- Introduction
- Vue d'ensemble (Overview)
- Comment les entreprises peuvent utiliser Communications Mining™
- Premiers pas avec Communications Mining™
- Configuration de votre compte
- Équilibre
- Clusters
- Dérive de concept
- Couverture
- Jeux de données
- Champs généraux
- Libellés (prédictions, niveaux de confiance, hiérarchie des libellés et sentiment des libellés)
- Modèles
- Flux
- Évaluation du modèle
- Projets
- Précision
- Rappel
- Messages annotés et non annotés
- Extraction des champs
- Sources
- Taxonomies
- Apprentissage
- Prédictions positives et négatives vraies et fausses
- Validation
- Messages
- Contrôle et administration de l'accès
- Gérer les sources et les jeux de données
- Comprendre la structure des données et les autorisations
- Créer ou supprimer une source de données dans l'interface graphique
- Préparation des données en vue du téléchargement du fichier .CSV
- Téléchargement d’un fichier CSV dans une source
- Création d'un ensemble de données
- Sources et jeux de données multilingues
- Activation des sentiments sur un ensemble de données
- Modification des paramètres du jeu de données
- Supprimer un message
- Supprimer un jeu de données
- Exporter un ensemble de données
- Utilisation d'intégrations Exchange
- Entraînement et maintenance du modèle
- Comprendre les libellés, les champs généraux et les métadonnées
- Hiérarchie de libellés et meilleures pratiques
- Comparer les cas d’utilisation des analyses et des automatisations
- Transformer vos objectifs en libellés
- Présentation du processus d'entraînement du modèle
- Annotation générative
- Statut du jeu de données
- Entraînement des modèles et annotation des meilleures pratiques
- Entraînement avec l'analyse des sentiments des libellés activée
- Comprendre les exigences de données
- Entraîner
- Vue d'ensemble (Overview)
- Examen des prédictions de libellé
- Entraînement à l'aide de la classification par glisser-déposer
- Entraînement à l'aide de l'option Enseigner le libellé (Explore)
- Entraînement à l'aide d'une confiance faible
- Entraînement à l'aide de la recherche (Explorer)
- Affiner et réorganiser votre taxonomie
- Introduction à affiner
- Précision et rappel expliqués
- Précision et rappel
- Comment fonctionne la validation
- Comprendre et améliorer les performances du modèle
- Raisons de la faible précision moyenne des libellés
- Entraînement à l'aide du libellé Vérifier (Check label) et du libellé Manqué (Missed Label)
- Entraînement à l'aide du libellé En savoir plus (Affiner)
- Entraînement à l'aide de la recherche (affiner)
- Comprendre et augmenter la couverture
- Amélioration de l'équilibre et utilisation du rééquilibrage
- Quand arrêter l'entraînement de votre modèle
- Utilisation de champs généraux
- Extraction générative
- Vue d'ensemble (Overview)
- Configurer des champs
- Filtrage par type de champ d’extraction
- Génération de vos extractions
- Validation et annotation des extractions générées
- Meilleures pratiques et considérations
- Comprendre la validation des extractions et des performances d'extraction
- Questions fréquemment posées (FAQ)
- Utilisation des analyses et de la surveillance
- Automations et Communications Mining™
- Développeur
- Charger des données
- Téléchargement de données
- Intégration avec l'utilisateur du service Azure
- Intégration avec l'authentification d'application Azure
- Intégration d’Exchange avec l’authentification et le graphique d’application Azure
- Guide de migration : Exchange Web Services (EWS) vers l'API Microsoft Graph
- Récupérer des données pour Tableau avec Python
- Intégration d'Elasticsearch
- Extraction de champ général
- Intégration avec Exchange auto-hébergée
- Infrastructure d’automatisation UiPath®
- Activités officielles UiPath®
- Comment les machines apprennent à comprendre les mots : guide d'intégration dans NLP
- Apprentissage basé sur des invites avec des Transformers
- Efficient Transformers II : Dilarisation des connaissances et affinement
- Transformateurs efficaces I : mécanismes d'attention
- Modélisation de l'intention hiérarchique profonde non supervisée : obtenir de la valeur sans données d'entraînement
- Correction des biais d’annotation avec Communications Mining™
- Apprentissage actif : de meilleurs modèles d'ML en moins de temps
- Tout est dans les chiffres : évaluer les performances du modèle avec des métriques
- Pourquoi la validation du modèle est importante
- Comparaison de Communications Mining™ et de Google AutoML pour l’information sur des données conversationnelles
- Licences
- FAQ et plus encore

Guide de l’utilisateur de Communications Mining
Comment les entreprises peuvent utiliser Communications Mining™
Cette page couvre un aperçu des sujets suivants :
- Types de données optimaux pour Communications Mining.
- Les piliers de valeur clé pour Communications Mining et la façon dont ils sont liés aux cas d'utilisation.
- Cas d'utilisation typiques dans l'analyse et l'automatisation.
- Exemples dans tous les secteurs où Communications Mining peut être déployé.
- Exemples de clients où Communications Mining est déployé.
- Les outils UiPath® que vous pouvez combiner avec Communications Mining, notamment RPA et Document Understanding™.
Types de données optimaux pour Communications Mining
 | Communications Mining est optimisé pour les données de communication asynchrones sous forme courte, tels que les e-mails, les tickets, les réponses aux enquêtes et les notes de cas. |
 | Communications Mining ne prend actuellement pas en charge les données d’appel et de chat en temps réel. Pour les analyses historiques des données de chat et d'appels, la plate-forme peut les prendre en charge si les volumes sont suffisamment importants. |
 | Communications Mining ne traite pas les pièces jointes de manière native, qui sont des documents, mais peut être combiné avec Document Understanding™ pour traiter à la fois les e-mails et les pièces jointes. |
Communications Mining est uniquement utilisé pour analyser et automatiser les e-mails provenant d'adresses e-mail d'entreprise et non de l'adresse e-mail personnelle d'un individu, par exemple, john.doe@yahoo.com ou jane.doe@gmail.com.
Pilier de valeur pour Communications Mining
Communications Mining peut générer de la valeur pour les entreprises de nombreuses façons. Au final, les objectifs commerciaux détermineront la valeur qu'un propriétaire de cas d'utilisation recherche, et les principes de valeur s'aligneront sur des cas d'utilisation spécifiques.
Le diagramme suivant détaille les principes de valeur clés que Communications Mining peut prendre en charge, ainsi que certains des cas d’utilisation qui s’alignent sur ces principes :

Cas d'utilisation : analytique
Comme décrit jusqu’à présent, Communications Mining ouvre aux clients des opportunités importantes d’analyse de données et d’automatisation.
À des fins d'analyse, certains groupes clés de cas d'utilisation comprennent :

Cas d'utilisation : automatisation
Dans le cadre de l'automatisation, les cas d'utilisation standards sont les suivants :

Exemples de l'industrie
En général, les clients demandent où Communications Mining peut être déployé, et la réponse est n’importe où.
Dans tous les secteurs, chaque processus et action à l’écran, de l’assistance à la clientèle à la commande de pièces dans la fabrication, aux devis d’assurance, aux déclarations et aux renouvellements, commence par une forme de communication.
Au fur et à mesure que les entreprises se développent, elles ont besoin de solutions, comme Communications Mining, pour les aider à gérer efficacement ces communications. Sinon, ils risquent de prendre du retard.
Exemples de cas d’utilisation client
La liste suivante contient quelques exemples spécifiques de la façon dont nos clients utilisent généralement Communications Mining :

Combinaison des outils UiPath® avec Communications Mining
Bien que Communications Mining puisse faire partie d'une solution, exploitant de nombreux outils UiPath différents, ou un exercice de découverte, en utilisant également Process Mining ou Task Mining, ou les deux, son intégration la plus directe et la plus percutante est la RPA et Document Understanding™.
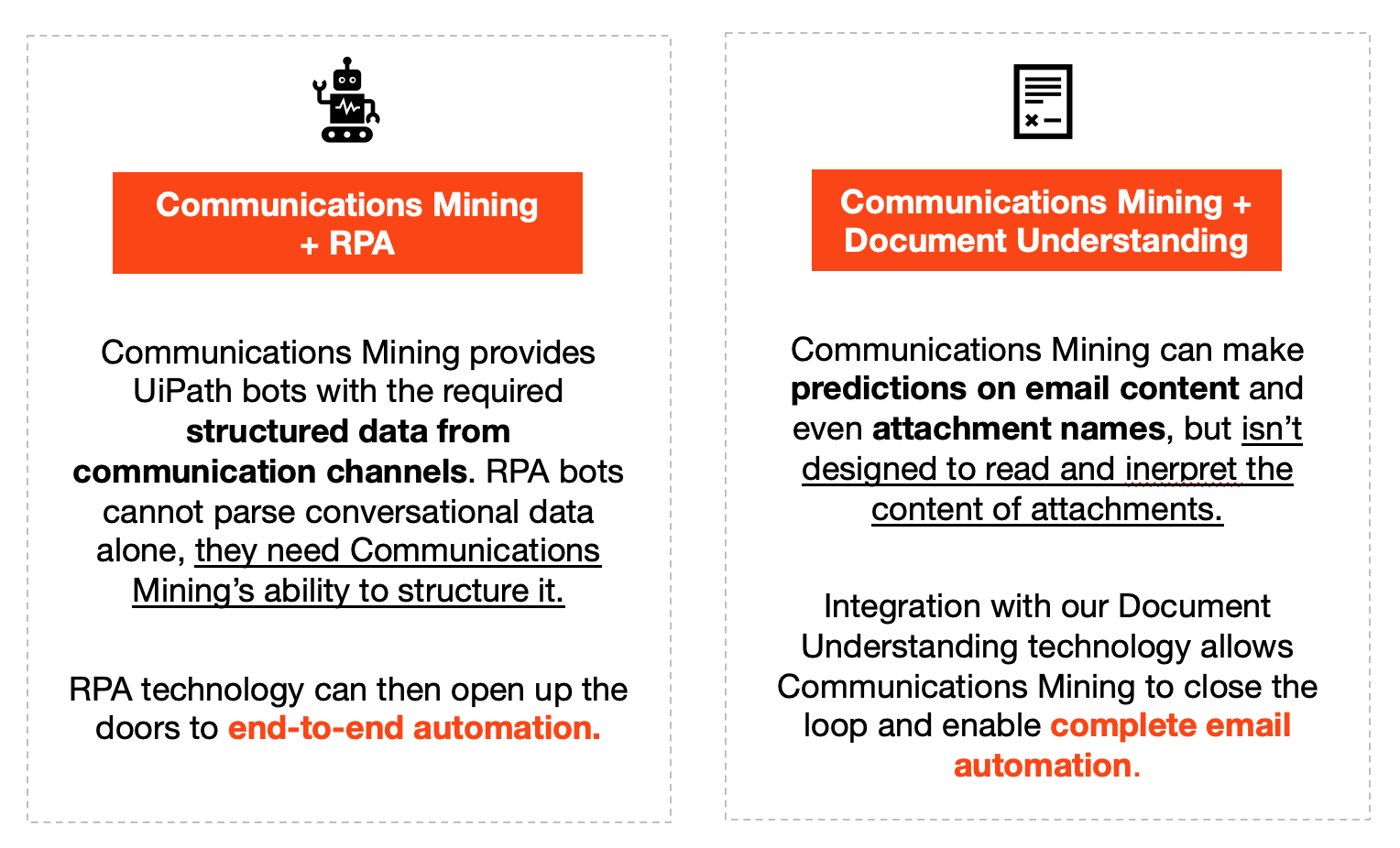
Communications Mining et RPA
Comme expliqué dans la section précédente, Communications Mining sert de moteur à l'automatisation intelligente en fournissant des données structurées aux automatisations en aval pour prendre des mesures.
Cette transition s’effectue généralement vers un robot UiPath®. Le schéma suivant fournit un aperçu détaillé de la façon dont Communications Mining et RPA peuvent fonctionner ensemble :

Pour de plus amples informations sur la façon dont Communications Mining s'associe à la RPA dans le cadre de l'automatisation, consultez l' Introduction à l'API Docs.
Bien que Communications Mining soit optimisé pour interagir avec d’autres outils UiPath, d’autres applications centrées sur l’API exploitent les prédictions de Communications Mining pour faciliter l’analyse et les cas d’utilisation de l’automatisation.
Communications Mining et Document Understanding


Communications Mining et Document Understanding peuvent gérer différents types de données, mais ils peuvent au final être réuni pour former une puissante solution combinée.
Chaque entreprise dans le monde traite des documents qui sont échangés par le biais de communications :
- Communications Mining et Document Understanding permettent aux entreprises de comprendre et d’automatiser les processus de service complexes E2E
- des tâches où les employés devaient auparavant lire les messages et les documents pour terminer leur travail.
- Ils créent une toute nouvelle source de données pour les robots UiPath. Pour la première fois, les entreprises peuvent automatiser certains de leurs processus de service les plus chronophages et les plus gourmands.
Comment Communications Mining et Document Understanding fonctionnent ensemble
L’image suivante contient un workflow graphique illustrant la façon dont Communications Mining et Document Understanding fonctionnent ensemble :

- Types de données optimaux pour Communications Mining
- Pilier de valeur pour Communications Mining
- Cas d'utilisation : analytique
- Cas d'utilisation : automatisation
- Exemples de l'industrie
- Exemples de cas d’utilisation client
- Combinaison des outils UiPath® avec Communications Mining
- Communications Mining et RPA
- Communications Mining et Document Understanding