- Notas de versão
- Visão geral
- Introdução
- Fornecedores do Marketplace
- Clientes do Marketplace
- Diretrizes de publicação
- Diretrizes de publicação para automações prontas para execução
- Diretrizes de publicação para aceleradores de soluções
- Diretrizes de publicação para conectores do Integration Service
- Diretrizes de publicação para modelos de aplicativos do Process Mining
- Segurança e Proteção de IP
- Outras listagens da UiPath
- Node-RED
- Configuração
- Teams
- Escopo do Microsoft Teams
- Criar equipe
- Criar equipe do grupo
- Get Team
- Obter equipes
- Canais
- Criar canal
- Excluir canal
- Obter canal
- Obter canais
- Canal de Atualização
- Chats
- Obter chat
- Obter chats
- Get Chat Members
- Mensagens
- Get message
- Get Messages
- Obter respostas da mensagem
- Responder à mensagem
- Enviar mensagem
- Events
- Create Event
- Delete Event
- Get Event
- Obter eventos
- Usuários
- Get User Presença
- Como funciona
- Referências técnicas
- Introdução
- Configuração
- Referências técnicas
- Inícios rápidos
- Escopo da Amazon
- Atividades
- Analisar documento de página única
- Analisar documento de várias páginas
- Iniciar análise do documento
- Obter status da análise do documento
- Obter análise do documento
- O objeto Detalhes da página
- Como funciona
- Referências técnicas
- Introdução
- Sobre
- Configuração
- Referências técnicas
- Escopo do Reconhecedor de formulário do Azure
- Atividades
- Analisar formulário
- Analisar formulário assíncrono
- Obter resultado do formulário de análise
- Analisar recibo
- Analisar recibo assíncrono
- Obter resultado de recebimento da análise
- Analisar layout
- Analisar layout assíncrono
- Obter resultado da análise de layout
- Treinar modelo
- Obter modelos
- Obter chaves do modelo
- Obter informações do modelo
- Excluir modelo
- Conectores
- Como criar atividades
- Crie sua integração

Guia do usuário do Marketplace
Analisar documento de várias páginas
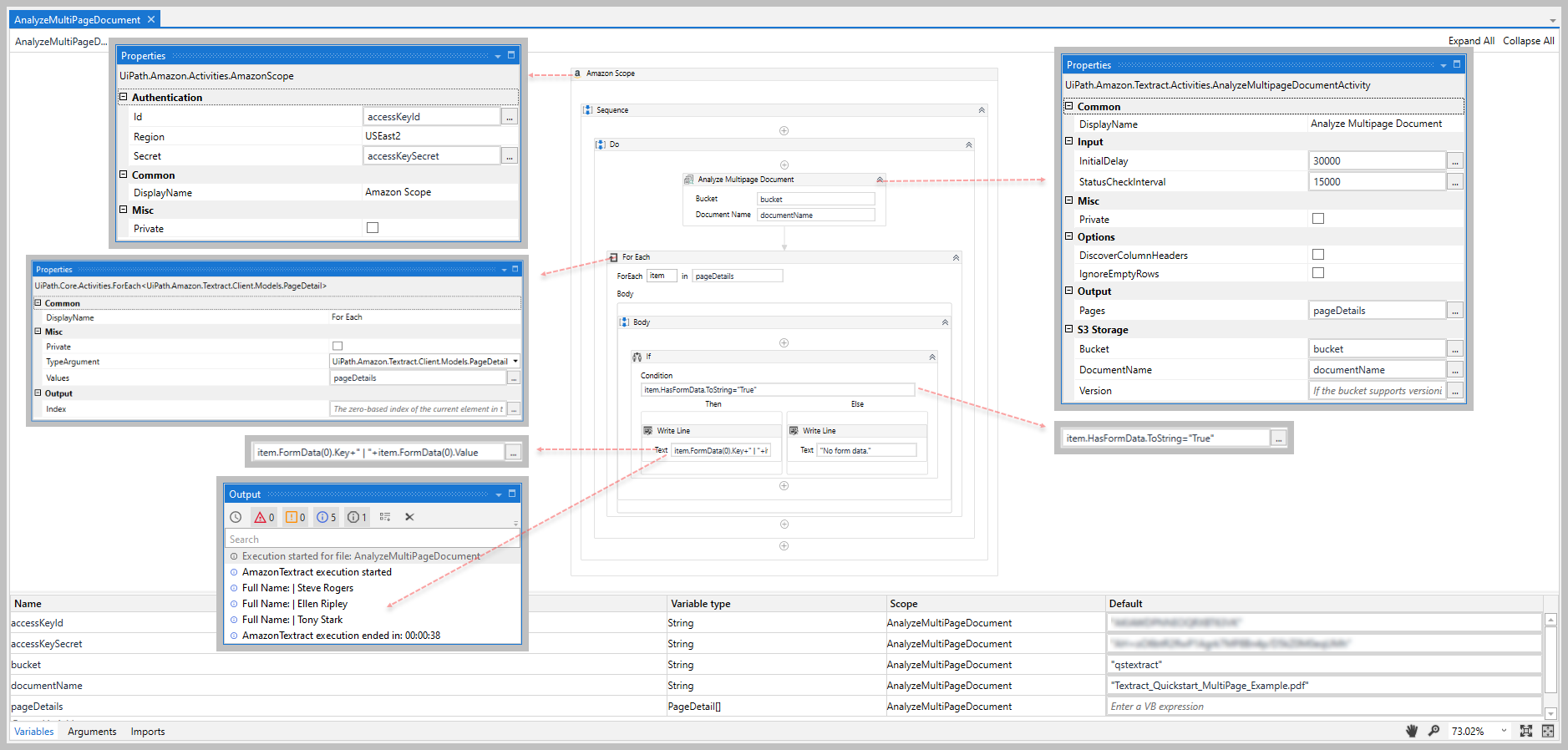
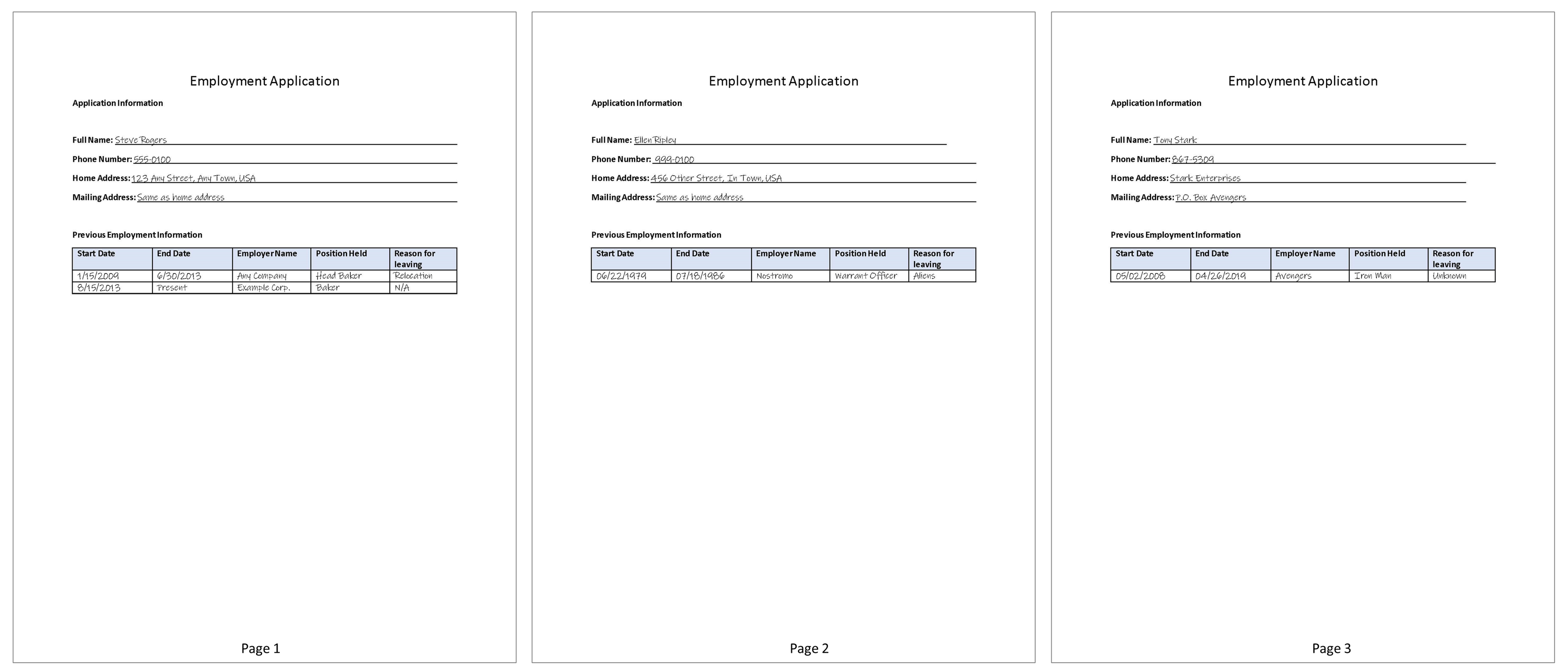
The Analyze Multipage Document activity uses the Amazon Textract StartDocumentAnalysis and GetDocumentAnalysis APIs to analyze a multi-page document stored in an S3 bucket (Bucket, DocumentName, and Version). If your document includes a table, you have the option to indicate if the first row contains column headers (DiscoverColumnHeaders) and/or ignore empty rows (IgnoreEmptyRows).
After analyzing the document, the activity returns the document properties in a PageDetailCollection object (Pages) that you can use as input variables in other activities outside of the Amazon Textract Activities Package.
The Analyze Multipage Document activity is essentially a combination of the Start Document Analysis, Get Document Analysis Status, and Get Document Analysis activities in a single activity.
In previous versions of this activity, the (Pages) output parameter returned a PageDetail[] object. In 2.0 this has been changed to a PageDetailCollection to allow us to return the RawJson property for the method call, which was not possible with an array.
Como funciona
The following steps and message sequence diagram is an example of how the activity works from design time (that is, the activity dependencies and input/output properties) to run time.
- Conclua as etapas de Configuração .
- Add the Amazon Scope activity to your project.
- Add the Analyze Single Page Document inside the Amazon Scope activity.
- Enter values for the S3 Storage input properties.
- Create and enter a
PageDetailCollectionvariable for your Output property. - Execute a atividade.
-
Your input properties are sent to the AnalyzeDocument API.
-
A API retorna o valor
PageDetailpara sua variável de propriedade de saída.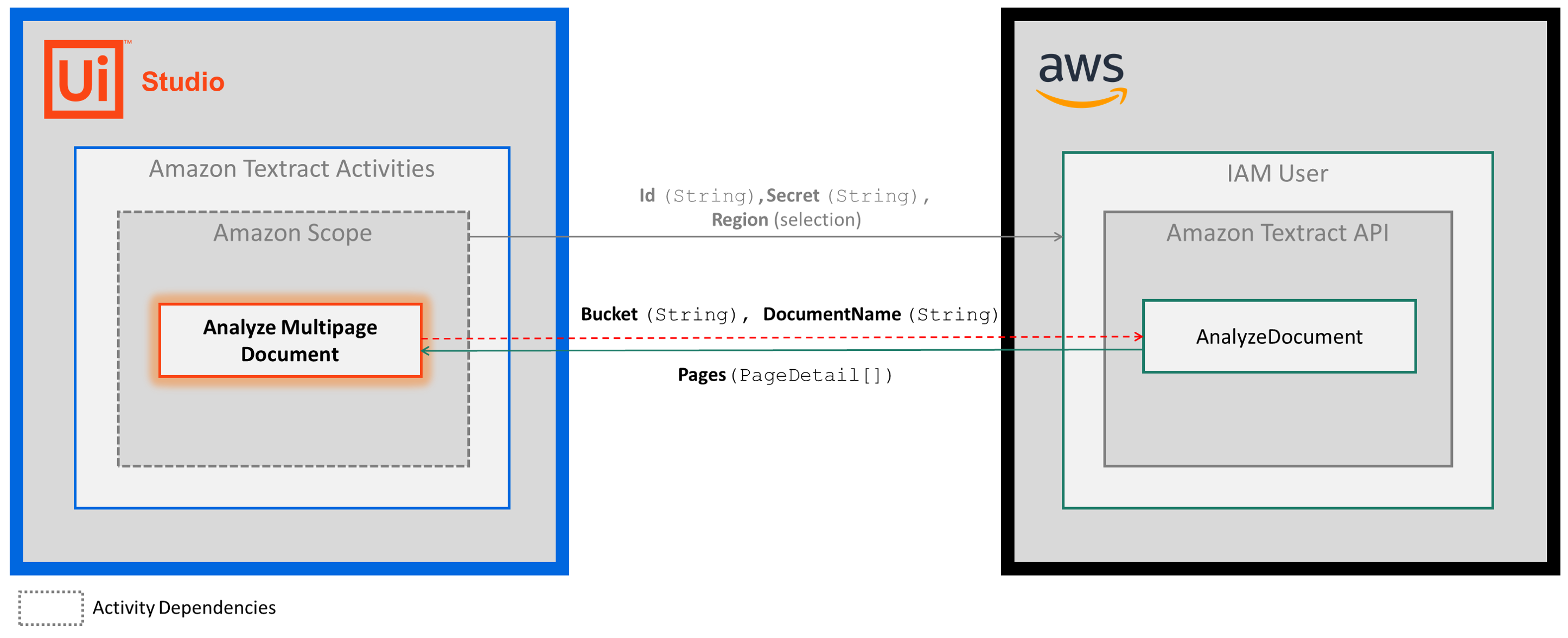
-
Propriedades
Os valores para as seguintes propriedades são especificados ao adicionar esta atividade ao seu projeto no UiPath Studio.
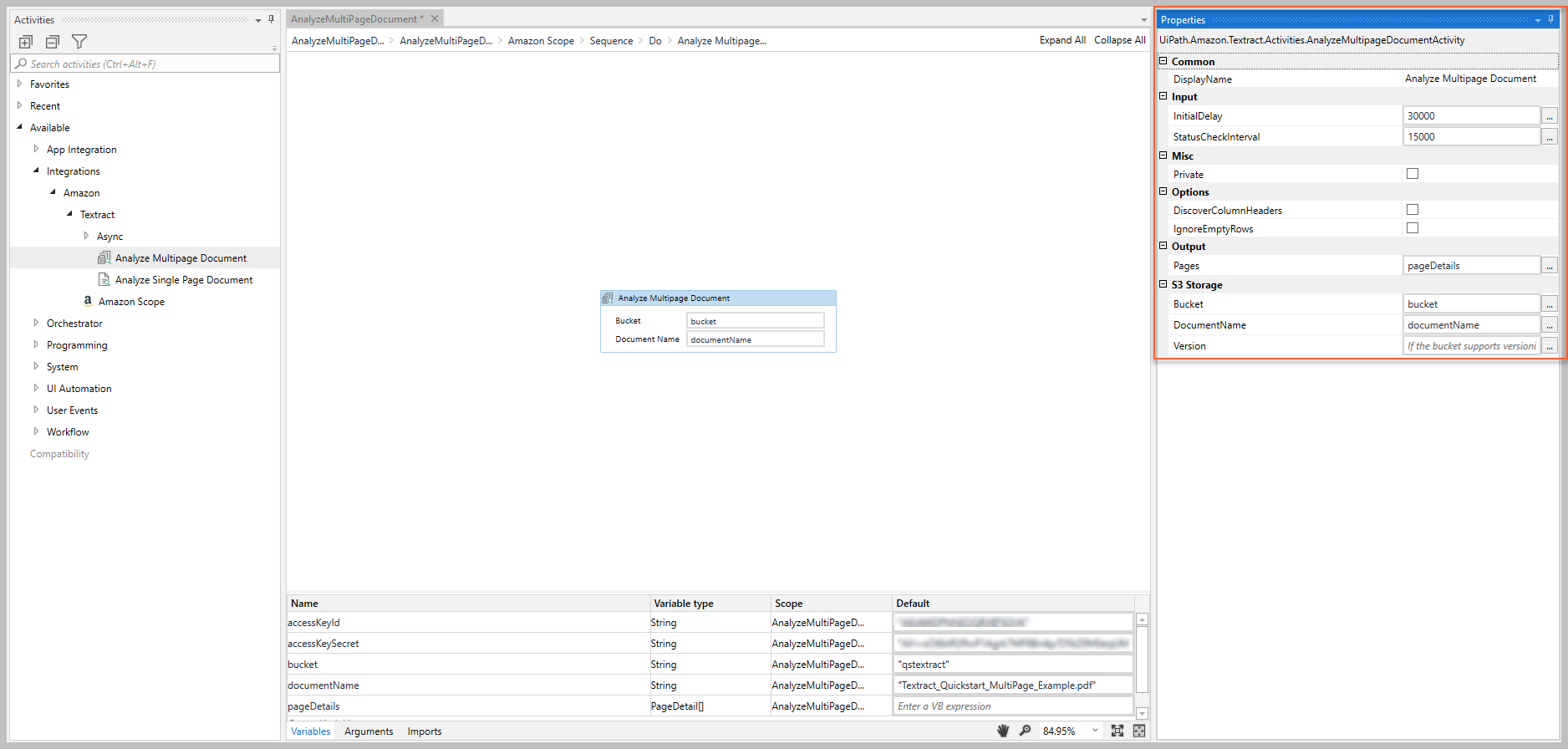
Comum
NomeDeExibição
O nome de exibição da atividade.
| Atributos | Detalhes |
|---|---|
| Tipo | String |
| Required | Sim |
| Valor padrão | Analyze Multipage Document |
| Valores permitidos | Insira uma variável String ou String . |
| Observações | N/A |
Entrada
Unlike the Get Document Analysis Status, which requires an external delay mechanism to poll the service for status changes, the Analyze Multipage Document includes the following, optional input properties to set an initial status check delay (InitialDelay) and status check interval (StatusCheckInterval).
InitialDelay
O tempo de espera antes que a atividade chame a API Amazon Textract GetDocumentAnalysis para recuperar o valor JobStatus.
| Atributos | Detalhes |
|---|---|
| Tipo | Int32 (milissegundos) |
| Required | Não |
| Valor padrão | 15000 (not shown) |
| Valores permitidos | Insira uma variável Int32 ou Int32 . |
| Observações | Enter your value in milliseconds (e.g., 30000 for 30 seconds); your value must be greater or equal to 15000. When analyzing a large document, it's recommended that you enter the estimated time it takes for the Amazon Textract service to complete its analysis. For example, if your document takes up to 2 minutes to analyze, you should enter 120000 as your value and use the StatusCheckInterval property to indicate how often you want to check for an updated status if the job doesn't complete within the 2-minute estimate. |
StatusCheckInterval
O tempo de espera entre as chamadas para a API Amazon Textract GetDocumentAnalysis para recuperar o valor de JobStatus.
| Atributos | Detalhes |
|---|---|
| Tipo | Int32 (milissegundos) |
| Required | Não |
| Valor padrão | 10000 (not shown) |
| Valores permitidos | Insira uma variável Int32 ou Int32 . |
| Observações | Enter your value in milliseconds (e.g., 15000 for 30 seconds); your value must be greater or equal to 10000. The objective of this property is to help manage the number of calls that your activity makes to the Amazon Textract API. |
Opções
TipoDeAnálise
Especifica os tipos de análise a serem realizados. Use Tabelas para retornar informações sobre as tabelas detectadas no documento de entrada e Formulários para retornar dados de formulários detectados.
| Atributos | Detalhes |
|---|---|
| Tipo | ENUM |
| Required | Não. |
| Valor padrão | Todos |
| Valores permitidos | Todas, Tabelas, Formulários |
| Observações | N/A |
DiscoverColumnHeaders
Indica se as tabelas no documento incluem cabeçalhos de coluna.
| Atributos | Detalhes |
|---|---|
| Tipo | Caixa de seleção |
| Required | Não |
| Valor padrão | não selecionado |
| Valores permitidos | Selecionado ou Não Selecionado |
| Observações | N/A |
IgnorarLinhasVazias
Indica se as linhas vazias nas tabelas do documento devem ser ignoradas ao analisar o documento.
| Atributos | Detalhes |
|---|---|
| Tipo | Caixa de seleção |
| Required | Não |
| Valor padrão | não selecionado |
| Valores permitidos | Selecionado ou Não Selecionado |
| Observações | N/A |
Armazenamento S3
Bucket
O nome do bucket S3 em que o documento é armazenado.
| Atributos | Detalhes |
|---|---|
| Tipo | String |
| Required | Sim |
| Valor padrão | Vazio |
| Valores permitidos | Insira uma variável String ou String . |
| Observações | The AWS Region for the S3 bucket that contains the document must match the Region that you selected in the Amazon Scope activity. For Amazon Textract to process a file in an S3 bucket, the user must have permission to access the S3 bucket; for more information, see step 6 in the Create IAM User section of the Setup guide. |
Nome do Documento
The case-sensitive name of the file in the specified Bucket that you want to analyze.
| Atributos | Detalhes |
|---|---|
| Tipo | String |
| Required | Sim |
| Valor padrão | Vazio |
| Valores permitidos | Insira uma variável String ou String . |
| Observações | Formatos de documento suportados: PNG, JPEG e PDF. |
Versão
Se o bucket tiver o controle de versão habilitado, você poderá especificar a versão do objeto.
| Atributos | Detalhes |
|---|---|
| Tipo | String |
| Required | Não |
| Valor padrão | Vazio |
| Valores permitidos | Insira uma variável String ou String . |
| Observações | N/A |
Diversos
Particular
Se selecionado, os valores das variáveis e argumentos não são mais registrados no nível Verbose.
| Atributos | Detalhes |
|---|---|
| Tipo | Caixa de seleção |
| Required | Não |
| Valor padrão | não selecionado |
| Valores permitidos | Selecionado ou Não Selecionado |
| Observações | N/A |
Saída
Páginas
As propriedades extraídas do documento especificado são retornadas como uma matriz.
| Atributos | Detalhes |
|---|---|
| Tipo | PageDetailCollection |
| Required | Não (recomendado se você planejar usar os dados de saída em atividades subsequentes) |
| Valor padrão | Vazio |
| Valores permitidos | Insira uma variável PageDetailCollection |
| Observações | Each object from the array represents the results for one individual page. This is a change from previous versions which returned a PageDetail[] object. See Page Detail for the description of the PageDetail object and its properties. |
Exemplo
A imagem a seguir mostra um exemplo do relacionamento de dependência de atividade e valores de propriedade de entrada/saída.
For step-by-step instructions and examples, see the Quickstart guides.