Más información sobre la automatización agéntica y la orquestación con UiPath
Maestro
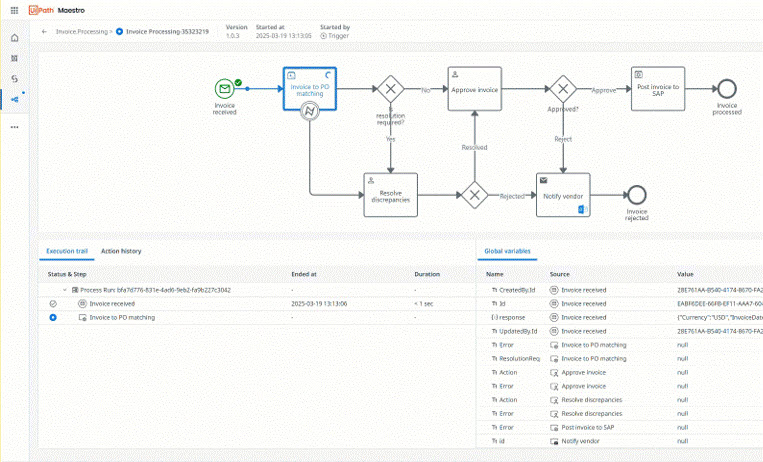
Orquesta agentes de IA, automatizaciones y personas en procesos completos para ofrecer resultados medibles
Comience con UiPath
Orquesta un proceso empresarial completo en un solo flujo de trabajo
Crea tu primer proyecto en Studio
Crea tu primer agente en Studio Web
Crea agentes conversacionales utilizando nuestro diseñador de código bajo en Studio Web
Aprende cómo los conectores proporcionan acceso seguro y estandarizado a sistemas externos
Temas populares
Permite el tráfico de red necesario para Automation Cloud
Instala Studio en tu máquina
Crea tus primeras automatizaciones paso a paso
Elige dónde se almacenan tus datos de Automation Cloud
Crea y ejecuta automatizaciones en un explorador
Novedades
Agentic solutions for your industry
Deploy conversational agents to Microsoft Teams and Slack
Integration Service connections are now available in Orchestrator
Split and classify multi-document packets using a trainable ML model
Agents, Maestro, and MCP Servers now available in Automation Suite