- Introdução
- Configurando sua conta
- Balanceamento
- Clusters
- Desvio de conceito
- Cobertura
- Conjuntos de dados
- Campos gerais
- Rótulos (previsões, níveis de confiança, hierarquia do rótulo e sentimento do rótulo)
- Modelos
- Transmissões
- Classificação do Modelo
- Projetos
- Precisão
- Lembrar
- Mensagens anotadas e não anotadas
- Campos de extração
- Fontes
- Taxonomias
- Treinamento
- Previsões positivos e negativos verdadeiros e falsos
- Validação
- Mensagens
- Controle de acesso e administração
- Gerencie origens e conjuntos de dados
- Entender a estrutura de dados e permissões
- Criando ou excluindo uma origem de dados na GUI
- Preparando dados para carregamento de .CSV
- Carregar um arquivo CSV para uma origem
- Criação de um conjunto de dados
- Origens e conjuntos de dados multilíngues
- Habilitando o sentimento em um conjunto de dados
- Como corrigir as configurações do conjunto de dados
- Excluindo uma mensagem
- Exclusão de um conjunto de dados
- Exportação de um conjunto de dados
- Usando integrações do Exchange
- Email transform tags
- Treinamento e manutenção do modelo
- Noções Básicas sobre rótulos, campos gerais e metadados
- Hierarquia de rótulos e práticas recomendadas
- Comparação de casos de uso de análise e automação
- Transformando seus objetivos em rótulos
- Visão geral do processo de treinamento do modelo
- Anotação generativa
- Status do conjunto de dados
- Treinamento de modelos e práticas recomendadas de anotação
- Treinamento com análise de sentimento de rótulo habilitada
- Compreensão dos requisitos de dados
- Treinamento
- Introdução ao Refine
- Precisão e recall explicados
- Precisão e recall
- Como a validação funciona
- Compreender e melhorar o desempenho do modelo
- Motivos para baixa precisão média do rótulo
- Treinamento usando Check label e Perda de rótulo
- Treinamento usando Ensinar rótulo (Refinar)
- Treinamento usando a Pesquisa (Refinamento)
- Noções Básicas e Aumentando a Cobertura
- Melhorando o balanceamento e usando o Rebalanceamento
- Quando parar de treinar seu modelo
- Uso dos campos gerais
- Extração generativa
- Uso de análise e monitoramento
- Automations e Communications Mining™
- Desenvolvedor
- Carregamento de dados
- Baixando dados
- Integração do Exchange com usuário do serviço do Azure
- Integração do Exchange com Autenticação de Aplicativo do Azure
- Integração do Exchange com Autenticação de aplicativo e gráfico do Azure
- Guia de migração: Exchange Web Services (EWS) para a API do Microsoft Graph
- Como buscar dados para o Tableau com o Python
- Integração do Elasticsearch
- Extração de campo geral
- Integração auto-hospedada do Exchange
- Framework de automação da UiPath®
- Atividades oficiais da UiPath®
- Como as máquinas aprendem a entender as palavras: um guia para incorporações ao NLP
- Aprendizado baseado em solicitação com Transformers
- Efficient Transformers II: extração de conhecimento e ajustes finos
- Transformers eficientes I: mecanismos de atenção
- Modelagem de intenção hierárquica profunda não supervisionada: obtenção de valor sem dados de treinamento
- Corrigindo viés de anotação com o Communications Mining™
- Aprendizado ativo: melhores modelos de ML em menos tempo
- Está tudo nos números - avaliando o desempenho do modelo com métricas
- Por que a validação de modelos é importante
- Comparação do Communications Mining™ e do Google AutoML para inteligência de dados de conversa
- Licenciamento
- Perguntas frequentes e mais
Guia do usuário do Communications Mining
As empresas funcionam baseadas em comunicação: os clientes entram em contato quando querem algo, colegas se comunicam para realizar um trabalho. Cada mensagem conta. Nossa missão no Communications Mining™ é revelar o valor dessas mensagens e ajudar todas as equipes da empresa a fornecer produtos e serviços melhores com eficiência e em escala.
Com esse objetivo, pesquisamos e desenvolvemos continuamente nossa principal tecnologia de machine learning e compreensão de linguagem natural. Os modelos de machine learning do Communications Mining usam pré-treinamento, aprendizado não supervisionado, aprendizado semisupervisionado e aprendizado ativo para entregar precisão de última geração com o mínimo de tempo e investimento de nossos usuários.
Neste post de pesquisa, exploramos uma nova abordagem não supervisionada para reconhecer automaticamente os tópicos e intenções, e sua estrutura taxonômica, a partir de um conjunto de dados de comunicações. Trata-se de melhorar a qualidade das informações que fornecemos e a velocidade com que elas são obtidas.
Resumo
Os modelos de tópico são uma classe de métodos para descobrir os "temas" que ocorrem em uma coleção de "documentos". É importante notar que os modelos de tópico funcionam sem a necessidade de coletar dados de treinamento anotados. Eles identificam automaticamente os tópicos em um conjunto de dados e quais tópicos aparecem em cada documento.
Um email de "operação de negócios fracassada" e os tipos de tópicos hierárquicos que gostaríamos de inferir automaticamente
Neste post:
- Explicamos os modelos de tópicos tradicionais e discutimos alguns de seus pontos fracos, por exemplo, o número de tópicos deve ser conhecido com antecedência, as relações entre os tópicos não são capturadas, etc.
- Organizamos os tópicos em uma hierarquia que é inferida automaticamente com base na estrutura métrica do conjunto de dados. A hierarquia agrupa tópicos semanticamente relacionados.
- Obtemos uma hierarquia de tópicos mais coerente ao incorporar incorporações baseadas no Transformer ao modelo.
Segundo plano
Os modelos de tópico pressupõem que um conjunto de dados (Coleção de documentos) contém um conjunto de tópicos. Um tópico especifica a probabilidade de cada palavra ocorrer em um documento. Cada documento no conjunto de dados é gerado a partir de uma mistura dos tópicos. Em geral, conjuntos de palavras que ocorrem frequentemente juntas terão uma alta probabilidade em um determinado tópico.
Por exemplo, suponha que tenhamos um conjunto de dados composto dos seguintes documentos:
- Documento 1: "cães são descendentes disparos de animais"
- Documento 2: "gatos são animais carníivosos que têm animaisus e ans UiPath escalonados"
- Documento 3: " os grandes grana são conhecidos por pastar Cão"
- Documento 4: "após serem aparados pelas Unhas cortadas das administradoras de animais, alguns guias podem ficar com temor a animais"
- Documento 5: "cães disparos podem preferir a presença de animais a outros animais"
Um modelo de tópico treinado nesses documentos pode aprender os seguintes tópicos e atribuições de tópico de documento:
| Tópico 1 | Tópico 2 |
|---|---|
| Cão | Gatilhos |
| Caseiro | Garras |
| Lobos | Robôs |
| ... | ... |
Tópicos de exemplo com palavras classificadas pela maior probabilidade.
| Tópico 1 | Tópico 2 | |
|---|---|---|
| Documento 1 | 100% | 0% |
| Documento 2 | 0% | 100% |
| Documento 3 | 50% | 50% |
| Documento 4 | 33% | 67% |
| Documento 5 | 67% | 33% |
Exemplo de atribuições de tópico de documento.
Exibir as palavras mais prováveis para cada tópico, além de quais tópicos cada documento pertence, fornece uma visão geral do que é o texto em um conjunto de dados e quais documentos são semelhantes entre si.
Modelos de tópico incorporados
O modelo de tópico canônico é chamado de Alocação Latente de Diichlet (LDA). É um modelo generativo, treinado usando uma estimativa de probabilidade máxima (aproximada). O LDAP pressupõe que:
- Existem K tópicos, cada um dos quais especifica uma distribuição pelo dicionário (o conjunto de palavras no conjunto de dados).
- Cada documento (Coleção de palavras) tem uma distribuição de tópicos.
- Cada palavra em um documento é gerada a partir de um tópico, de acordo com a distribuição do documento sobre tópicos e a distribuição do tópico sobre o dicionário.
A maioria dos modelos de tópico modernos é criada em LDA; inicialmente nos concentramos no Modelo de Tópicos Incorporado (ETM). O ETM usa incorporações para representar palavras e tópicos. Na modelagem de tópicos tradicional, cada tópico é uma distribuição completa no dicionário. Entretanto, no ETM, cada tópico é um vetor no espaço de incorporação. Para cada tópico, o ETM usa a incorporação de tópicos para formar uma distribuição no dicionário.
Treinamento e inferência
O processo generativo para um documento é o seguinte:
-
Exemplo da representação latente z da distribuição anterior: z∈ N(0,I).
-
Calcule as proporções do tópico θ=softmax(z).
-
Para cada palavra w no documento:
- Exemplo de atribuição de tópico oculto
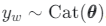 2. Exemplo da palavra
2. Exemplo da palavra
ondeU∈ RPxE é a matriz de incorporação de palavras e Taskm ∈ RE é a incorporação do tópico yw; estes são os parâmetros do modelo. V é o número de palavras no dicionário e E é o tamanho de incorporação.
A probabilidade de log para um documento com as palavras v1 ,v2 ,...,vw é:
Onde:
Infelizmente, a integral mencionada anteriormente é tratável. Portanto, não é fácil maximizar a probabilidade de log diretamente. Em vez disso, ele é maximizado aproximadamente usando inferência variacional. Para fazer isso, uma distribuição de 'inferência' q q (z∈x) (com parâmetros reas) é usada para formar um limite inferior na probabilidade de log com base na equação de Jensen, onde x=x1 ,...,xW:
Esse limite inferior agora pode ser maximizado usando aproximações de Monte Carlo do gradiente por meio do chamado 'truque de reparameters'.
Um Gaussiano é usado para a distribuição de inferência, cuja média e variação são as saídas de uma rede neural, que recebe como entrada a representação do pacote de palavras do documento.
Devido ao objetivo de treinamento anterior, a distribuição de inferência aprende a se aproximar do posterior verdadeiro, mas persistente, ou seja *qθ*(**z**∣**x**)≃*p*(**z**∣**x**). Isso significa que, após o modelo ser treinado, podemos usar a distribuição de inferência para encontrar os tópicos aos quais um documento foi atribuído. Usar a média da distribuição de inferência e aplicar a função Softmax (conforme a etapa 2 do processo generativo anterior) fornecerá as proporções aproximadas do tópico posterior para um determinado documento.
Um exemplo do mundo real
Treinamos um ETM no conjunto de dados de 20 grupos de notícias , que tem comentários de fórums de discussão sobre 20 tópicos hierárquicos categorizados da seguinte maneira:
- Computação: comp.gráficos, comp.os.ms-windows.misc, comp.sys.ibm.pc.hardware, comp.sys.mac.hardware, comp.windows.x
- Recriação: rec.autos, rec.drives, rec.port.baseball, rec.port.hockey
- História: sci.crypt, sci.electerns, sci.ted, sci.space
- Política: about.policies.misc, conversa.politic.guns, conversa.policies.mídias
- Relevância: about.religion.misc, alt.atheuss
- Diversos: Misc.forsale
No Communications Mining, trabalhamos exclusivamente com dados de comunicações, que são notoriamente privados. Para reprodutibilidade e porque é o conjunto de dados de modelagem de tópicos mais comumente usado na biblioteca de pesquisa de machine learning, usamos o conjunto de dados de 20 Robots aqui. Isso é considerado o "hello world" da modelagem de tópicos.
Treinamos o modelo com 20 tópicos (ou seja K = 20), pois, para esse conjunto de dados, já sabemos quantos tópicos existem (mas, em geral, esse não será o caso). Usamos GloVe para inicializar a matriz de incorporação U.
A imagem a seguir descreve as 10 principais palavras aprendidas para cada tópico e o número de documentos que têm cada tópico como o mais provável:
As palavras mais prováveis de cada tópico aprendidas pelo ETM
As principais palavras aprendidas correspondem de maneira geral aos tópicos verdadeiros no conjunto de dados, por exemplo tópico 2 = contact.politic.guns, tópico 13 = sci.space, etc. Para cada documento, também podemos visualizar as probabilidades de atribuição de tópicos; alguns exemplos são mostrados nas seções a seguir. Certos documentos têm uma alta probabilidade para um único tópico, enquanto outros documentos são misturas de vários tópicos.
Exemplo 1
Parece disparate, mas embora eu tenha localizado coisas como o tgif, que pode editar arquivos gif e várias ferramentas para converter de/para o formato gif, não consegui localizar um programa que apenas abra uma janela e exiba um arquivo gif nele. Procurei em vários arquivos de perguntas frequentes e também sem sucesso. Existe algum à espreita em algum arquivo? Nada sofisticado; apenas "mostrar a graciosa imagem"? Alternativamente, se eu pudesse localizar as especificações do gif, não suponha que seja muito difícil escrevê-lo por conta própria, mas não tenho ideia de por onde começar a procurar a especificação. (Bem, na verdade, eu tenho uma ideia - este grupo de notícias.;-) Obter, xv, versão 3.0. Ele lê/exibe/manipula muitos formatos diferentes.
Exemplo 2
O ex-goler que você se refere é Clint Malarchuk. Ele estava andando com os Saberes. Sua equipe imediatamente anterior a isso era o DCS. Embora ele tenha se recuperado e continuado a treinar, não sei seu paradeiro atual.
Exemplo 3
Olá, no NetMundo, Temos um Lab de Macs antigos (SEs e Pluses). Não temos dinheiro suficiente para comprar todas as máquinas novas, então estamos considerando comprar alguns superdrives para nossos macs antigos para permitir que o pessoal com discos de alta densidade use nosso equipamento. Eu gostaria de saber quais experiências (boas ou más) as pessoas tiveram com esse tipo de atualização. Array
Mesmo sem saber nada sobre o conjunto de dados com antecedência, esses resultados mostram que é possível de forma rápida e fácil obter uma visão geral do conjunto de dados, identificar a quais tópicos cada documento pertence e agrupar documentos semelhantes. Se também quisermos coletar dados anotados para treinar uma tarefa supervisionada, as saídas do modelo de tópico nos permitem começar a anotar de uma perspectiva mais informada.
Modelos de tópicos estruturados em árvore
Embora os modelos de tópico, conforme descrito na seção anterior possam ser muito úteis, eles têm certas limitações:
- O número de tópicos deve ser especificado com antecedência. Em geral, não saberemos qual deve ser o número correto.
- Embora seja possível treinar vários modelos com diferentes números de tópicos e escolher o melhor, isso custa alto.
- Mesmo que saibamos o número correto de tópicos, os tópicos aprendizados podem não corresponder aos corretos, por exemplo, o tópico 16 na Figura 1 não parece corresponder a nenhum dos tópicos verdadeiros no conjunto de dados dos 20 grupos de notícias.
- O modelo não captura como os tópicos estão relacionados entre si. Por exemplo, na Figura 1 há vários tópicos sobre computação, mas a ideia de que eles estão relacionados não é aprendida pelo modelo.
Na realidade, geralmente acontece que o número de tópicos é desconhecido de antemão e os tópicos estão de alguma forma relacionados entre si. Um método para resolver esses problemas é representar cada tópico como um nó em uma árvore. Isso nos permite modelar as relações entre tópicos; tópicos relacionados podem estar na mesma parte da árvore. Isso forneceria saídas muito mais fáceis de interpretar. Além disso, se o modelo pode aprender com os dados quantos tópicos devem haver e como eles estão relacionados entre si, não precisamos saber de nada com antecedência.
Para conseguir isso, usamos um modelo baseado no Modelo de tópico neural estruturado em árvore (TSNTM). O processo generativo funciona escolhendo um caminho da raiz da árvore até uma folha e, em seguida, escolhendo um nó ao longo desse caminho. As probabilidades sobre os caminhos da árvore são modeladas usando um processo de quebra de linha, que é parametrizado usando uma rede neural duplamente recorrente.
Processos que interrompem o bloqueio
O processo de quebra de suporte pode ser usado para modelar as probabilidades sobre os caminhos de uma árvore. Intuitivamente, isso envolve quebrar repetidamente um suporte que inicialmente tem comprimento 1. A proporção do retângulo correspondente a um nó na árvore representa a probabilidade ao longo desse caminho.
O processo de quebra do graveto, com proporções em verde
Por exemplo, considere a árvore na Figura 2, com 2 camadas e 2 filhos em cada camada. No nó raiz, o comprimento do stick é 1. Em seguida, ele é dividido em duas partes, de comprimento 0,7 e 0,3 respectivamente. Cada uma dessas partes é então dividida ainda mais até chegarmos às folhas da árvore. Como podemos continuar quebrando o graveto, a árvore pode ser arbitrariamente larga e profunda.
Redes encefálicas duplamente recorrentes
Como no ETM, o processo generativo do TSNTM começa por amostrar a representação latente z da distribuição anterior:
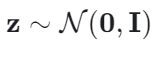
Uma rede neural duplamente recorrente (DRNN) é usada para determinar as proporções de quebra. Após inicializar aleatoriamente o estado oculto do nó raiz, h1 , para cada tópico k, o estado oculto hk é fornecido por:
onde hpar(k) é o estado oculto do nó pai e hk-1 é o estado oculto do nó irmãos imediatamente anterior (os irmãos são ordenados com base em seu índice inicial).
A proporção do stick restante alocado para o tópico k,vk é fornecida por:
Então, a probabilidade no nó k,πk é fornecida por
onde j∈{1,…,k Usuários-1} são os irmãos anteriores do nó k. Esses são os valores em verde na Figura 2. O valor em cada nó folha é a probabilidade para esse caminho (Há apenas um caminho para cada nó folha).
Agora que temos probabilidades sobre os caminhos da árvore, precisamos de probabilidades sobre os nós dentro de cada caminho. Eles são calculados usando outro processo de quebra de pacote. Em cada nível da árvore, o estado oculto gl é dado por:
Isso significa que todos os nós no mesmo nível da árvore têm o mesmo valor para gl.
A proporção do stick restante alocado ao nível l,nl é fornecida por:
A probabilidade no nível l,θl é fornecida por:
Empiricamente, às vezes concluímos que as palavras mais prováveis para os nós filhos da árvore não estavam semanticamente relacionadas às de seus pais. Para resolver isso, na Equação 2 aplicamos uma tempetura para amenizar o sigmoide:
Em nossos testes, definimos ff=0,1. Isso torna mais provável que, quando um nó filho tiver massa de probabilidade diferente de zero, seus pais também a terão (reduzindo a chance de os nós filhos não terem relação com seus pais).
Treinamento e inferência
O objetivo do treinamento permanece o mesmo da Equação 1; a única mudança é como p(xw=vw|z) é especificado. Isso agora é dado por:
Atualizar a estrutura da árvore
Até agora, a estrutura da árvore foi corrigida. No entanto, gostaríamos que isso fosse aprendido com base nos dados. Especificar a estrutura exata da árvore como um hiperparâmetro é muito mais difícil do que simplesmente especificar um número de tópicos, como faria para um modelo de tópico plano. Se soubermos a estrutura geral da árvore de antemão, provavelmente não precisaremos modelar os tópicos. Portanto, as aplicações práticas de modelos de tópicos estruturados em árvore precisam poder aprender a estrutura a partir dos dados. Para fazer isso, duas regras heurísticas são usadas para adicionar e excluir nós de e para a árvore. Primeiro, a massa total de probabilidade em cada nó é estimada usando um subconjunto aleatório dos dados de treinamento. No nó k, essa estimativa é:
onde d={1,…,D} indexa o subconjunto de documentos escolhidos aleatoriamente e Nd é o número de palavras no documento d. Com base nessas estimativas, após cada iteração :
- Se pk estiver acima de um limite, um filho será adicionado abaixo do nó k para refinar o tópico.
- Se a soma cumulativa
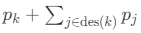 for menor que um limite, o nó k e seus descendentes serão excluídos.
for menor que um limite, o nó k e seus descendentes serão excluídos.
Resultados em 20 grupos de notícias
Executamos o TSNTM no mesmo conjunto de dados de 20 grupos de notícias usado para o treinamento do ETM acima. Inicializamos a árvore para ter 2 camadas com 3 filhos em cada camada. A imagem a seguir mostra a estrutura de árvore final, as 10 principais palavras aprendidas para cada tópico e o número de documentos que têm cada tópico como o mais provável:
Palavras mais prováveis para cada tópico aprendidas pelo TSNTM
Comparada com o modelo de tópico plano, a abordagem estruturada em árvore tem vantagens claras. A árvore é aprendida automaticamente com os dados, com tópicos semelhantes sendo agrupados em diferentes partes da árvore. Os tópicos de nível mais alto ficam no topo da árvore (por exemplo, palavras não informativas que aparecem em muitos documentos estão na raiz), e os tópicos mais refinados/específicos estão nas folhas. Isso gera resultados muito mais informativos e fáceis de interpretar do que a saída do modelo plano na Figura 1.
Documentos de exemplo e as probabilidades de atribuição de tópicos associadas aprendidas pelo TSNTM são mostrados nas seguintes seções:
Exemplo 1
Acabamos de receber um AppleOne Color Scanner para o nosso testes. No entanto, estou tendo problemas para obter uma saída digitalizada razoável ao imprimir uma foto digitalizada em um DesignerIg. Procurei digitalizar em uma resolução mais alta e a exibição na tela está muito boa. No entanto, a versão impressa está ficando feia! Isso é devido aos recursos de resolução da impressão? Ou existem alguns truques envolvidos para obter melhor qualidade? Ou deveremos comprar algo (como o FotoStop) para "atualizar" a imagem? Eu aprecio todas as sugestões. Agradecemos desde já, -Kris
Exemplo 2
Acabamos - os Sabers voltaram para vencer os Bruins no OT 6-5 hoje à noite para limpar a série. Um belíssimo objetivo de Rob May (Lafonteine preparou para ele enquanto estava deitada no campo) terminou com ele. Fuhr deixou o jogo com um lado do esquerdo e Lafonteine também foi atingido; no entanto, os Sabers terão uma semana de repouso, portanto, as alterações não devem ser um problema. O time de Montana superou o Quebeque por 3 a 2 para igualar sua série, que parece se encaminhar para o jogo 7. Os Habs dominaram os dois primeiros períodos e tiveram o azar de empor apenas 2 a 2 após 40 minutos. No entanto, um objetivo inicial de Brunet no terceiro lugar ganhou o título. Os Islanders ganharam seu 3º jogo OT da série com um objetivo de Ray Ferramentas: 4-3; os Caps simplesmente colapsaram após assumir uma vantagem de 3-0 no 2º. O registro de OT de todos os tempos nos Playoffs das Ilhas é agora de 28-7.
Exemplo 3
Informe-me onde posso encontrar um CD da gravadora Wergo Musical por menos de US$ 20.
Documentos que claramente se enquadram em um tópico específico (por exemplo, o primeiro) têm uma alta probabilidade em um nó folha, enquanto aqueles que não se enquadram claramente em nenhum dos tópicos aprendizados (por exemplo, o terceiro) têm uma alta probabilidade no nó raiz .
Avaliação Quantitativa
Os modelos de tópico são notoriamente difíceis de avaliar quantitativamente. No entanto, a métrica mais popular para medir a coerência de tópico é a Informação Mútua Pontos Normal (NPMI). Tomando as principais palavras M para cada tópico, o NPMI será alto se cada par de palavras Wi e wj tiverem uma alta probabilidade conjunta P(wi,wj) em comparação com suas probabilidades inferiores P(wi) e P(wj):
As probabilidades são estimadas usando contagens empricas.
| NPMI | |
|---|---|
| ETM | 0.193 |
| TSNTM | 0.227 |
Esses resultados suportam os resultados qualitativos de que o TSNTM é um modelo mais coerente do que o ETM.
Incorporação de Transformers
Embora o TSNTM produza resultados intuitivos e fáceis de interpretar, o modelo aprendizado ainda possui pontos fracos. Por exemplo, na Figura 3, os tópicos relacionados à política e espaço foram agrupados sob o mesmo nó pai. Isso pode não ser irracional, mas o nó pai deles está relacionado à família, o que sem dúvida não é coerente. Outro exemplo mais sutil é que o Tópico 1.3 agrupa tópicos de computação relacionados a hardware e software; talvez eles devam ser separados.
Apresentamos a hipótese de que esses problemas ocorrem porque os modelos treinados até agora foram baseados em incorporações do GloVe (não contextual). Isso pode dificultar a desambiguação de palavras que tenham significados diferentes em contextos distintos. Nos últimos anos, os modelos baseados no Transformer alcançaram um desempenho de ponta para o aprendizado de representações informativas e contextuais de texto. Procuramos incorporar incorporações do Transformer ao TSNTM.
Seguimos a abordagem do Modelo de tópicos combinados (CTM). Em vez de usar apenas a representação do pacote de palavras como entrada para o modelo de inferência, agora concatenamos a representação do pacote de palavras com a média dos estados finais da camada de um modelo do Transformer. Embora essa seja uma modificação simples, ela deve permitir que o modelo de inferência aprenda uma melhor abordagem posterior. Para o modelo do Transformer, usamos a variante all-mpnet-base-v2 do Sentence-BERT (SBERT), pois ele atinge consistentemente pontuações alta em várias tarefas no nível de sentença.
Treinamos um modelo que, caso contrário, é idêntico ao TSNTM da seção anterior, exceto com as incorporações SBERT adicionadas ao modelo de inferência. Mais uma vez, a imagem a seguir exibe as 10 principais palavras aprendidas para cada tópico e o número de documentos que têm cada tópico como o mais provável:
Palavras mais prováveis de cada tópico aprendidas por SBERT+TSNTM
O TSNTM com as incorporações do SBERT parece resolver alguns dos problemas de incoerência do modelo somente com GloVe. Os tópicos política, política e criptografia agora estão agrupados sob o mesmo tópico pai. Mas, diferente do modelo Somente GloVe, esse pai agora é um tópico mais genérico, cujas principais palavras estão relacionadas a pessoas expressando opiniões. Os tópicos de hardware e software de computador foram divididos, e o espaço está em sua própria parte da árvore. O NPMI também sugere que o modelo com as incorporações SBERT é mais coerente:
| NPMI | |
|---|---|
| ETM | 0.193 |
| TSNTM (apenas o GloVe) | 0.227 |
| TSNTM (GloVe + SBERT) | 0.234 |
Resumo
Mostramos que os modelos de tópico podem ser uma ótima maneira de obter uma compreensão de alto nível de um conjunto de dados sem precisar fazer nenhuma anotação.
- Os modelos de tópico "Plano" são os mais usados, mas também possuem pontos fracos (por exemplo, saída não é a mais fácil de interpretar, precisando saber o número de tópicos com antecedência).
- Esses pontos fracos podem ser abordados usando um modelo estruturado em árvore, que agrupa tópicos relacionados e aprende automaticamente a estrutura do tópico a partir dos dados.
- Os resultados da modelagem podem ser melhorados ainda mais usando incorporações do Transformer.
Se quiser experimentar o Communications Mining™ em sua empresa, inscreva-se para fazer uma avaliação ou veja uma demonstração.
- Resumo
- Segundo plano
- Modelos de tópico incorporados
- Treinamento e inferência
- Um exemplo do mundo real
- Exemplo 1
- Exemplo 2
- Exemplo 3
- Modelos de tópicos estruturados em árvore
- Processos que interrompem o bloqueio
- Redes encefálicas duplamente recorrentes
- Treinamento e inferência
- Atualizar a estrutura da árvore
- Resultados em 20 grupos de notícias
- Exemplo 1
- Exemplo 2
- Exemplo 3
- Avaliação Quantitativa
- Incorporação de Transformers
- Resumo