- Introduction
- Configuration de votre compte
- Équilibre
- Clusters
- Dérive de concept
- Couverture
- Jeux de données
- Champs généraux
- Libellés (prédictions, niveaux de confiance, hiérarchie des libellés et sentiment des libellés)
- Modèles
- Flux
- Évaluation du modèle
- Projets
- Précision
- Rappel
- Messages annotés et non annotés
- Extraction des champs
- Sources
- Taxonomies
- Apprentissage
- Prédictions positives et négatives vraies et fausses
- Validation
- Messages
- Contrôle et administration de l'accès
- Gérer les sources et les jeux de données
- Comprendre la structure des données et les autorisations
- Créer ou supprimer une source de données dans l'interface graphique
- Préparation des données en vue du téléchargement du fichier .CSV
- Téléchargement d’un fichier CSV dans une source
- Création d'un ensemble de données
- Sources et jeux de données multilingues
- Activation des sentiments sur un ensemble de données
- Modification des paramètres du jeu de données
- Supprimer un message
- Supprimer un jeu de données
- Exporter un ensemble de données
- Utilisation d'intégrations Exchange
- Balises de transformation d’e-mail
- Entraînement et maintenance du modèle
- Comprendre les libellés, les champs généraux et les métadonnées
- Hiérarchie de libellés et meilleures pratiques
- Comparer les cas d’utilisation des analyses et des automatisations
- Transformer vos objectifs en libellés
- Présentation du processus d'entraînement du modèle
- Annotation générative
- Statut du jeu de données
- Entraînement des modèles et annotation des meilleures pratiques
- Entraînement avec l'analyse des sentiments des libellés activée
- Comprendre les exigences de données
- Entraîner
- Vue d'ensemble (Overview)
- Examen des prédictions de libellé
- Entraînement à l'aide de la classification par glisser-déposer
- Entraînement à l'aide de l'option Enseigner le libellé (Explore)
- Entraînement à l'aide d'une confiance faible
- Entraînement à l'aide de la recherche (Explorer)
- Affiner et réorganiser votre taxonomie
- Introduction à affiner
- Précision et rappel expliqués
- Précision et rappel
- Comment fonctionne la validation
- Comprendre et améliorer les performances du modèle
- Raisons de la faible précision moyenne des libellés
- Entraînement à l'aide du libellé Vérifier (Check label) et du libellé Manqué (Missed Label)
- Entraînement à l'aide du libellé En savoir plus (Affiner)
- Entraînement à l'aide de la recherche (affiner)
- Comprendre et augmenter la couverture
- Amélioration de l'équilibre et utilisation du rééquilibrage
- Quand arrêter l'entraînement de votre modèle
- Utilisation de champs généraux
- Extraction générative
- Vue d'ensemble (Overview)
- Configurer des champs
- Filtrage par type de champ d’extraction
- Génération de vos extractions
- Validation et annotation des extractions générées
- Meilleures pratiques et considérations
- Comprendre la validation des extractions et des performances d'extraction
- Questions fréquemment posées (FAQ)
- Utilisation des analyses et de la surveillance
- Automations et Communications Mining™
- Développeur
- Charger des données
- Téléchargement de données
- Intégration avec l'utilisateur du service Azure
- Intégration avec l'authentification d'application Azure
- Intégration d’Exchange avec l’authentification et le graphique d’application Azure
- Guide de migration : Exchange Web Services (EWS) vers l'API Microsoft Graph
- Récupérer des données pour Tableau avec Python
- Intégration d'Elasticsearch
- Extraction de champ général
- Intégration avec Exchange auto-hébergée
- Infrastructure d’automatisation UiPath®
- Activités officielles UiPath®
- Comment les machines apprennent à comprendre les mots : guide d'intégration dans NLP
- Apprentissage basé sur des invites avec des Transformers
- Efficient Transformers II : Dilarisation des connaissances et affinement
- Transformateurs efficaces I : mécanismes d'attention
- Modélisation de l'intention hiérarchique profonde non supervisée : obtenir de la valeur sans données d'entraînement
- Correction des biais d’annotation avec Communications Mining™
- Apprentissage actif : de meilleurs modèles d'ML en moins de temps
- Tout est dans les chiffres : évaluer les performances du modèle avec des métriques
- Pourquoi la validation du modèle est importante
- Comparaison de Communications Mining™ et de Google AutoML pour l’information sur des données conversationnelles
- Licences
- FAQ et plus encore
Modélisation d’intention profonde et non supervisée dans IXP sur Automation Cloud pour extraire la valeur des communications sans données d’entraînement.
Les entreprises misent sur la communication : les clients contactent quand ils veulent quelque chose, tandis que vos collègues communiquent pour réaliser le travail. Chaque message compte. Notre mission de Communications Mining™ afin de libérer de l’intérêt dans ces messages et d’aider chaque équipe d’une entreprise à fournir de meilleurs produits et services à grande échelle.
Dans ce but, nous recherchons et développons en permanence notre technologie principale d'apprentissage automatique et de compréhension du langage naturel. Les modèles d’apprentissage automatique de Communications Mining utilisent le pré-entraînement, l’apprentissage non supervisé, l’apprentissage semi-supervisé et l’apprentissage actif pour fournir une précision de pointe avec un minimum de temps et d’investissement de la part de nos utilisateurs.
Dans ce post de recherche, nous explorons une nouvelle approche non supervisée pour reconnaître automatiquement les sujets et les intentions, ainsi que leur structure de taxonomie, à partir d'un ensemble de données de communications. Il s'agit d'améliorer la qualité des informations que nous fournissons et la vitesse avec laquelle elles sont obtenues.
Résumé
Les modèles de sujet sont une classe de méthodes permettant de découvrir les « sujets » qui apparaissent dans une collection de « documents ». De plus, les modèles de sujets fonctionnent sans avoir à collecter des données d’entraînement annotées. Ils identifient automatiquement les sujets d’un ensemble de données et les rubriques qui apparaissent dans chaque document.
Un e-mail fictif d’« échec de transaction » et les types de sujets hiérarchisés que nous aimerions déduire automatiquement
Dans ce post :
- Nous expliquons les modèles de rubriques classiques et examinons certaines de leurs failles, par exemple que le nombre de rubriques doit être connu à l’avance, que les relations entre les rubriques ne sont pas capturées, etc.
- Nous organisons les sujets dans une hiérarchie qui est automatiquement déduite en fonction de la structure de sujets de l'ensemble de données. La hiérarchie regroupe les rubriques sémantiques liées.
- Nous atteignons une hiérarchie de rubriques plus cohérente en incorporant des intégrations basées sur Transformer dans le modèle.
Arrière-plan
Les modèles de rubrique supposent qu'un ensemble de données (collection de documents) contient un ensemble de rubriques. Une rubrique spécifie la probabilité pour que chaque mot apparaisse dans un document. Chaque document de l'ensemble de données est généré à partir d'un mélange de rubriques. En règle générale, les ensembles de mots qui apparaissent fréquemment ensemble auront une probabilité élevée dans un sujet donné.
Par exemple, imaginons que nous ayons un ensemble de données composé des documents suivants :
- Document 1: « Documents sont des descendants des descendants des descendants »
- Document 2: « Les chats sont des animaux quand vous avez des moustaches de moustaches
- Document 3: « Types Il est connu que des robots pouvez attaquant par métier »
- Document 4: « après avoir été grattées par les c défauts des chats, certains robots peuvent devenir redirigés vers les chats »
- Document 5: « Les individus entraînent une préférence pour la présence de chats par rapport à d’autres tests »
Un modèle de sujet entraîné sur ces documents peut apprendre les sujets et les affectations de sujet de document suivants :
| Sujet 1 | Sujet 2 |
|---|---|
| Canaux | Chats |
| Masqué | onglets |
| loups | moustaches |
| ... | ... |
Exemples de sujets avec des mots triés par la probabilité la plus élevée.
| Sujet 1 | Sujet 2 | |
|---|---|---|
| Document1 | 100 % | 0% |
| Document 2 | 0% | 100 % |
| Document 3 | 50 % | 50 % |
| Document 4 | 33% | 67% |
| Document 5 | 67% | 33% |
Exemples d'affectations de sujet de document.
L'affichage des mots les plus probables pour chaque sujet, ainsi que des sujets auxquels appartient chaque document, fournit un aperçu du texte d'un ensemble de données et des documents qui sont similaires les uns aux autres.
Modèles de sujet intégrés
Le modèle de sujet canonique s'appelle l'affectation de Latent Diordret (LDA). Il s'agit d'un modèle génératif, entraîné à l'aide d'une estimation du maximum de probabilité. LDA suppose que :
- Il existe K sujets, chacun d'entre eux spécifiant une distribution dans le dictionnaire.
- Chaque document (collection de mots) a une distribution sur les sujets.
- Chaque mot d'un document est généré à partir d'un sujet, en fonction de la distribution du document dans les rubriques et de la distribution du sujet dans le dictionnaire.
La plupart des modèles de sujets modernes sont basés sur LDA ; dans un premier temps, nous nous concentrons sur le modèle de sujet intégré (ETM). L'ETM utilise des intégrations pour représenter à la fois les mots et les sujets. Dans la modélisation de sujet traditionnel, chaque sujet est une distribution complète du dictionnaire. Dans l’ETM, cependant, chaque sujet est un vecteur dans l’espace d’intégration. Pour chaque sujet, l'ETM utilise l'intégration du sujet pour former une distribution sur le dictionnaire.
Entraînement et inférence
Le processus génératif d'un document est le suivant :
-
Échantillonnez la représentation de la latence z de la distribution précédente : z∼N(0,I).
-
Calculez les proportions du sujet rubrique=softmax(z z).
-
Pour chaque mot w dans le document :
- Exemple d'affectation de la rubrique la plus récente
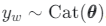 2. Échantillonner le mot
2. Échantillonner le mot
oùU∈ RV=E est la matrice d'intégration du mot et `tyw` ∈ RO) est l'intégration du sujet yw ; il s'agit des paramètres du modèle. V est le nombre de mots dans le dictionnaire et E est la taille d’intégration.
La probabilité de journalisation d'un document contenant les mots v1 ,v2 ,...,vw est :
Où :
Malheureusement, l’intégrative mentionnée précédemment est intractable. Par conséquent, il n'est pas facile de maximiser directement la probabilité de journalisation. Au lieu de cela, elle est optimisée environ par inférence variationnelle. Pour ce faire, une distribution « inférence » qqgh (z∐x ) est utilisée pour former une limite inférieure sur la probabilité de journalisation basée sur l’inéquation de Jensen , où x= x1 ,…,xW :
Cette limite inférieure peut maintenant être agrandie à l’aide des propositions de Monter Carlo de la nuances via la « astuce de réparamètres ».
Un goulot gaussien est utilisé pour la distribution d'inférence, dont la moyenne et la variance sont les sorties d'un réseau neuronal qui prend en entrée la représentation du sacs de mots du document.
Grâce à l'objectif d'entraînement précédent, la distribution d'inférence apprend à se rapprocher de la méthode postérieure vraie mais intractable, c'est-à-dire *qθ*(**z**∣**x**)≃*p*(**z**∣**x**) Cela signifie qu’une fois le modèle entraîné, nous pouvons utiliser la distribution d’inférence pour trouver les rubriques auxquelles un document a été affecté.
Le fait de prendre la moyenne de la distribution d'inférence et l'application de la fonction Softmax (conformément à l'étape 2 du processus génératif précédent) fournira les sommes approximatives du sujet postérieur pour un document donné.
Un exemple concret
Nous entraînons un ETM sur l'ensemble de données des 20 actualités , dont les commentaires sur les forum de discussion sur 20 sujets hiérarchiques sont classés comme suit :
- Calculs : comp.graphiques, comp.os.ms-windows.misc, comp.sys.ibm.PC.hardware, comp.sys.mac.hardware, comp.windows.x
- Activités de passe record.port.shockkey
- Technologie de la science : sci.crypt, sci. Nocrypts, sci.méd, sci.space
- Politiques : ainsi.policies.misc, Translater.politic. :Ones, Converser.policies.milieu est
- – Contexte alt.atheisme, soc. permet. permet.
- Divers : misc.forsalen
Chez Communications Mining, nous travaillons exclusivement avec des données de communication, qui ne sont pas communément privées. Pour la réproductibilité, et parce qu'il s'agit de l'ensemble de données de modélisation de sujet le plus couramment utilisé dans la documentation de recherche en apprentissage automatique, nous utilisons ici l'ensemble de données des 20 groupes de nouvelles. Ceci est considéré comme « Bonjour le monde » de la modélisation des sujets.
Nous entraînons le modèle avec 20 sujets (par exemple K = 20), car pour cet ensemble de données, nous savons déjà combien de sujets sont présents ( mais en général, ce ne sera pas le cas). Nous utilisons GliVe pour initialiser la matrice d’intégration U.
L'image suivante illustre les 10 premiers mots appriss pour chaque sujet et le nombre de documents dont chaque sujet est le plus probable :
Mots les plus probables pour chaque sujet appris par l'ETM
Les principaux mots appriss correspondent globalement aux vrais sujets de l'ensemble de données, par exemple sujet 2 = contact.poliaides.TG, sujet 13 = sci.space, Etc. Pour chaque document, nous pouvons également examiner les probabilités d'affectation des sujets ; quelques échantillons sont présentés dans les sections qui suivent. Certains documents ont une probabilité élevée d’un seul sujet, tandis que d’autres documents sont des mélanges de plusieurs sujets.
Exemple 1
Cela semble absent, mais bien que j’aie localisé des éléments tels que tgif qui peut modifier des fichiers gif et divers outils pour convertir vers/depuis le format gif, je n’ai pas pu localiser un programme qui ouvre simplement une fenêtre et affiche un fichier gif dedans. J’ai parcouru divers fichiers faq, également sans disponibilité. Y a-t-il une recherche dans une archive? Rien de sophistiqué; simplement « montrer l'image améliorée»?
Alternativement, si je peux localiser les spécifications du gif, je ne suppose pas qu’il serait trop difficile de les écrire moi-même, mais je n’ai aucune idée par où commencer à rechercher la spécification. (Eh bien, en fait, j'ai une idée - ce groupe de presse.;-) Obtenir, xv, version 3.0. Il lit/affiche/ Insights de nombreux formats différents.
Exemple 2
Le but auquel vous faites référence est Clint Malarchuk. Il jouait à ce moment avec les Sabres. Son équipe juste avant était celle des Windows Caps. Bien qu’il ait récupéré et continue de jouer, je ne sais pas où il se trouve actuellement.
Exemple 3
bonjour dans netWorld, Nous avons un lab d'anciens macs (SE et Plus). Nous n'avons pas assez d'argent pour acheter toutes les nouvelles machines, nous envisageons donc d'acheter quelques Superdrives pour nos anciens macs afin de permettre aux utilisateurs possédant des disques haute densité d'utiliser notre matériel. Je me demande quelles sont les expériences (utiles ou non) des utilisateurs avec ce type de mise à niveau. Cloud
Même sans connaître le jeu de données à l'avance, ces résultats montrent qu'il est possible d'avoir rapidement et facilement un aperçu du jeu de données, d'identifier les sujets auxquels appartient chaque document et de regrouper les documents similaires. Si nous voulons également collecter des données annotées pour entraîner une tâche supervisée, les sorties du modèle de rubrique nous permettent de commencer à annoter à partir d'une perspective plus informée.
Modèles de sujets structurés en arborescence
Même si les modèles de rubriques tels que décrits dans la section précédente peuvent être très utiles, ils présentent certaines limitations :
- Le nombre de rubriques doit être spécifié à l'avance. En général, nous ne saurons pas quel est le nombre correct.
- Bien qu'il soit possible d'entraîner plusieurs modèles avec un nombre différent de sujets et de choisir le meilleur, cela coûte cher.
- Même si nous connaissons le bon nombre de sujets, les sujets appris peuvent ne pas correspondre aux bons, par ex. la rubrique 16 de la figure 1 n'apparaît pas correspondre à l'une des vraies rubriques de l'ensemble de données 20 Newsgroups.
- Le modèle ne capture pas la relation entre les sujets. Par exemple, dans la figure 1, il existe plusieurs sujets sur le calcul, mais l'idée que ceux-ci sont liés n'est pas apprise par le modèle.
En réalité, il est généralement possible que le nombre de sujets soit inconnu à l'avance et que les sujets soient liés les uns aux autres. Une méthode permettant de résoudre ces problèmes consiste à représenter chaque sujet sous forme de nœud dans une arborescence. Cela nous permet de modéliser les relations entre les rubriques; les rubriques connexes peuvent se trouver dans la même partie de l'arborescence.
Cela fournirait des sorties beaucoup plus faciles à interpréter. De plus, si le modèle peut apprendre à partir des données, combien il doit y avoir de sujets et comment ils sont liés les uns aux autres, nous n'avons pas besoin de les connaître à l'avance.
Pour ce faire, nous utilisons un modèle basé sur le modèle de rubrique neuronal structuré en arborescence (TSNTM). Le processus génératif fonctionne en choisissant un chemin depuis la racine de l'arborescence vers une feuille, puis en choisissant un nœud le long de ce chemin. Les probabilités sur les chemins de l’arborescence sont modélisées à l’aide d’un processus de rupture de rupture, qui est paramétré à l’aide d’un réseau neuronal doublement récurrent.
Processus d’arrêt forcé
Le processus de rupture de tableau peut être utilisé pour modéliser les probabilités selon les chemins d'un arbre. Intuitivement, cela implique de casser à plusieurs reprises un Suite qui est initialement de longueur 1. La proportion du collage correspondant à un nœud de l’arborescence représente la probabilité le long de ce chemin.
Le processus de rupture de la barre, avec des proportions en vert
Par exemple, prenez l'arborescence de la figure 2, avec 2 couches et 2 enfants à chaque couche. Au niveau du nœud racine, la longueur de clé est de 1. Il est ensuite divisé en deux parties, de longueurs 0,7 et 0,3 respectivement. Chacune de ces pièces est ensuite divisée jusqu'à ce que nous atteignions les feuilles de l'arbre. Étant donné que nous pouvons continuer à casser le joint, l’arbre peut être arbitrairement large et profond.
Réseaux neuronaux doublement récurrents
Comme dans l'ETM, le processus génératif du TSNTM commence par l'échantillonnage de la représentation de la latence z de la distribution précédente :
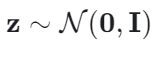
Un réseau de neurones doublement récurrent (DRSN) est utilisé pour déterminer les proportions de proportions. Après avoir initialisé de manière aléatoire l'état masqué du nœud racine, h1 pour chaque sujet k, l'état masqué hk est indiqué par :
où hpar(k) est l'état caché du nœud parent, et hk-1 est l'état caché du nœud frères immédiatement précédent (les frères et sœurs sont classés en fonction de leur index initial).
La proportion de la clé restante affectée au sujet k,vk est donnée par :
Ensuite, la probabilité au nœud k, AIk est donnée par
où j∈ {1,…,k<1} sont les frères et sœurs précédents du nœud k. Voici les valeurs en vert dans l' Figure 2. La valeur à chaque nœud de feuille est la probabilité pour ce chemin d'accès (il n'y a qu'un seul chemin vers chaque nœud de feuille).
Maintenant que nous disposons de probabilités sur les chemins de l'arborescence, il nous faut des probabilités sur les nœuds de chaque chemin. Ceux-ci sont calculés à l'aide d'un autre processus de rupture. À chaque niveau de l’arborescence, l’état caché )est donné par :
Cela signifie que tous les nœuds situés au même niveau de l’arborescence auront la même valeur pour `gl.
La proportion de la clé restante affectée au niveau l,nl est donnée par :
La probabilité au niveau l, Log est donnée par :
De manière empirique, nous avons parfois constaté que les mots les plus probables pour les nœuds enfants dans l'arborescence n'étaient pas sémantiquement liés à ceux de leurs parents. Pour résoudre ce problème, dans l’équation 2, nous appliquons une température pour atténuer le sigmoid :
Dans nos expériences, nous définissons px=0.1. Cela rend plus probable que lorsqu'un nœud enfant a une masse de probabilité non nulle, ses parents le seront également (réduit le risque que les nœuds enfants ne soient pas liés à leurs parents).
Entraînement et inférence
L'objectif d'entraînement reste le même que dans l'équation 1 ; le seul changement est la façon dont p(xw=vw|z) est spécifié. Ceci est maintenant fourni par :
Mise à jour de la structure d’arborescence
Jusqu’à présent, l’arborescence est corrigée. Cependant, nous souhaitons que cela soit basé sur les données. Spécifier la structure exacte de l'arborescence en tant qu'hyperparamètre est beaucoup plus difficile que de spécifier simplement un nombre de sujets, comme nous le ferions pour un modèle de sujet plate. Si nous connaissions à l'avance la structure générale de l'arborescence, nous n'aurions probablement pas besoin de modéliser les sujets.
Les applications pratiques des modèles de sujets structurés en arborescence doivent donc être capables d'apprendre la structure à partir des données. Pour ce faire, deux règles heuristiques sont utilisées pour ajouter et supprimer des nœuds vers et depuis l'arborescence. Tout d'abord, la masse de probabilité totale à chaque nœud est estimée à l'aide d'un sous-ensemble aléatoire des données d'entraînement. Au nœud k, cette estimation est:
où d={1,…,D} indexe le sous-ensemble de documents choisi de manière aléatoire et Nd } est le nombre de mots dans le document d. Sur la base de ces estimations, après toutes les itérations I :
- Si pk est supérieur à un seuil, un enfant est ajouté sous le nœud k afin d'affiner le sujet.
- Si la somme cumulative
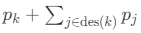 est inférieur à un seuil, le nœud k et ses descendants sont supprimés.
est inférieur à un seuil, le nœud k et ses descendants sont supprimés.
Résultats sur 20 newgroups
Nous exécutons le TSNTM sur le même ensemble de données de 20 groupes de nouvelles utilisé pour entraîner l'ETM ci-dessus. Nous initialisons l'arborescence pour avoir 2 couches avec 3 enfants à chaque couche. L'image suivante illustre la structure d'arborescence finale, les 10 premiers mots appriss pour chaque sujet et le nombre de documents dont chaque sujet est le plus probable :
Mots les plus probables pour chaque sujet appris par le TSNTM
Par rapport au modèle de sujet plate, l'approche structurée en arborescence présente de nets avantages. L'arborescence est automatiquement entraînée à partir des données, les sujets similaires étant regroupés dans différentes parties de l'arborescence.
Les sujets de niveau supérieur se trouvent en haut de l'arborescence (par ex. les mots non informatifs qui apparaissent dans de nombreux documents se trouvent à la racine), et les sujets plus précis/Spécifiques se trouvent dans les feuilles. Cela donne des résultats beaucoup plus informatifs et plus faciles à interpréter que la sortie du modèle plate de la Figure 1.
Exemples de documents et les probabilités d'affectation de sujets associées apprises par le TSNTM sont présentés dans les sections suivantes :
Exemple 1
Nous venons de recevoir un scanner de couleurs AppleOne pour notre laboratoire. Cependant, j’ai du mal à obtenir une sortie numérisée raisonnable lors de l’impression d’une photo numérisée sur un marqueur IIg. J'ai essayé de numériser à une résolution supérieure et l'affichage à l'écran semble très réussi. Cependant, la version papier est minable!
Cela est-il dû aux capacités de résolution de la machine? Ou existe-t-il des astuces pour obtenir une meilleure qualité? Ou devons-nous obtenir quelque chose (comme photostore) pour « améliorer» l'image? Je prends en compte toutes les suggestions. Merci d’avance, -Kris
Exemple 2
C'est terminé - les Docs sont revenus pour capturer les Bruins dans l'UT 6-5 ce ce dernier pour bénéficier de la série. Un excellent but de toujours, tandis que LaFonttain l’a installé en reposant sur la cloud, a mis fin à cela. Fuhr a quitté le jeu avec une documents invalidée et La police a également été endommagée; cependant, les robots prendront une semaine de travail, afin que les dommages ne soient pas un problème.
Montaré a placé la file d'attente lors de l'étape 3 à 2 au SQL de leur série, ce qui semble Assurez-vous d'accéder au jeu 7. Les Hubs ont contrôlé les deux premières périodes et ont eu le plaisir de n'avoir qu'une attente 2-2 après 40 minutes. Cependant, un objectif précoce de Brunet le 3 l' prise en charge.
Les insulaires ont gagné leur 3e jeu OAuth de la série sur un but par PayFerro 4-3; les Captures ont simplement été réduites après avoir pris un prospect de 3-0 dans le 2e. L’enregistrement OT de lecture de tous les temps des Îles est désormais de 28 à 7.
Exemple 3
Dites-moi où je peux obtenir un CD sur le label Wergo Classic pour moins de 20 $.
Les documents qui relèvent clairement d'un sujet spécifique (par exemple le premier) ont une probabilité élevée au niveau du nœud feuille tandis que ceux qui ne relèvent clairement d'aucun des sujets appris (par exemple le troisième) ont une probabilité élevée au nœud racine .
Évaluation relative
Les modèles de sujets ne sont pas si difficiles à évaluer quantitativement. Néanmoins, la mesure la plus populaire pour mesurer la cohérence du sujet est l’ information mutuelle du point de vue normalisée. En reprenant les premiers mots M pour chaque sujet, le
Les probabilités sont estimées à l'aide de nombres factices.
| NPMI | |
|---|---|
| ETM | 0.193 |
| TSNTM | 0.227 |
Ces résultats prennent en charge les résultats qualitatifs selon lesquels le TSNTM est un modèle plus cohérent que l’ETM.
Incorporation des transformations
Bien que le TSNTM produit des résultats intuitifs et faciles à interpréter, le modèle entraîné présente toujours des points faibles. Par exemple, dans la Figure 3, les rubriques relatives à la politique et à l'espace ont été regroupées sous le même nœud parent. Cela n’est peut-être pas déraisonnable, mais leur nœud parent est lié à la culture, ce qui n’est pas cohérent.
Un autre exemple plus subtil est que la rubrique 1.3 regroupe des sujets de calcul liés au matériel et aux logiciels; peut-être doivent-ils être séparés.
Nous supposons que ces problèmes sont dus au fait que les modèles entraînés jusqu’à présent sont basés sur des intégrations Cloud (non contextuelles). Il peut alors être difficile de désambiguïser les mots qui ont des significations différentes dans différents contextes. Au cours des dernières années, les modèles basés sur Transformer ont atteint des performances de pointe pour l'apprentissage de représentations informatives et contextuelles du texte. Nous cherchons à incorporer les intégrations de Transformer dans le TSNTM.
Ajout des intégrations de Transformer au TSNTM
Nous suivons l'approche du modèle de sujet combiné. Au lieu d'utiliser uniquement la représentation du paquet de mots comme entrée du modèle d'inférence, nous concatène désormais la représentation du paquet de mots avec la moyenne des états de couche finaux d'un modèle de Transformer. Bien qu'il s'agisse d'une modification simple, elle devrait permettre au modèle d'inférence d'apprendre une meilleure approximation antérieure.
Pour le modèle Transformer, nous utilisons la variante all-mpnet-base-v2 de Sentence-BERT, car elle atteint des scores systématiquement élevés sur un certain nombre de tâches au niveau de la phrase.
Nous entraînons un modèle qui est par ailleurs identique au TSNTM de la section précédente, à l’exception des intégrations SBERT ajoutées au modèle d’inférence. De nouveau, l'image suivante illustre les 10 premiers mots appriss pour chaque sujet et le nombre de documents dont chaque sujet est le plus probable :
Mots les plus probables pour chaque sujet appris par SBERT+TSNTM
Le TSNTM avec les intégrations SBERT semble résoudre certains des problèmes d'incohérence du modèle GlobalVe uniquement. Les rubriques prêt à l'emploi, la politique et le chiffrement sont désormais regroupées sous la même rubrique parente. Mais contrairement au modèle GlobalVe uniquement, ce parent est désormais un sujet plus générique dont les principaux mots sont liés à des personnes exprimant des points de vue.
Les rubriques matérielles et logicielles ont désormais été divisées et l'espace se trouve dans sa propre partie de l'arborescence. Le NPMi suggère également que le modèle avec les intégrations SBERT est plus cohérent:
| NPMI | |
|---|---|
| ETM | 0.193 |
| TSNTM (GloVe uniquement) | 0.227 |
| TSNTM (GloVe + SBERT) | 0.234 |
Résumé
Nous avons illustré que les modèles de rubrique peuvent être un excellent moyen d'obtenir une compréhension de haut niveau d'un ensemble de données sans avoir à effectuer d'annotation.
- Les modèles de rubrique « plat » sont les plus couramment utilisés, mais présentent des vulnérabilités (par ex. sortie pas plus facile à interpréter, nécessitant de connaître le nombre de rubriques à l'avance).
- Ces failles peuvent être résolues à l'aide d'un modèle arborescent qui regroupe les rubriques connexes et apprend automatiquement la structure de la rubrique à partir des données.
- Les résultats de la modélisation peuvent être encore améliorés en utilisant les intégrations de transformation.
- Résumé
- Arrière-plan
- Modèles de sujet intégrés
- Entraînement et inférence
- Un exemple concret
- Exemple 1
- Exemple 2
- Exemple 3
- Modèles de sujets structurés en arborescence
- Processus d’arrêt forcé
- Réseaux neuronaux doublement récurrents
- Entraînement et inférence
- Mise à jour de la structure d’arborescence
- Résultats sur 20 newgroups
- Exemple 1
- Exemple 2
- Exemple 3
- Évaluation relative
- Incorporation des transformations
- Ajout des intégrations de Transformer au TSNTM
- Résumé