- はじめに
- アクセス制御と管理
- ソースとデータセットを管理する
- モデルのトレーニングと保守
- 生成 AI による抽出
- 分析と監視を使用する
- オートメーションと Communications Mining™
- 開発者
- 機械が単語を理解する方法:NLPに埋め込むためのガイド
- トランスフォーマーによるプロンプトベースの学習
- 効率的な変圧器II:知識蒸留と微調整
- 効率的な変圧器I:注意メカニズム
- 階層的な教師なしインテントモデリング:トレーニングデータなしで価値を得る
- Communications Mining™ でアノテーションの偏りを修正する
- アクティブ ラーニング: より優れた ML モデルを短時間で実現
- それはすべて数字にあります-メトリックを使用してモデルのパフォーマンスを評価します
- モデルの検証が重要な理由
- 対話データ分析 AI としての Communications Mining™ と Google AutoML を比較する
- ライセンス
- よくある質問など
Automation Cloud の IXP での教師なしインテントの深層モデリング。トレーニング データなしでコミュニケーションから価値を抽出します。
ビジネスはコミュニケーションで運営されており、顧客は何か欲しいときに連絡を取り、同僚は仕事を成し遂げるためにコミュニケーションを取ります。すべてのメッセージが重要です。Communications Mining™ の使命は、これらのメッセージから価値を引き出し、企業のすべてのチームが、より優れた製品とサービスを効率的かつ大規模に提供できるよう支援することです。
この目標のもと、UiPath はコアとなる機械学習と自然言語理解の技術を継続的に研究開発しています。Communications Mining のマシン ラーニング モデルは、事前トレーニング、教師なし学習、半教師あり学習、 アクティブ ラーニング を使用して、ユーザーの時間と投資を最小限に抑えながら、最先端の精度を提供します。
この研究投稿では、コミュニケーションデータセットからトピックと意図、およびそれらの分類構造を自動的に認識するための新しい教師なしアプローチを探ります。 それは、私たちが提供する洞察の質とそれらが取得される速度を向上させることです。
要約
トピック モデルは、"ドキュメント" のコレクションで発生する "トピック" を検出するためのメソッドのクラスです。重要なのは、トピック モデルは、アノテーション 付きのトレーニングデータを収集しなくても機能するということです。データセット内のトピックと、各ドキュメントに表示されるトピックを自動的に識別します。
架空の「失敗した取引」メールと、自動的に推測したい階層トピックの種類
この投稿の内容:
- 従来のトピックモデルについて説明し、トピックの数を事前に知る必要がある、トピック間の関係がキャプチャされていないなど、それらの弱点のいくつかについて説明します。
- トピックは階層に編成されます。この階層は、データセットのトピック構造に基づいて 自動的に 推測されます。階層は、意味的に関連するトピックをグループ化します。
- Transformerベースの埋め込みをモデルに組み込むことで、より一貫性のあるトピック階層を実現します。
背景
トピック モデルでは、データセット (ドキュメントのコレクション) に一連のトピックが含まれていることを前提としています。 トピックは、各単語がドキュメント内で出現する可能性を指定します。 データセット内の各ドキュメントは、トピックの組み合わせから生成されます。 一般に、一緒に頻繁に発生する単語のセットは、特定のトピックで高い確率を持ちます。
たとえば、次のドキュメントで構成されるデータセットがあるとします。
- 資料1:「犬はオオカミの飼いならされた子孫である」
- 資料2:「ネコはひげと引き込み式の爪を持つ肉食哺乳類である」
- 資料3:「大型ネコ科動物が犬を襲うことが知られている」
- 資料4:「猫の鋭い爪で引っ掻かれた後、猫を怖がる犬もいる」
- 資料5:「飼いならされた犬は他の犬よりも猫の存在を好むかもしれない」
これらのドキュメントでトレーニングされたトピック モデルは、次のトピックとドキュメント トピックの割り当てを学習できます。
| トピック1 | トピック 2 |
|---|---|
| イヌ | 猫 |
| 家畜 | 爪 |
| オオカミ | 鬚 |
| ... | ... |
最も高い確率で並べ替えられた単語を含むトピックの例。
| トピック1 | トピック 2 | |
|---|---|---|
| 資料1 | 100% | 0% |
| 資料2 | 0% | 100% |
| 資料3 | 50% | 50% |
| 資料4 | 33% | 67% |
| 資料5 | 67% | 33% |
ドキュメントとトピックの割り当ての例。
各トピックで最も可能性の高い単語と、各ドキュメントが属するトピックを表示すると、データセット内のテキストの内容と、互いに類似しているドキュメントの概要が表示されます。
埋め込みトピックモデル
標準的なトピックモデルは、 潜在的ディリクレ配分(LDA)と呼ばれます。これは、(近似的な) 最尤推定を使用してトレーニングされた生成モデルです。LDA は、次のことを前提としています。
- K 個のトピックがあり、それぞれが語彙 (データセット内の単語のセット) の分布を指定します。
- 各ドキュメント(単語のコレクション)には、トピック全体に分布しています。
- ドキュメント内の各単語は、トピックに対するドキュメントの分布とボキャブラリに対するトピックの分布に従って、1 つのトピックから生成されます。
最新のトピック モデルのほとんどは LDA 上に構築されています。最初は、 Embedded Topic Model(ETM)に焦点を当てます。ETM では、埋め込みを使用して単語とトピックの両方を表します。従来のトピックモデリングでは、各トピックは語彙全体にわたって完全に分布しています。ただし、ETM では、各トピックは埋め込み空間のベクトルです。トピックごとに、ETM はトピック埋め込みを使用して語彙全体の分布を形成します。
トレーニングと推論
ドキュメントの生成プロセスは次のとおりです。
-
前の分布から潜在的な表現zをサンプリングします:z∼N(0,I)。
-
トピックの比率 θ=softmax(z) を計算します。
-
ドキュメント内の各単語 w に対して、次の操作を行います。
- 潜在的なトピックの割り当てのサンプル
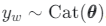 2. 単語をサンプリングする
2. 単語をサンプリングする
ここで∈ RV×E は埋め込み行列という単語で、tyw ∈ RE はトピック yw の埋め込みです。これらはモデルのパラメーターです。V は語彙の単語数、 E は埋め込みサイズです。
単語 v 1,v2,...,vw を含むドキュメントの対数尤度は、次のようになります。
各項目の説明:
残念ながら、前述の積分は扱いにくいです。したがって、対数尤度を直接最大化することは簡単ではありません。代わりに、変分推論を使用して近似的に最大化されます。これを行うには、「推論」分布qθ( z ∣ x)(パラメーター φ を使用)を使用して、 x = x1 ,...,xWの場合、 ジェンセンの不等式 に基づく対数尤度の下限を形成します。
この下限は、いわゆる 「再パラメータ化トリック」による勾配のモンテカルロ近似を使用して最大化できるようになりました。
ガウス分布は推論分布に使用され、その平均と分散は、ドキュメントの単語表現のバッグを入力として受け取るニューラルネットワークの出力です。
前の学習目標のおかげで、推論分布は、真の、しかし手に負えない事後、すなわち *qθ*(**z**∣**x**)≃*p*(**z**∣**x**)を近似するように学習します。つまり、モデルをトレーニングすると、推論の分布を使用して、ドキュメントが割り当てられているトピックを見つけることができます。
推論分布の平均を取り、ソフトマックス関数 (前の生成プロセスのステップ 2 に従って) を適用すると、特定のドキュメントのおおよその事後トピック比率が得られます。
実例
20のニュースグループデータセットでETMをトレーニングし、20の階層トピックに関するディスカッションフォーラムからのコメントを次のように分類します。
- コンピューティング: comp.graphics,comp.os.ms-windows.misc、comp.sys.ibm.pc.hardware、comp.sys.mac.hardware、comp.windows.x
- レクリエーション: rec.autos、rec.motorcycles、rec.sport.baseball、rec.sport.hockey
- 科学: sci.crypt、sci.electronics、sci.med、sci.space
- 政治: talk.politics.misc,talk.politics.gunsさん、talk.politics.mideast
- 宗教: talk.religion.misc,alt.無神論、soc.religion.christian
- その他: misc.forsale
Communications Mining では、プライベートなことで有名なコミュニケーション データのみを処理します。再現性のために、また機械学習研究文献で最も一般的に使用されるトピックモデリングデータセットであるため、ここでは20のニュースグループデータセットを使用します。これは、トピックモデリングの 「ハローワールド」 と見なされます。
20 個のトピック (つまり、K = 20)は、このデータセットでは、トピックの数がすでにわかっているためです(ただし、一般的にはそうではありません)。GloVeを使用して、埋め込み行列Uを初期化します。
次の図は、各トピックで学習された上位 10 個の単語と、各トピックを最も可能性の高いトピックとして含むドキュメントの数を示しています。
ETMによって学習された各トピックの最も可能性の高い単語
学習した上位の単語は、データセット内の真のトピックとほぼ一致します。たとえば、トピック2 = talk.politics.guns、トピック13 = sci.space、等。各ドキュメントについて、トピックの割り当て確率を表示することもできます。次のセクションにいくつかのサンプルを示します。特定のドキュメントは 1 つのトピックに対して高い確率で記述されていますが、他のドキュメントは複数のトピックが混在しています。
例 1
ばかげているようですが、gifファイルを編集できるtgifや、gif形式との間で変換するためのさまざまなツールなどを見つけましたが、ウィンドウを開いてgifファイルを表示するだけのプログラムを見つけることができませんでした。私はさまざまなFAQファイルを調べましたが、役に立ちませんでした。どこかのアーカイブに潜んでいるものはありますか?洗練されたものは何もありません。単に「きれいな絵を見せる」だけですか?
あるいは、gifの仕様を見つけることができれば、自分で書くのはそれほど難しくないと思いますが、どこから仕様を探し始めればよいのかさえわかりません。(ええと、実は、私にはアイデアがあります - このニュースグループ。-)Get、xv、バージョン3.0。さまざまな形式を読み取ったり、表示したり、操作したりします。
例 2
あなたが紹介するゴールキーパーはクリント・マラルチュクです。 彼はその時セイバーズで遊んでいました。 その直前の彼のチームはワシントンキャピタルズでした。 彼は回復してプレーを続けていますが、私は彼の現在の所在を知りません。
例 3
ネットワールドでこんにちは、私たちは古いMac(SEとプラス)のラボを持っています。 すべての新しいマシンを購入するのに十分なお金がないので、高密度ディスクを持っている人々が私たちの機器を使用できるように、古いMac用にいくつかのスーパードライブを購入することを検討しています。 私はこの種のアップグレードで人々がどのような経験(良いか悪いか)をしたのか疑問に思っていました。 マレー
事前にデータセットについて何も知らなくても、データセットの概要をすばやく簡単に把握し、各ドキュメントがどのトピックに属しているかを特定し、類似したドキュメントをグループ化できることがわかりました。 教師ありタスクをトレーニングするために注釈付きデータも収集する場合は、トピックモデルの出力により、より多くの情報に基づいた視点から注釈付けを開始できます。
ツリー構造のトピック・モデル
前のセクションで説明したトピック モデルは非常に便利ですが、特定の制限があります。
- トピックの数は事前に指定する必要があります。 一般に、正しい番号がどうあるべきかはわかりません。
- トピックの数が異なる複数のモデルをトレーニングし、最適なモデルを選択することは可能ですが、これにはコストがかかります。
- トピックの正しい数がわかっていても、学習したトピックが正しいトピックに対応していない場合があります。 図 1 のトピック 16 は、20 のニュースグループ データセットの実際のトピックのいずれにも対応していないようです。
- このモデルでは、トピックが互いにどのように関連しているかはキャプチャされません。 たとえば、図 1 にはコンピューティングに関するトピックが複数ありますが、これらが関連しているという考えは、モデルでは学習されません。
実際には、トピックの数は事前に不明であり、トピックは互いに何らかの形で関連しているのが普通です。これらの問題に対処する方法の1つは、各トピックをツリーのノードとして表すことです。これにより、トピック間の関係をモデル化できます。関連トピックは、ツリーの同じ部分に含めることができます。
これにより、解釈しやすい出力が得られます。さらに、モデルがデータから、いくつのトピックがあり、それらが互いにどのように関連しているかを学習できるのであれば、事前に知る必要はありません。
これを実現するために、 Tree-Structured Neural Topic Model(TSNTM)に基づくモデルを使用します。生成プロセスは、木の根から葉へのパスを選択し、そのパスに沿ったノードを選択することによって機能します。木の経路上の確率は、二重回帰ニューラルネットワークを使用してパラメータ化されるスティックブレイキングプロセスを使用してモデル化されます。
スティックブレークプロセス
スティックブレイキングプロセスは、木の経路上の確率をモデル化するために使用できます。直感的には、これは最初は長さ1の棒を繰り返し折ることを含みます。ツリー内のノードに対応するスティックの割合は、そのパスに沿った確率を表します。
緑色のプロポーションを持つスティックブレイクプロセス
たとえば、図 2 のツリーで、各層に 2 つのレイヤーと 2 つの子があるとします。 ルートノードでは、スティックの長さは1です。 次に、それぞれ長さ0.7と0.3の2つの部分に分割されます。 次に、これらの各ピースは、木の葉に到達するまでさらに分解されます。 棒を折り続けることができるので、木は任意に広くて深くすることができます。
二重リカレントニューラルネットワーク
ETMと同様に、TSNTMの生成過程は、先行分布から潜在表現 z をサンプリングすることから始まる。
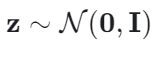
二重回帰ニューラルネットワーク(DRNN)を使用して、スティック破断の比率を決定します。ルートノードの隠れ状態 h1をランダムに初期化した後、各トピック k について、隠れ状態 hkは次式で与えられます。
ここで、 hpar(k) は親ノードの隠れ状態、 hk-1 は直前の兄弟ノードの隠れ状態です (兄弟は初期インデックスに基づいて順序付けられます)。
トピックk,vkに割り当てられた残りのスティックの割合は、次式で与えられます。
すると、ノード k,πk における確率は次式で与えられます。
ここで、j∈{1,...,k−1} はノード k の先行する兄弟です。これらは、図2の緑色の値です。各リーフ ノードの値は、そのパスの確率です (各リーフ ノードへのパスは 1 つだけです)。
ツリーのパスに対する確率が得られたので、各パス内のノードに対する確率が必要です。これらは、別のスティック破断プロセスを使用して計算されます。ツリーの各レベルで、隠れ状態 gl は次式で与えられます。
これは、ツリーの同じレベルにあるすべてのノードが gl に対して同じ値を持つことを意味します。
レベルl,nlに割り当てられた残りのスティックの割合は、次式で与えられます。
水準 l,θl での確率は次式で与えられます。
経験的に、ツリー内の子ノードにとって最も可能性の高い単語は、意味的に親の単語とは無関係であることが時々わかりました。 これに対処するために、式2ではシグモイドを柔らかくするために温度を適用します。
実験では、ψ=0.1 に設定しました。 これにより、子ノードの確率質量がゼロ以外の場合、その親もゼロになる可能性が高くなります(子ノードが親と無関係になる可能性が低くなります)。
トレーニングと推論
トレーニング目標は式1と同じです。唯一の変更は、p(xw=vw|z) の指定方法です。 これは現在、次のように指定されています。
ツリー構造の更新
これまでのところ、ツリー構造は修正されています。しかし、これはデータに基づいて学習されることを望んでいます。ツリーの正確な構造をハイパーパラメータとして指定することは、フラットなトピックモデルの場合のように、単にトピックの数を指定するよりもはるかに困難です。ツリーの一般的な構造を事前に知っていれば、トピックをモデル化する必要はないでしょう。
したがって、ツリー構造トピックモデルの実用的なアプリケーションは、データから構造を学習できる必要があります。これを行うには、ツリーへのノードの追加とツリーからのノードの削除に 2 つのヒューリスティック ルールが使用されます。まず、各ノードの合計確率質量を、学習データのランダムなサブセットを使用して推定します。ノード k では、この推定値は次のようになります。
ここで、d={1,...,D}はランダムに選択されたドキュメントのサブセットをインデックス化し、Ndはドキュメントdの単語数です。これらの推定値に基づいて、 I の反復ごとに:
- pk がしきい値を超えると、トピックを絞り込むためにノード k の下に子が追加されます。
- 累積合計
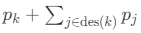 がしきい値未満の場合、ノード k とその子孫は削除されます。
がしきい値未満の場合、ノード k とその子孫は削除されます。
20 のニュースグループの結果
上記のETMのトレーニングに使用したのと同じ20のニュースグループデータセットでTSNTMを実行します。ツリーを初期化して、各レイヤーに 3 つの子を持つ 2 つのレイヤーを持ちます。次の図は、最終的なツリー構造、各トピックで学習した上位 10 個の単語、および各トピックを最も可能性の高いトピックとして含むドキュメントの数を示しています。
TSNTMによって学習された各トピックの最も可能性の高い単語
フラットトピックモデルと比較して、ツリー構造アプローチには明らかな利点があります。ツリーはデータから自動的に学習され、類似のトピックがツリーのさまざまな部分にグループ化されます。
上位レベルのトピックはツリーの一番上にあります(例:多くの文書に登場する有益でない言葉が根底にあります)、より洗練された/具体的なトピックは葉にあります。これにより、図1のフラットなモデル出力よりもはるかに有益で解釈しやすい結果が得られます。
TSNTM によって学習されたドキュメントの例と関連するトピックの割り当て確率を次のセクションに示します。
例 1
ラボ用のAppleOneカラースキャナーが届きました。しかし、LaserWriter IIgでスキャンした写真を印刷すると、妥当なスキャン出力を得るのに苦労しています。より高い解像度でスキャンしてみましたが、画面上のディスプレイは非常に見栄えがします。しかし、印刷版は醜いものになっています!
これは、プリンターの解像度機能が原因ですか?それとも、より良い品質を得るためのトリックが関係していますか?それとも、画像を「きれいに」するために何か(PhotoShopなど)を入手する必要がありますか?どんな提案でもいただければ幸いです。よろしくお願いします、-クリス
例 2
セイバーズは今夜、OTでブルーインズを6-5で破り、シリーズをスイープするために戻ってきました。ブラッド・メイの美しいゴール(ラフォンテーヌが氷の上に横たわった状態で彼をお膳立てした)が試合を終わらせた。ファーは肩を負傷して試合を去り、ラフォンテーヌも強打された。しかし、セイバーズは1週間の休養を取るので、怪我は問題ないはずだ。
モントリオールはケベックを3-2で下し、シリーズ第7戦に突入したようです。ハブスは最初の2つのピリオドを支配し、40分後に2-2の同点に追いつくという不運に見舞われた。しかし、3分にブリュネが先制点を決めて勝利を収めた。
アイランダーズは、レイ・フェラーロのゴールでシリーズ3回目のOTゲームに4-3で勝利しました。キャップスは、第2クォーターで3-0のリードを奪った後、あっさりと崩壊した。アイルズのプレーオフOT通算成績は28勝7敗となった。
例 3
Wergo Musicレーベルで20ドル未満でCDを入手できる場所を教えてください。
明らかに特定のトピック(最初のトピックなど)に分類されるドキュメントはリーフノードで高い確率を持ち、学習したトピック(3番目のトピックなど)のいずれにも明確に該当しないドキュメントはルートノードで高い確率を持ちます。
定量評価
トピックモデルは、定量的に評価するのが難しいことで有名です。それにもかかわらず、トピックの一貫性を測定するための最も一般的な指標は、 正規化された点ごとの相互情報量 (NPMI) です。各トピックの上位M個の単語を取ると、単語wiとwjの各ペアの同時確率P(wi,wj)が、周辺確率P(wi)とP(wj)と比較して高い場合、NPMIは高くなります。
確率は経験的カウントを使用して推定されます。
| NPMI | |
|---|---|
| ETM | 0.193 |
| TSNTM | 0.227 |
これらの結果は、TSNTMがETMよりも一貫性のあるモデルであるという定性的結果を裏付けています。
変圧器の組み込み
TSNTMは直感的で解釈しやすい結果を生成しますが、学習したモデルにはまだ弱点があります。たとえば、図 3 では、政治と宇宙に関連するトピックが同じ親ノードの下にグループ化されています。これは不合理ではないかもしれませんが、それらの親ノードは宗教に関連しており、おそらく首尾一貫していません。
もう1つのより微妙な例は、トピック1.3がハードウェアとソフトウェアの両方に関連するコンピューティングトピックをグループ化することです。おそらく、これらは分離されるべきでしょう。
これらの問題は、これまでにトレーニングされたモデルが(非コンテキストの)GloVe埋め込みに基づいているためであると仮定します。 これにより、異なる文脈で異なる意味を持つ単語の曖昧さを解消することが困難になる可能性があります。 過去数年間で、Transformerベースのモデルは、テキストの有益で文脈的な表現を学習するための最先端のパフォーマンスを達成しました。 トランスフォーマーの埋め込みをTSNTMに組み込むことを目指しています。
TSNTMへのトランスの埋め込みの追加
私たちは、複合トピックモデル(CTM)のアプローチに従います。bag-of-words 表現のみを推論モデルへの入力として使用する代わりに、bag-of-words 表現と Transformer モデルの最終層状態の平均を連結します。これは単純な変更ですが、推論モデルがより良い事後近似を学習できるようになるはずです。
Transformer モデルでは、多数の文レベルのタスクで一貫して高いスコアを達成するため、Sentence-BERT (SBERT) のall-mpnet-base-v2バリアントを使用します。
推論モデルに SBERT 埋め込みが追加されている点を除き、前のセクションの TSNTM と同一のモデルをトレーニングします。繰り返しになりますが、次の図は、各トピックで学習された上位 10 個の単語と、各トピックを最も可能性の高いトピックとして含むドキュメントの数を示しています。
SBERT + TSNTMによって学習された各トピックの最も可能性の高い単語
SBERTが埋め込まれたTSNTMは、GloVeのみのモデルの矛盾の問題のいくつかに対処しているようです。宗教、政治、暗号化のトピックは、同じ親トピックの下にグループ化されました。しかし、GloVeのみのモデルとは異なり、この親はより一般的なトピックになり、その上位の言葉は意見を表明する人々に関連しています。
コンピュータのハードウェアとソフトウェアのトピックは分割され、スペースはツリーの独自の部分にあります。NPMI はまた、SBERT が埋め込まれたモデルの方が一貫性があることを示唆しています。
| NPMI | |
|---|---|
| ETM | 0.193 |
| TSNTM (GloVe のみ) | 0.227 |
| TSNTM (GloVe + SBERT) | 0.234 |
概要
トピックモデルは、注釈を付けずにデータセットを高レベルで理解するための優れた方法であることを示しました。
- 「フラット」トピックモデルは最も一般的に使用されますが、弱点があります(例: 出力は解釈するのが最も簡単ではなく、事前にトピックの数を知る必要があります)。
- これらの弱点は、関連するトピックをグループ化し、データからトピック構造を自動的に学習するツリー構造モデルを使用することで対処できます。
- モデリングの結果は、Transformer の埋め込みを使用することでさらに改善できます。