtros aplicados no Communications Mining para o fluxo atual e nenhum dos comentários no lote atual se aplica).
- Se houver itens a serem processados, nós os processamos um por um: dependendo do processo de RPA do consumidor ao qual o item atual pertence, verificamos as regras de validação dos dados do item.
- Se o item for aprovado nas verificações, adicionamos um novo item de fila à fila relevante (conforme definido no arquivo de configuração do Excel). O uid do comentário será definido como a referência do item da fila. Se ele não for aprovado nas regras de validação, adicionamos um item de fila à fila Meta. Cada item de fila que é criado conterá todos as previsões de campo geral e rótulo do comentário para uso em processos downstream.
- Após cada item do lote atual ser processado, primeiro avançamos o fluxo (usando o
sequence_iddo último item do lote) e, depois, buscamos um novo lote no fluxo. - Se estivermos no final do fluxo (como não recuperamos nenhum comentário no lote e não há comentários filtrados), saberemos que avançamos além do final do fluxo e o processamento termina.
Configuração
Todas as configurações necessárias para configurar o Dispatcher são encontradas no arquivo Data/Config.xlsx.
Certifique-se de adicionar todos os ativos correspondentes ao Orchestrator.
As configurações e planilhas de ativos
| Nome | Descrição |
|---|---|
| OrchestratorProcessAQueueName | Esta é a Fila para a qual nosso Dispatcher enviará comentários VÁLIDOS para serem processados pelo Processo A do Consumidor de RPA. |
| OrchestratorProcessBQueueName | Esta é a Fila para a qual nosso Dispatcher enviará comentários VÁLIDOS para serem processados pelo Processo B do Consumidor de RPA. |
| OrchestratorHITLQueueNameA | Esta é a Fila para a qual nosso Dispatcher enviará comentários que não passaram nas Regras de validação definidas para seu Processo correspondente. A HITLQueue será processada pelo Human In The Loop, Processo de Orquestração que cria Ações de Validação para cada um dos itens da fila adicionados. |
| OrchestratorGeneralQueueName | Esta é a Fila para a qual nosso Dispatcher enviará comentários que não foram categorizados para um Processo de Consumo de RPA específico. |
| Communications MiningApiTokenCredential | O token de API do Communications Mining™ necessário para buscar no stream e avançar dentro do stream, armazenado em um Ativo de credenciais. |
| ExitOnEmptyStream | Se essa configuração for False, o framework será executado continuamente, mesmo quando atingirmos o fim do fluxo. |
Cada uma das Planilhas de validação de processo
| Nome | Descrição |
|---|---|
| {ProcessName}_Label | A convenção de nomenclatura da configuração é o rótulo que marca um comentário como sendo designado para ser processado pelo processo atual + "_"+ palavra-chave "Label". O valor dele é o nome do processo downstream. Exemplo: Nome Policy_Label, Valor ProcessA. |
Como o Dispatcher pode preencher filas de entrada para um ou mais processos downstream, sugerimos que você crie uma nova planilha no arquivo de configuração para cada um dos processos, na qual você definirá as regras de validação para cada processo. A convenção de nomenclatura da Planilha deve ser: "{ProcessName}Validations". Por padrão, o arquivo de configuração contém 2 planilhas de validação para o processo A e o processo B.
Manuseio de exceção
A Estrutura coleta todas as exceções que ocorrem durante o processamento de cada um dos itens de transação (comentários do Communications Mining™) em duas TabelasDeDados: uma para Exceções do sistema e outra para Exceções de regras de negócios.
Em Estado do processo final, você pode usar as tabelas para lidar com as exceções de acordo com sua lógica de negócios (criar arquivos do Excel com elas, enviá-las anexadas a um e-mail de relatório, etc).
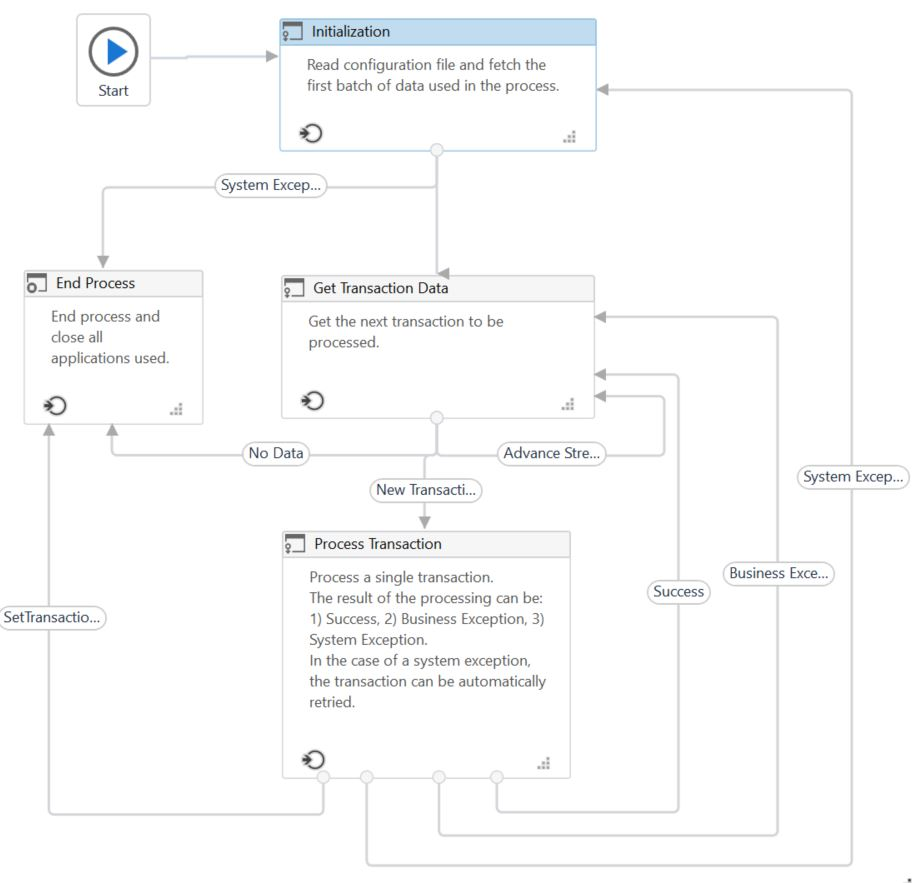
Arquitetura
Dependências
Criamos Atividades personalizadas que lidam com as principais operações que podem ser realizadas a partir do UiPath® para se integrar ao Communications Mining™: Fetch Stream, Advance Stream. Além disso, as Transações do framework são do tipo CommunicationsMining.Result, um tipo de dados definido no pacote que manterá todas as informações definidas para cada comentário e seus rótulos previstos e campos gerais correspondentes.
Você precisa ter o pacote CommunicationsMining em um dos seus feeds para que a Estrutura do dispatcher seja carregada corretamente, baixado do Marketplace: aqui.
Estados
Como o Framework é basicamente um REFramework, ele é uma Máquina de estado com os mesmos estados. Consulte a documentação do REFramework para obter mais detalhes sobre cada estado.
A única modificação é a adição da Transição de Fluxo Avançado entre o Estado de Dados da Transação GET e o Estado de Transação de Processo. Caso não haja itens a serem processados no lote atual buscado, a execução retorna ao estado GetTransactionData para progresso no fluxo.
Variáveis compartilhadas
As variáveis abaixo são declaradas no arquivo Main.xaml e compartilhadas como argumentos para os fluxos de trabalho invocados na Estrutura, ou elas simplesmente decidem o fluxo de execução pela estrutura:
| Nome da variável | Descrição |
|---|---|
| ShouldStop(Boolean) | Verdadeiro quando o trabalho é interrompido à força (a partir do Orchestrator). |
| TransactionItem(CommunicationsMining.Result) | O Item de Transação é representado por um comentário do fluxo do Communications Mining. Estamos processando um item de cada vez e adicionando seus dados à fila correspondente. |
| SystemException(Exception) | Usado durante transições entre estados para representar outras exceções que não exceções de negócios. |
| BusinessException(BusinessRuleException) | Usado durante as transições entre estados e representa uma situação que não está em conformidade com as regras do processo automatizado. |
| TransactionNumber(Int32) | Contador sequencial de itens de transação. |
| Config(Dictionary(String,Object)) | Dictionary structure to store configuration data of the process (settings, constants, assets and Validation properties). |
| RetryNumber(Int32) | Usado para controlar o número de tentativas de novo processamento da transação em caso de exceções do sistema. |
| TransactionData(IList(CommunicationsMining.Result)) | O lote de comentários atualmente recuperados do fluxo, pela última Busca. |
| ConsecutiveSystemExceptions(Int32) | Usado para controlar o número de exceções do sistema consecutivas. |
| BusinessExceptionsDT(DataTable) | Tabela com detalhes sobre BusinessRulesExceptions ocorridas durante o processamento das Transactions. Uma linha contém informações sobre uma transação com falha. |
| ApplicationExceptionsDT(DataTable) | Table with details on the System Exceptions occurred during the processing of the Transactions. One row contains info about one faulty transaction |
| GlobalRetryInterval(TimeSpan) | O intervalo de tentativa global definido por padrão para cada Escopo de Tentativa no Framework. |
| GlobalMaxAttempts(Int32) | The global number of Max Attempts set by default for every Retry Scope in the Framework. |
| CurrentSequenceId(String) | O ID de sequência recuperado pela Busca mais recente de um Lote de stream. É o ID de sequência do último item no lote de fluxo atual. |
| CurrentBatchFilteredResults(Int32) | O número de itens que não se encaixam no filtro que foi definido para o fluxo no Communication Mining e foram filtrados pela última Busca (filtrados do Lote coletado atual). |
| CommunicationsMiningApiToken(SecureString) | O token da API definido no Communications Mining. Seu valor deve ser armazenado em um Ativo de Credencial no Orchestrator. |
| CurrentBatchNumber(Int32) | É uma boa prática dividir sua transmissão em vários lotes (para ajudar no tempo de desempenho de recuperação dos dados). Isso nos dirá o lote atual que está sendo processado. |
| ShouldAdvanceTheStream(Boolean) | Caso não haja itens a processar no lote atual buscado, a execução retorna ao estado GetTransactionData para maior progresso no fluxo. |
Fluxos de trabalho específicos do Communications Mining™
| Nome do fluxo de trabalho | Descrição |
|---|---|
| GetNextStreamBatch | Estamos tentando obter o próximo lote de fluxo dos comentários do Communications Mining™. A atividade Fetch Stream se conectará ao Communications Mining e preencherá o objeto de saída Fetch com: a coleção de resultados (do tamanho que solicitamos) - o ID da Sequência do lote atual (o ID da Sequência do último comentário no lote recuperado )- o número de comentários filtrados (caso apliquemos filtros em nosso stream do Communications Mining, os comentários que não corresponderem ao filtro serão ignorados) A atividade Fetch executa uma solicitação HTTPs para o Communications Mining. |
| AdvanceStreamBatch | Estamos tentando avançar o fluxo de comentários do CommunicationsMining. A atividade Advanced Stream se conectará ao CommunicationsMining e, usando como entrada o ID de Sequência de um dos comentários no fluxo, marcará os comentários (anterior e incluindo aquele com o ID de Sequência fornecido) como lidos no fluxo para que não retornamos os mesmos da próxima vez que buscarmos em um fluxo. Se você buscar várias vezes consecutivas sem avançar um fluxo, você receberá os mesmos e-mails todas as vezes.A atividade Advanced executa uma solicitação HTTPs para o CommunicationsMining. |
| GetTransactionData | Obtenha um item de transação dos comentários de uma matriz. Como há várias transações, usamos o argumento in_TransactionNumber como um índice para recuperar a transação correta a ser processada. Se não houver mais transações no lote atual, precisamos avançar o fluxo e buscar o próximo lote. Se buscarmos várias vezes em seguida sem avançar um fluxo, você receberá os mesmos resultados todas as vezes. Se houver itens no lote e ainda houver alguns para processar, utilizamos a instância do próximo Item de Transação no lote. Caso contrário, sinalizamos o fato de que não há mais itens a serem processados no lote atual e que precisamos fazer o fluxo avançar. Não definimos io_TransactionItem como nada aqui, pois isso interromperia o processamento de toda a estrutura e talvez ainda haja itens nos próximos lotes. A condição STOP é definida em Get Transaction Data STATE |
| CheckValidationRules | Esse é um exemplo de algoritmo de validação básico que decide se as previsões são válidas exclusivamente com base no número de rótulos previstos para o item atual. Se tivermos um rótulo, temos uma validação bem-sucedida e só precisamos obter o nome do processo downstream do arquivo de configuração. Se tivermos vários rótulos, a validação automática será definida como malsucedida.Adicione sua própria lógica para decidir o nome do processo do consumidor e se as previsões nos itens são válidas OU precisam de validação humana. Se tivermos apenas um rótulo previsto para o item atual, temos que obter o nome do seu processo correspondente. Pegamos o nome do processo downstream (consumidor) do arquivo de configuração, com base nesse rótulo previsto para o item atual. No arquivo de configuração, a convenção de nomenclatura da configuração do nome do processo é : o rótulo do comentário + a palavra-chave "_"+"Label". Se foi previsto que o item atual tenha vários rótulos, precisamos que o humano decida como prosseguir na automação downstream. Portanto, o sucesso da validação automática deve ser marcado como falso para que o item atual seja adicionado à fila Humano no loop para posterior validação manual. |
| CreateDictionaryFromCommunicationsMiningItem | Precisamos adicionar as informações obtidas do CommunicationsMining para o item atual a uma fila. Então, estamos criando um dicionário com base nele. Usaremos o dicionário para adicionar as propriedades definidoras do novo item da fila. |
| AddTransactionItemToQueue | Adicionando um novo item à fila. Todas as suas propriedades já devem estar configuradas no dicionário in_QueueItemProperties. Certifique-se de que sua fila tenha a caixa de seleção Impor referências exclusivas marcada. |
| Processo | O objetivo do dispatcher é preencher as filas correspondentes com as informações obtidas no Communications Mining™ para cada um dos itens, para que possam ser processadas pelos processos do consumidor na automação downstream. Neste fluxo de trabalho, temos que adicionar o item atual à sua fila correspondente.Etapas:1. Estamos criando um dicionário baseado no ItemDaTransação. Usaremos o dicionário para adicionar as propriedades de definição do novo item da fila.2. Com base nas informações obtidas no Communications Mining para o item atual, estamos decidindo seu Processo do consumidor correspondente e verificando as regras de validação em relação aos dados previstos.3. Se a validação for bem-sucedida, adicionaremos o item à fila do Processo do Consumidor. Se não, estamos adicionando-a à fila Human In The Loop, para ser validada e potencialmente processada por um humano. Para a Transação atual: - Se uma BusinessRuleException for gerada, a transação será ignorada.- Se outro tipo de exceção ocorrer, a transação atual pode ser repetida. |
| ExceptionsHandler | Este fluxo de trabalho deve ser usado como um Gerenciador de Exceção final no Framework. Se as TabelasDeDados de entrada forem preenchidas, elas conterão detalhes sobre todas as Exceções de Regras do Aplicativo e/ou Negócios que ocorreram durante a execução atual do processo. |
Como usar o Framework
Antes de usar o Framework:
- Certifique-se de configurar todos os ativos necessários no Orchestrator (verifique a seção Configurações e ativos) e faça as modificações necessárias no arquivo Data/Config.xlsx.
- Certifique-se de que as filas nas quais você adicionará os itens existam no Orchestrator e tenham a caixa de seleção “Impor referências exclusivas” selecionada para evitar adicionar duplicatas à fila e processar o mesmo item várias vezes nas automações downstream.
- Adicione suas próprias regras de validação em Communications Mining/CheckValidationRules.xaml . No momento, verificamos apenas se o item atual tem vários rótulos previstos. Se sim, a validação falhará. Caso contrário, consideramos o Nome do processo correspondente ao item atual, com base em seu rótulo.