- Einleitung
- Einrichten Ihres Kontos
- Ausgewogenheit
- Cluster
- Konzeptabweichung
- Abdeckung
- Datasets
- Allgemeine Felder
- Beschriftungen (Vorhersagen, Konfidenzniveaus, Beschriftungshierarchie und Beschriftungsstimmung)
- Modelle
- Streams
- Modellbewertung
- Projekte
- Präzision
- Rückruf
- Nachrichten mit und ohne Anmerkungen
- Extraktionsfelder
- Quellen
- Taxonomien
- Training
- „True“ und „false“ positive und negative Vorhersagen
- Validierung
- Messages
- Zugriffssteuerung und Administration
- Verwalten Sie Quellen und Datasets
- Verstehen der Datenstruktur und -berechtigungen
- Erstellen oder Löschen einer Datenquelle in der GUI
- Vorbereiten von Daten für den CSV-Upload
- Hochladen einer CSV-Datei in eine Quelle
- Ein Dataset wird erstellt
- Mehrsprachige Quellen und Datasets
- Aktivieren der Stimmung für ein Dataset
- Ändern der Dataset-Einstellungen
- Löschen einer Nachricht
- Löschen eines Datasets
- Exportieren eines Datasets
- Verwenden von Exchange-Integrationen
- E-Mail-Transformations-Tags
- Modelltraining und -wartung
- Grundlegendes zu Beschriftungen, allgemeinen Feldern und Metadaten
- Beschriftungshierarchie und Best Practices
- Vergleichen von Anwendungsfällen für Analyse und Automatisierung
- Konvertieren Ihrer Ziele in Bezeichnungen
- Übersicht über den Modelltrainingsprozess
- Generative Anmerkung
- Der Status des Datasets
- Best Practice für Modelltraining und Anmerkungen
- Training mit aktivierter Beschriftungs-Stimmungsanalyse
- Grundlegendes zu Datenanforderungen
- Trainieren
- Einführung in Verfeinerung
- Erläuterungen zu Präzision und Rückruf
- Präzision und Rückruf
- So funktioniert die Validierung
- Verstehen und Verbessern der Modellleistung
- Gründe für die geringe durchschnittliche Beschriftungsgenauigkeit
- Training mit Beschriftung „Überprüfen“ und Beschriftung „Verpasst“.
- Training mit der Bezeichnung „Teach“ (Verfeinern)
- Training mit der Suche (verfeinern)
- Verstehen und Erhöhen der Abdeckung
- Verbesserung des Abgleichs und Verwendung des Abgleichs
- Wann das Training Ihres Modells beendet werden soll
- Verwenden von allgemeinen Feldern
- Generative Extraktion
- Verwenden von Analyse und Überwachung
- Automations and Communications Mining™
- Entwickler (Developer)
- Verwenden der API
- API-Tutorial
- Quellen
- Datasets
- Anmerkungen
- Anhänge (Attachments)
- Vorhersagen
- Erstellen Sie einen Stream
- Aktualisieren Sie einen Stream
- Rufen Sie einen Stream nach Namen ab
- Rufen Sie alle Streams ab
- Löschen Sie einen Stream
- Ergebnisse aus Stream abrufen
- Kommentare aus einem Stream abrufen (Legacy)
- Bringen Sie einen Stream vor
- Einen Stream zurücksetzen
- Kennzeichnen Sie eine Ausnahme
- Entfernen Sie das Tag einer Ausnahme
- Prüfungsereignisse
- Alle Benutzer abrufen
- Hochladen von Daten
- Herunterladen von Daten
- Exchange Integration mit einem Azure-Dienstbenutzer
- Exchange-Integration mit der Azure-Anwendungsauthentifizierung
- Exchange-Integration mit Azure Application Authentication und Graph
- Migrationsanleitung: Exchange Web Services (EWS) zur Microsoft Graph-API
- Abrufen von Daten für Tableau mit Python
- Elasticsearch-Integration
- Allgemeine Feldextraktion
- Selbst gehostete Exchange-Integration
- UiPath® Automatisierungs-Framework
- Offizielle UiPath®-Aktivitäten
- Wie Maschinen lernen, Wörter zu verstehen: eine Anleitung zu Einbettungen in NLP
- Eingabeaufforderungsbasiertes Lernen mit Transformers
- Ef Robots II: Wissensdegesterration und Feinabstimmung
- Effiziente Transformer I: Warnmechanismen
- Tief hierarchische, nicht überwachte Absichtsmodellierung: Nutzen ohne Trainingsdaten
- Beheben von Anmerkungsverzerrungen mit Communications Mining™
- Aktives Lernen: Bessere ML-Modelle in weniger Zeit
- Auf Zahlen kommt es an – Bewertung der Modellleistung mit Metriken
- Darum ist Modellvalidierung wichtig
- Vergleich von Communications Mining™ und Google AutoML für Conversation Data Intelligence
- Lizenzierung
- Häufige Fragen und mehr
Tiefe hierarchische, unbeaufsichtigte Absichtsmodellierung in IXP in Automation Cloud zur Wertextraktion aus der Kommunikation ohne Trainingsdaten.
Unternehmen brauchen Kommunikation – Kunden melden sich, wenn sie etwas wollen, Kollegen kommunizieren, um Arbeit zu erledigen. Jede Nachricht zählt. Unsere Aufgabe bei Communications Mining™ ist es, den Wert dieser Nachrichten zu erschließen und jedem Team in einem Unternehmen zu helfen, bessere Produkte und Dienstleistungen effizient und in großem Umfang bereitzustellen.
Mit diesem Ziel erforschen und entwickeln wir kontinuierlich unsere Kerntechnologie für Machine Learning und das Verständnis natürlicher Sprache. Die Machine-Learning-Modelle bei Communications Mining verwenden Vortraining, unüberwachtes Lernen, halbüberwachtes Lernen und aktives Lernen, um eine moderne Genauigkeit mit minimalem Zeit- und Mindestaufwand durch unsere Benutzer zu erzielen.
In diesem Forschungsbeitrag untersuchen wir einen neuen, nicht überwachten Ansatz zur automatischen Erkennung der Themen und Absichten und deren Taxonomiestruktur aus einem Kommunikations-Dataset. Es geht darum, die Qualität der von uns gelieferten Erkenntnisse und die Geschwindigkeit, mit der diese gewonnen werden, zu verbessern.
Zusammenfassung
Themenmodelle sind eine Klasse von Methoden zum Erkennen der „Themen“, die in einer Sammlung von „Dokumenten“ auftreten. Wichtig ist, dass Themenmodelle funktionieren, ohne dass Trainingsdaten mit Anmerkungen gesammelt werden müssen. Sie identifizieren automatisch die Themen in einem Dataset und welche Themen in jedem Dokument vorkommen.
Eine angenommene E-Mail mit „fehlgeschlagener Handel“ und die Typen der hierarchischen Themen, die wir automatisch ableiten möchten
In diesem Beitrag:
- Wir erklären klassische Themenmodelle und diskutieren einige ihrer Schwachstellen, z. B. dass die Anzahl der Themen im Voraus bekannt sein muss, die Beziehungen zwischen Themen nicht erfasst werden usw.
- Wir organisieren die Themen in einer Hierarchie, die basierend auf der aktuellen Struktur des Datasets automatisch abgeleitet wird. Die Hierarchie gruppiert semantisch verwandte Themen.
- Wir erreichen eine kohärentere Themenhierarchie, indem wir Transformer-basierte Einbettungen in das Modell integrieren.
Hintergrund
Themenmodelle gehen davon aus, dass ein Dataset (Sammlung von Dokumenten) eine Reihe von Themen enthält. Ein Thema gibt an, wie wahrscheinlich die einzelnen Wörter in einem Dokument vorkommen. Jedes Dokument im Dataset wird aus einer Mischung der Themen generiert. Im Allgemeinen haben Sätze von Wörtern, die häufig zusammen vorkommen, eine hohe Wahrscheinlichkeit in einem bestimmten Thema.
Angenommen, wir haben beispielsweise ein Dataset, das aus den folgenden Dokumenten besteht:
- Dokument 1: „Hunde sind z untert
- Dokument 2: „Kagaren sind zeichen übergeben mit ihrer alsoen und einingen
- Dokument 3: „Großen Roboter sind dafür bekannt, Menschen anzugreifen.“
- Dokument 4: „Nach dem An klicken mit den Objekten von Objekten von Objekten von Objekten mit Objekten, die zu Objekten von Objekten, Objekten, Objekten, ausgeführt werden, können einige ausgeführt werden.
- Dokument 5: „DOMdokument
Ein Themenmodell, das auf diesen Dokumenten trainiert wurde, kann die folgenden Themen und Dokument-Themenzuweisungen lernen:
| Thema 1 | Thema 2 |
|---|---|
| an einen Ort | Katzen |
| gezeigt | Greifen Sie zu |
| Wöchentlich | Whiskers |
| ... | ... |
Beispielthemen mit Wörtern, die nach höchster Wahrscheinlichkeit sortiert sind.
| Thema 1 | Thema 2 | |
|---|---|---|
| Dokument 1 | 100% | 0% |
| Dokument 2 | 0% | 100% |
| Dokument 3 | 50% | 50% |
| Dokument 4 | 33% | 67% |
| Dokument 5 | 67% | 33% |
Beispiele für Dokumentthemenzuweisungen.
Die Anzeige der wahrscheinlichsten Wörter für jedes Thema sowie der Themen, zu denen jedes Dokument gehört, bietet einen Überblick darüber, worum es im Text in einem Dataset geht und welche Dokumente einander ähnlich sind.
Eingebettete Themenmodelle
Das kanonische Themenmodell heißt Latenz Es handelt sich um ein generatives Modell, das mit der Schätzung der maximalen Wahrscheinlichkeit trainiert wurde. LDA geht davon aus, dass:
- Es gibt K Themen, von denen jedes eine Verteilung über das Vokabular (die Gruppe von Wörtern im Dataset) gibt.
- Jedes Dokument (Aufzählung von Wörtern) weist eine Verteilung über Themen auf.
- Jedes Wort in einem Dokument wird aus einem Thema generiert, entsprechend der Verteilung des Dokuments über Themen und der Verteilung des Themas über den Wortstamm.
Die meisten modernen Themenmodelle basieren auf LDA; Zunächst konzentrieren wir uns auf das Embedded Topic Model (ETM). Das ETM verwendet Einbettungen, um sowohl Wörter als auch Themen darzustellen. In der traditionellen Themenmodellierung ist jedes Thema eine vollständige Verteilung über das WortSprechstelle. Im ETM ist jedoch jedes Thema ein Vektor im Einbettungsbereich. Für jedes Thema verwendet das ETM die Themeneinbettung, um eine Verteilung über das Vokabular zu bilden.
Training und Inferenz
Der generative Prozess für ein Dokument sieht folgendermaßen aus:
-
Stichproben für die verborgene Darstellung z aus der vorherigen Verteilung: z∨N(0,I).
-
Berechnen Sie die Themenanteile Computer=softmax(z).
-
Für jedes Wort w im Dokument:
- Beispiel für die geheime Themenzuweisung
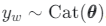 2. Beispiel das Wort
2. Beispiel das Wort
wobeiU∈alaldiE die Wörter-Einbettungsmatrix und tyw` ∈ RE die Einbettung des Themas yw ist; Das sind die Modellparameter. V ist die Anzahl der Wörter im Wörterbuch und E ist die Einbettungsgröße.
Die Protokollierungswahrscheinlichkeit für ein Dokument mit den Wörtern v1,v2,…,vw ist:
wobei:
Leider ist das zuvor erwähnte Integral nicht kontrahierbar. Daher ist es nicht einfach, die Protokollwahrscheinlichkeit direkt zu maximieren. Stattdessen wird sie ungefähr mithilfe der Variationsinferenz maximiert. Dazu wird eine „Inferenz“-Verteilung q SAP (z∨x) (mit Parametern ϕ) verwendet, um eine Untergrenze für die Protokollwahrscheinlichkeit basierend auf der Jensen-Ungleichheit zu bilden, wobei x=x1,…,xW:
Diese Untergrenze kann nun mit maximiert werden, indem mithilfe vonMonte Carlo-Anäherungn des Farbverlaufs durch den so genannten „Reparametrisierung Trick“ maximiert werden.
Eine Kalkulationstabelle wird für die Inferenzverteilung verwendet, deren Mittelwert und Varianz die Ausgaben eines neuronalen Netzwerks sind, das als Eingabe die Darstellung des Dokuments in Form von Wörtern verwendet.
Dank des vorherigen Trainingsziels lernt die Inferenzverteilung, sich mit dem wahren, aber nicht rückgängig zu machen, d. h. *qθ*(**z**∣**x**)≃*p*(**z**∣**x**), zu nähern. Dies bedeutet, dass wir nach dem Trainieren des Modells die Inferenzverteilung verwenden können, um die Themen zu finden, denen ein Dokument zugewiesen wurde.
Wenn Sie den Mittelwert der Inferenzverteilung verwenden und die Softmax-Funktion anwenden (wie in Schritt 2 des vorherigen generativen Prozesses), werden die ungefähren Anteile des späteren Themas für ein bestimmtes Dokument ermittelt.
Ein Beispiel aus der Praxis
Wir trainieren einen ETM auf dem Dataset der 20 Nachrichtengruppen , das Kommentare aus Diskussionsforen zu 20 hierarchischen Themen enthält, die wie folgt kategorisiert wurden:
- Computer: Comp. Graphics, Comp.os.ms-windows.misc, Comp.sys.ibm.pc.hardware, Comp.sys.mac.hardware, Comp.windows.x
- Neuerstellung: Rec.autos, Modellen von Modellen, Modellen, Modellen, Robot, Robot, Rec.port.hokey
- Science: sci.crypt, sci. Electrons, sci.ung, sci.space
- Richtlinien: Unterhaltung.policies.misc Unterhaltung.policies,. chat.policies.m zugänglich
- Symbol: Unterhaltung.religion.misc, alt.atheism, soc.religion. Liste
- Sonstiges: misc.forsale
Bei Communications Mining arbeiten wir ausschließlich mit Kommunikationsdaten, die bekanntlich privat sind. Für Reproduzierbarkeit und da es das am häufigsten verwendete Dataset zur Themenmodellierung in der Forschungsarbeit zu Machine Learning ist, verwenden wir hier das Dataset mit 20 Nachrichtengruppen. Dies gilt als die „Hello-Welt“ der Themenmodellierung.
Wir trainieren das Modell mit 20 Themen (d. h K = 20), da wir für dieses Dataset bereits wissen, wie viele Themen es gibt (aber im Allgemeinen wird dies nicht der Fall sein). Wir verwenden Globale , um die Einbettungsmatrix U zu initialisieren.
Die folgende Abbildung zeigt die 10 wichtigsten Wörter, die für jedes Thema gelernt wurden, und die Anzahl der Dokumente, die jedes Thema als wahrscheinlichstes haben:
Wahrscheinlichste Wörter für jedes Thema, das der ETM gelernt hat
Die gelernten Top-Wörter stimmen im Allgemeinen mit den wahren Themen im Dataset überein, z. B Thema 2 = Unterhaltung.policies.zugs, Thema 13 = Sci.space, usw. Für jedes Dokument können wir auch die Wahrscheinlichkeiten für die Themenzuweisung anzeigen; Einige Beispiele werden in den folgenden Abschnitten gezeigt. Bestimmte Dokumente haben eine hohe Wahrscheinlichkeit für ein einzelnes Thema, während andere Dokumente Mischungen aus mehreren Themen sind.
Beispiel 1
Es mag ein oder aus dem GIF-Format konvertieren, aber während ich Dinge wie tgif, die GIF-Dateien bearbeiten kann, und verschiedene Tools zum Konvertieren in das/aus dem GIF-Format gefunden habe, konnte ich kein Programm finden, das einfach ein Fenster öffnet und eine GIF-Datei anzeigt enthalten sind. Ich habe verschiedene FAQ-Dateien durchsucht, auch ohne Erfolg. Speichert eines in einem Archiv? Nichts Anspruchsvoll; nur „das Schöne Bild zeigen“?
Alternativ: Wenn ich die Spezifikationen für GIF finden könnte, könnte es nicht zu schwierig sein, sie selbst zu schreiben, aber ich habe keine Idee, wo ich überhaupt nach der Spezifikation suchen soll. (Nun,trigger) Holen Sie sich, xv, Version 3.0. Es liest/zeigt/manipuliert viele verschiedene Formate.
Beispiel 2
Der Zielwart, auf den Sie sich beziehen, ist CLInt Malarchuk. Er spielt zu dieser Zeit bei den Sabres. Sein Team unmittelbar zuvor waren die Washington Hauptsitze. Während er sich erholt hat und weiterspielte, weiß ich nicht, wo er sich befindet.
Beispiel 3
Hallo out in net world, wir haben ein Lab mit alten Macs (SEs und Pluses). Wir haben nicht genug Geld, um alle neuen Maschinen zu kaufen, deshalb erwägen wir, ein paar Superdrives für unsere alten Macs zu kaufen, damit Benutzer mit hoher Festplattendichte unsere Geräte verwenden können. Ich frage mich, welche (guten oder schlechten) Erfahrungen mit dieser Art von Upgrade gemacht wurden. urry
Auch ohne im Voraus etwas über das Dataset zu wissen, zeigen diese Ergebnisse, dass es möglich ist, sich schnell und einfach einen Überblick über das Dataset zu verschaffen, zu identifizieren, zu welchen Themen jedes Dokument gehört, und ähnliche Dokumente zusammenzufassen. Wenn wir auch mit Anmerkungen versehene Daten sammeln möchten, um eine überwachte Aufgabe zu trainieren, können wir anhand der Ausgaben des Themenmodells mit der Anmerkung aus einer fundierten Perspektive beginnen.
Baumstrukturierte Themenmodelle
Obwohl Themenmodelle, wie im vorherigen Abschnitt beschrieben, sehr nützlich sein können, haben sie bestimmte Einschränkungen:
- Die Anzahl der Themen muss im Voraus angegeben werden. Im Allgemeinen werden wir nicht wissen, wie die richtige Zahl sein soll.
- Es ist zwar möglich, mehrere Modelle mit unterschiedlicher Anzahl von Themen zu trainieren und das beste auszuwählen, aber das ist kostspielig.
- Auch wenn wir die richtige Anzahl der Themen kennen, entsprechen die erlernten Themen möglicherweise nicht den richtigen, z. B Thema 16 in Abbildung 1 scheint keinem der wahren Themen im Dataset „20 Newsgroups“ zu entsprechen.
- Das Modell erfasst nicht, wie die Themen miteinander zusammenhängen. In Abbildung 1 gibt es beispielsweise mehrere Themen über Computing, aber die Idee, dass diese zusammenhängen, wird vom Modell nicht gelernt.
In der Praxis ist es normalerweise so, dass die Anzahl der Themen im Voraus unbekannt ist und die Themen in irgendeiner Weise miteinander zusammenhängen. Eine Methode, um diese Probleme zu beheben, besteht darin, jedes Thema als Knoten in einer Struktur darzustellen. Dadurch können wir die Beziehungen zwischen Themen modellieren; verwandte Themen können sich im selben Teil der Struktur befinden.
Dies würde Ausgaben liefern, die viel einfacher zu interpretieren sind. Wenn das Modell aus den Daten lernen kann, wie viele Themen es geben sollte und wie sie miteinander zusammenhängen, müssen wir nichts davon im Voraus wissen.
Dazu verwenden wir ein Modell, das auf dem Tree-Struktured Neural Topic Model (TSNTM) basiert . Der generative Prozess funktioniert durch die Auswahl eines Pfads vom Stamm der Struktur zu einem Blatt und die Auswahl eines Knotens entlang dieses Pfads. Die Wahrscheinlichkeiten über die Pfade der Baumstruktur werden mit einem Stick-Breaking-Prozess modelliert, der mit einem doppelt wiederkehrenden neuronalen Netzwerk parametrisiert wird.
Stick-Break-Prozesse
Der Stick-Break-Prozess kann verwendet werden, um die Wahrscheinlichkeiten über die Pfade einer Struktur zu modellieren. Intuitiv beinhaltet dies wiederholtes Abbrechen eines Sticks, der ursprünglich die Länge 1 hat. Der Anteil des Sticks, der einem Knoten in der Baumstruktur entspricht, stellt die Wahrscheinlichkeit auf diesem Pfad dar.
Der Stick-Break-Prozess, mit Proportionen in Grün
Betrachten Sie zum Beispiel die Struktur in Abbildung 2, mit 2 Ebenen und 2 untergeordneten Elementen auf jeder Ebene. Am Stammknoten ist die Stick-Länge 1. Es wird dann in zwei Teile mit einer Länge von 0,7 bzw. 0,3 unterteilt. Jedes dieser Teile wird dann weiter aufgeschlüsselt, bis wir die Blätter des Baums erreichen. Da wir den Stick weiter brechen können, kann die Struktur beliebig breit und tief sein.
Doppelt wiederkehrende neuronale Netzwerke
Wie beim ETM beginnt der generative Prozess des TSNTM mit der Stichprobe der verborgenen Darstellung z aus der vorherigen Verteilung:
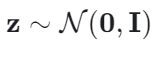
Ein doppelt wiederkehrendes neuronales Netzwerk (DRNN) wird verwendet, um die Stick-Brows-Ananteile zu bestimmen. Nach der zufälligen Initialisierung des ausgeblendeten Status des Stammknotens, h1`, ist der ausgeblendete Zustand des Stammknotensfür jedes Thema k vorgegeben durch:
wobei hpar(k) der ausgeblendete Status des übergeordneten Knotens und hk-1 der ausgeblendete Status des unmittelbar vorangegangenen gleichgeordneten Knotens ist (gleichgeordnete Knoten werden basierend auf ihrem ursprünglichen Index sortiert).
Der Anteil des verbleibenden Sticks, der dem Thema k,vk zugeordnet ist, ist vorgegeben durch:
Dann ist die Wahrscheinlichkeit an Knoten k,πk gegeben durch
wobei j∈{{1,…,k–1} die vorangegangenen gleichgeordneten Elemente des Knotens k sind. Das sind die grünen Werte in Abbildung 2. Der Wert an jedem Blattknoten ist die Wahrscheinlichkeit für diesen Pfad (es gibt nur einen Pfad zu jedem Blattknoten).
Da wir nun Wahrscheinlichkeiten über die Pfade der Struktur haben, benötigen wir Wahrscheinlichkeiten über Knoten innerhalb jedes Pfads. Diese werden mit einem anderen Stick-Breaking-Prozess berechnet. Auf jeder Ebene der Struktur ist der ausgeblendete Zustandgegeben durch:
Das bedeutet, dass alle Knoten auf derselben Ebene der Struktur denselben Wert für gl haben.
Der Anteil des verbleibenden Sticks, der der Ebene l,nl zugeordnet ist, ist vorgegeben durch:
Die Wahrscheinlichkeit auf Ebene l,θl ist gegeben durch:
Empirisch haben wir manchmal gefunden, dass die wahrscheinlichsten Wörter für untergeordnete Knoten in der Struktur semantisch nicht mit denen ihrer übergeordneten Knoten zusammenhängen. Um dies zu beheben, wenden wir in Gleichung 2 eine Temperierung an, um das Sigmoberfläche abzusoften:
In unseren Experimenten haben wir ψ=0,1 festgelegt. Dies macht es wahrscheinlicher, dass, wenn die Wahrscheinlichkeitsmenge eines untergeordneten Knotens nicht null ist, dies auch für die übergeordneten Knoten der Fall ist (und die Wahrscheinlichkeit wird verringert, dass untergeordnete Knoten nicht mehr mit ihren übergeordneten Elementen zusammenhängen).
Training und Inferenz
Das Trainingsziel bleibt das gleiche wie in Gleichung 1; Die einzige Änderung besteht darin, wie p(xw=vw|z) angegeben wird. Dies ist nun gegeben durch:
Aktualisieren der Baumstruktur
Bisher wurde die Baumstruktur repariert. Wir möchten jedoch, dass dies basierend auf den Daten erlernt wird. Die genaue Angabe der Struktur der Struktur als Hyperparameter ist viel schwieriger als die einfache Angabe einer Reihe von Themen, wie es bei einem niedrigen Themenmodell der Fall ist. Wenn wir die allgemeine Struktur der Struktur im Voraus kannten, müssten wir die Themen wahrscheinlich nicht modellieren.
Daher müssen praktische Anwendungen von strukturstrukturierten Themenmodellen die Struktur aus Daten lernen. Dazu werden zwei heuristischen Regeln zum Hinzufügen und Löschen von Knoten zur und aus der Struktur verwendet. Zunächst wird die Gesamtwahrscheinlichkeitsmasse an jedem Knoten mithilfe einer zufälligen Teilmenge der Trainingsdaten geschätzt. Bei Knoten k lautet diese Schätzung:
wobei d={1,…,D} die zufällig ausgewählte Teilmenge von Dokumenten indiziert und Nd die Anzahl der Wörter im Dokument d ist. Basierend auf diesen Schätzungen nach jeder I- Iteration:
- Wenn pk über einem Schwellenwert liegt, wird ein untergeordnetes Element unterhalb von Knoten k hinzugefügt, um das Thema zu verfeinern.
- Wenn die kumulative Summe
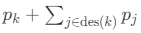 ist kleiner als ein Schwellenwert, dann werden Knoten k und seine Nachfolger gelöscht.
ist kleiner als ein Schwellenwert, dann werden Knoten k und seine Nachfolger gelöscht.
Ergebnisse für 20 Nachrichtengruppen
Wir führen den TSNTM auf demselben Dataset aus 20 Nachrichtengruppen aus, der für das Training des ETM oben verwendet wird. Wir initialisieren die Struktur mit 2 Ebenen mit 3 untergeordneten Elementen auf jeder Ebene. Die folgende Abbildung zeigt die endgültige Baumstruktur, die 10 wichtigsten Wörter, die für jedes Thema gelernt wurden, und die Anzahl der Dokumente, die jedes Thema als wahrscheinlichstes haben:
Wahrscheinlichste Wörter für jedes Thema, das der TNSTM gelernt hat
Im Vergleich zum einfachen Themenmodell hat der strukturstrukturierte Ansatz klare Vorteile. Die Struktur wird automatisch aus den Daten erlernt, wobei ähnliche Themen in verschiedenen Teilen der Struktur gruppiert werden.
Die Themen auf höchster Ebene befinden sich oben in der Struktur (z. B uninformative Wörter, die in vielen Dokumenten vorkommen, stehen am Stammplatz) und die verfeinerten/spezifischeren Themen stehen an den Blättern. Dies führt zu Ergebnissen, die viel informativer und einfacher zu interpretieren sind als die einfache Modellausgabe in Abbildung 1.
Beispieldokumente und die zugehörigen Wahrscheinlichkeiten für die Themenzuweisung, die vom TSNTM erlernt wurden, werden in den folgenden Abschnitten angezeigt:
Beispiel 1
Wir haben gerade einen AppleOne Farbscanner für unser Labor erhalten. Ich habe jedoch Probleme, eine angemessene gescannte Ausgabe zu erhalten, wenn ich ein gescanntes Foto auf einem Layouter IIg drucken kann. Ich habe versucht, mit einer höheren Auflösung zu scannen, und die Anzeige auf dem Bildschirm sieht sehr gut aus. Aber die gedruckte Version ist mangelhaft!
Ist dies auf die Auflösungsfähigkeit des Roboters zurückzuführen? Oder gibt es Tricks, um eine bessere Qualität zu erzielen? Oder sollten wir uns etwas (z. B. Workflow- Workflow-up-daten)merken, um das Bild „ausdaten“ zu verbessern? Ich bin für alle Vorschläge bereit. Vielen Dank im Voraus, -Kris
Beispiel 2
Es ist aus – dieabondieren – dieab mehr sie sie befelden mit OT 6-5 die Nutzung für die Defenin der Serie. Ein großartiges Ziel vongeaby (Lakontaine hat ihn eingerichtet, während er sich auf dem Ice festgelegt hat) beendete das Projekt. Fuhrzeit hat sich mit einer Seitenverletzung aus dem Einsatz zurück/ Die Releases erhalten jedoch eine Woche Pause, sodass Verstöße kein Problem sein sollten.
Kanada setzt sich mit 3:2 von Kanada zurück, um ihre Serie zu geändert, die auf Regel 7 zu zugreifen scheint. Die Habens dominieren die ersten beiden Phasen und hatten PLZ, dass sie erst nach 40 Minuten ein 2:2-Ungleiche aufstanden. Ein frühes Ziel von Brunet im 3.
Die Islanders haben ihr 3. OT-Rolle der Serie durch ein Ziel von Tryan Zugriff mit 4:3 gewonnen; Die Caps wurden einfach reduziert, nachdem im 2. die „3:0“-Führung übernommen wurde. Der Gesamtzeit-Record für die Playoffs der Orchestra-Ins Dies ist jetzt 28-7.
Beispiel 3
Bitte sagen Sie mir, wo ich eine CD des Labels Wergo Orchestrator für weniger als 20 USD bekommen kann.
Dokumente, die eindeutig in ein bestimmtes Thema fallen (z. B. das erste) haben eine hohe Wahrscheinlichkeit an einem Blattknoten, während Dokumente, die eindeutig unter keines der gelernten Themen fallen (z. B. das dritte), eine hohe Wahrscheinlichkeit am Stammknoten haben .
Quantative Auswertung
Themenmodelle sind bekanntlich schwierig quantifiziert zu bewerten. Dennoch ist die gängigste Metrik zur Messung der Themenkohärenz die Normalized Point aktuell Tutorial Information (JPMI). Bei den ersten M Wörtern für jedes Thema ist der VPN-Auftrag hoch, wenn jedes Wortpaar wi und wj eine hohe gemeinsame Wahrscheinlichkeit P(wi,wj) im Vergleich zu ihren Randwahrscheinlichkeiten P(wi) und P(wj) hat:
Die Wahrscheinlichkeiten werden mithilfe von empirischen Zählungen geschätzt.
| NPMI | |
|---|---|
| ETM | 0.193 |
| TSNTM | 0.227 |
Diese Ergebnisse unterstützen die qualitativen Ergebnisse, dass das TNTM ein kohärentes Modell ist als das ETM.
Integrieren von Transformern
Obwohl das TSNTM intuitive und leicht zu interpretierende Ergebnisse liefert, weist das erlernte Modell immer noch Schwachstellen auf. In Abbildung 3 wurden beispielsweise die Themen im Zusammenhang mit Richtlinien und Platz unter demselben übergeordneten Knoten gruppiert. Das ist vielleicht nicht unangemessen, aber ihr übergeordneter Knoten bezieht sich auf die Revision, die möglicherweise nicht kohärent ist.
Ein weiteres, subtileres Beispiel ist, dass Thema 1.3 Rechenthemen im Zusammenhang mit Hardware sowie Software zusammenfasst; vielleicht sollten diese getrennt werden.
Wir nehmen an, dass diese Probleme darauf zurückzuführen sind, dass die bisher trainierten Modelle auf (nicht kontextbezogenen) Globale-Einbettungen basieren. Dies kann es schwierig machen, Wörter eindeutig zu machen, die in verschiedenen Kontexten unterschiedliche Bedeutung haben. In den letzten Jahren haben Transformer-basierte Modelle eine bahnbrechende Leistung beim Lernen von informativen, kontextbezogenen Textdarstellungen erreicht. Wir möchten Transformer-Einbettungen in den TSMnTM integrieren.
Hinzufügen von Transformer-Einbettungen zum TSNTM
Wir folgen dem Ansatz des Combined Topic Model (CTM). Anstatt nur die Darstellung der Taschen-of-Words als Eingabe für das Inferenzmodell zu verwenden, verketten wir jetzt die Darstellung der Taschen-of-Words mit dem Mittelwert der endgültigen Ebenenzustände eines Transformer-Modells. Obwohl dies eine einfache Änderung ist, sollte das Inferenzmodell eine bessere spätere Approachion lernen können.
Für das Transformer-Modell verwenden wir die all-mpnet-base-v2 -Variante von Sentence-BERT (SBERT), da es bei einer Reihe von Aufgaben auf Satzebene konsistent hohe Punktzahlen erreicht.
Wir trainieren ein Modell, das ansonsten identisch mit dem TSNTM aus dem vorherigen Abschnitt ist, mit Ausnahme der SBERT-Einbettungen, die dem Inferenzmodell hinzugefügt werden. Die folgende Abbildung zeigt auch hier die 10 wichtigsten Wörter, die für jedes Thema gelernt wurden, und die Anzahl der Dokumente, die jedes Thema als wahrscheinlichstes haben:
Wahrscheinlichste Wörter für jedes von SBERT+TSNTM gelernte Thema
Das TSNTM mit den SBERT-Einbettungen scheint einige der Inkonsistenzprobleme des Nur-GloVe-Modells zu beheben. Die Themen Revision, Richtlinien und Verschlüsselung sind jetzt unter demselben übergeordneten Thema gruppiert. Aber im Gegensatz zum Nur-GloVe-Modell ist dieses übergeordnete Element jetzt ein allgemeineres Thema, dessen sich wichtigsten Wörter auf Personen beziehen, die Empfehlungen zulassen.
Die Themen Computer-Hardware und Software wurden nun aufgeteilt und der Platz befindet sich in einem eigenen Teil der Struktur. Der VPN-Einbettung deutet auch darauf hin, dass das Modell mit den SBERT-Einbettungen kohärenter ist:
| NPMI | |
|---|---|
| ETM | 0.193 |
| TSNTM (nur GloVe) | 0.227 |
| TSNTM (GloVe + SBERT) | 0.234 |
Zusammenfassung
Wir haben gezeigt, dass Themenmodelle eine großartige Möglichkeit sein können, ein hohes Verständnis für ein Dataset zu erhalten, ohne Anmerkungen vornehmen zu müssen.
- „Flat“-Themenmodelle werden am häufigsten verwendet, haben aber Schwachstellen (z. B die Ausgabe ist nicht am einfachsten zu interpretieren, da die Anzahl der Themen im Voraus bekannt sein muss).
- Diese Schwachstellen können behoben werden, indem ein Modell mit Baumstruktur verwendet wird, das verwandte Themen zusammenfasst und die Themenstruktur automatisch von den Daten lernt.
- Die Modellierungsergebnisse können durch die Verwendung von Transformer-Einbettungen weiter verbessert werden.
Wenn Sie Communications Mining™ in Ihrem Unternehmen ausprobieren möchten, registrieren Sie sich für eine Testversion oder sehen Sie sich eine Demo an .
- Zusammenfassung
- Hintergrund
- Eingebettete Themenmodelle
- Training und Inferenz
- Ein Beispiel aus der Praxis
- Beispiel 1
- Beispiel 2
- Beispiel 3
- Baumstrukturierte Themenmodelle
- Stick-Break-Prozesse
- Doppelt wiederkehrende neuronale Netzwerke
- Training und Inferenz
- Aktualisieren der Baumstruktur
- Ergebnisse für 20 Nachrichtengruppen
- Beispiel 1
- Beispiel 2
- Beispiel 3
- Quantative Auswertung
- Integrieren von Transformern
- Hinzufügen von Transformer-Einbettungen zum TSNTM
- Zusammenfassung