- Avant de commencer
- Démarrage
- Intégrations
- Travailler avec des applications de processus
- Travailler avec des tableaux de bord et des graphiques
- Travailler avec des graphiques de processus
- Travailler avec des modèles de processus Découvrir et importer des modèles BPMN
- Afficher ou masquer le menu
- Informations contextuelles
- Exporter (Export)
- Filtres
- Envoi d’idées d’automatisation au Automation Hub d’UiPath®
- Balises
- Dates d’échéance
- Comparer
- Vérification de la conformité
- Analyse des causes profondes
- Simulation du potentiel d’automatisation
- Déclenchement d'une automatisation à partir d'une application de processus
- Afficher les données de processus
- Création d'applications
- Chargement des données
- Transforming data
- Structure des transformations
- Conseils pour l'écriture de SQL
- Exportation et importation de transformations
- Afficher les journaux d'exécution des données
- Fusion des journaux d'événements
- Configuration des balises
- Configuration des dates d'échéance
- Configuration des champs pour le potentiel d'automatisation
- Rendre les transformations disponibles dans les tableaux de bord
- Personnaliser les tableaux de bord
- Publication des tableaux de bord
- Modèles d'applications
- Notifications
- Ressources supplémentaires

Guide de l'utilisateur de Process Mining
Transformations
Structure des dossiers
Les informations de cette page s'appliquent uniquement aux modèles d'application qui ont des fichiers de configuration de dates d'échéance et un dossier seeds\ .
Les transformations d'une application de processus consistent en un projet dbt . Le tableau suivant décrit le contenu d'un dossier de projet dbt .
| Dossier/Fichier | Contient |
|---|---|
dbt_packages\ | le package pm_utils et ses macros. |
macros\ | dossier facultatif pour les macros personnalisées |
models\ | .sql qui définissent les transformations. |
models\schema\ | .yml qui définissent des tests sur les données. |
seeds | .csv avec les paramètres de configuration. |
dbt_project.yml | les paramètres du projet dbt . |
Les modèles d'application Journal des événements et Processus personnalisé ont une structure de transformation de données simplifiée. Les applications de processus créées avec ces modèles d'application n'ont pas cette structure de dossiers.
dbt_project.yml
Le fichier dbt_project.yml contient les paramètres du projet dbt qui définit vos transformations. La section vars contient des variables utilisées dans les transformations.
Format date/heure
Chaque modèle d'application contient des variables qui déterminent le format d'analyse des données de date/heure. Ces variables doivent être ajustées si les données d'entrée ont un format date/heure différent de celui prévu.
Transformations de données
Les transformations de données sont définies dans les fichiers .sql du répertoire models\ . Les transformations de données sont organisées dans un ensemble standard de sous-répertoires.
Consultez Structure des transformations pour plus d'informations.
The .sql files are written in Jinja SQL, which allows you to insert Jinja statements inside plain SQL queries. When dbt runs all .sql files, each .sql file results in a new view or table in the database.
En règle générale, les fichiers .sql ont la structure suivante : Select * from {{ ref('Table_A') }} Table_A.
Le code suivant montre un exemple de requête SQL.
select
tableA."Field_1" as "Alias_1",
tableA."Field_2",
tableA."Field_3"
from {{ ref('tableA') }} as tableA
select
tableA."Field_1" as "Alias_1",
tableA."Field_2",
tableA."Field_3"
from {{ ref('tableA') }} as tableA
Dans certains cas, pour les applications de processus créées avec des versions antérieures des modèles d'application, les fichiers .sql ont la structure suivante :
- Avec instructions: une ou plusieurs instructions avec des instructions pour inclure les sous-tables requises.
{{ ref(‘My_table) }}fait référence à une table définie par un autre fichier .sql fichier.{{ source(var("schema_sources"), 'My_table') }}fait référence à une table d'entrée.
-
Requête principale: la requête qui définit la nouvelle table.
-
Requête finale: en général une requête comme
Select * from tableest utilisée à la fin. Cela facilite la sous-sélection lors du débogage.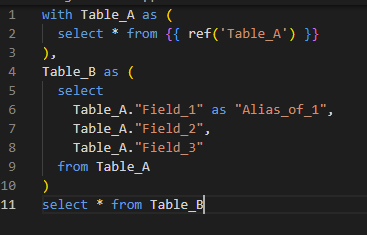
Pour obtenir de plus amples conseils sur l'écriture efficace des transformations, consultez la section Conseils pour l'écriture de SQL.
Ajout de tables sources
Pour ajouter une nouvelle table source au projet dbt , elle doit être répertoriée dans models\schema\sources.yml. De cette façon, d'autres modèles peuvent s'y référer en utilisant {{ source(var("schema_sources"), 'My_table') }}. L'illustration suivante vous en fournit un exemple.
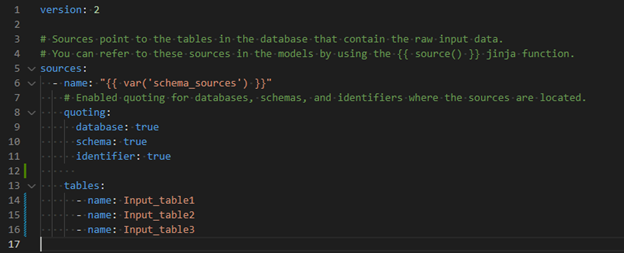
Each new source table must be listed in sources.yml.
Pour des informations plus détaillées, consultez la documentation officielle de dbt sur Sources.
Sortie de données
Les transformations de données doivent générer le modèle de données requis par l'application correspondante ; chaque table et chaque champ attendus doivent être présents.
Si vous souhaitez ajouter de nouveaux champs à votre application de processus, vous pouvez ajouter ces champs dans les transformations.
Macros
Les macros facilitent la réutilisation des constructions SQL courantes. Pour des informations détaillées, consultez la documentation officielle de dbt sur les macros jinja.
pm_utils
Le package pm-utils contient un ensemble de macros qui sont généralement utilisées dans les transformations Process Mining. Pour plus d'informations sur les macros pm_utils , consultez ProcessMining-pm-utils.
L'illustration suivante montre un exemple de code jinja appelant la macro pm_utils.optional() .

Graines
Les référence sont des fichiers csv utilisés pour ajouter des tables de données à vos transformations. Pour des informations détaillées, consultez la documentation officielle de dbt sur les donnes jinja.
Dans Process Mining, elle est généralement utilisée pour faciliter la configuration des mappages dans vos transformations.
Après avoir modifié les fichiers de référence, exécutez le fichier en sélectionnant Exécuter le fichier ou Exécuter tout, pour mettre à jour la table de données correspondante.
Consultez Configuration de l'activité : Définition de l'ordre de l'activité et Simulation du potentiel d'automatisation pour obtenir des exemples d'utilisation de fichiers de référence.
Configuration des activités : Définition de l'ordre des activités
Le champ Activity_order est utilisé comme déclencheur lorsque deux événements se produisent sur le même horodatage.
Option 1 : configuration de SQL
Le code suivant montre un exemple de configuration Activity_order avec une instruction SQL CASE :
case
when tableA."Activity" = 'ActivityA'
then 1
when tableA."Activity" = 'ActivityB'
then 2
when tableA."Activity" = 'ActivityC'
then 3
when tableA."Activity" = 'ActivityD'
then 4
end as "Activity_order"
case
when tableA."Activity" = 'ActivityA'
then 1
when tableA."Activity" = 'ActivityB'
then 2
when tableA."Activity" = 'ActivityC'
then 3
when tableA."Activity" = 'ActivityD'
then 4
end as "Activity_order"
Option 2 : fichier de référence CSV
Au lieu d'utiliser une instruction SQL CASE , vous pouvez définir Activity_order à l'aide du fichier activity_configuration.csv .
L’illustration suivante montre un exemple de fichier activity_configuration.csv :
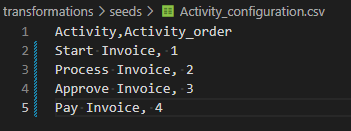
Recommandations
La plupart des modèles d'application UiPath sont fournis avec des champs prédéfinis pour la configuration de l'activité, que vous pouvez adapter aux besoins spécifiques de votre entreprise. Si les champs prédéfinis sont indisponibles ou insuffisants, vous pouvez toujours créer des champs personnalisés à l'aide de SQL ou du fichier de référence activity_configuration.csv , comme indiqué.
Tests
Le dossier models\schema\ contient un ensemble de fichiers .yml qui définissent les tests. Ceux-ci valident la structure et le contenu des données attendues. Pour des informations détaillées, consultez la documentation officielle de dbt sur les tests.
When you edit transformations, make sure to update the tests accordingly. The tests can be removed if desired.
Projets dbt
Les Transformations de données sont utilisées pour transformer les données d'entrée en données adaptées à Process Mining. Les transformations dans Process Mining sont écrites sous forme de projets dbt .
Ces pages présentent une introduction à dbt. Pour des informations plus détaillées, consultez la documentation officielle de dbt.
pm-utils package
Les modèles d’application Process Mining sont fournis avec un package dbt appelé pm_utils. Ce package pm-utils contient des fonctions utilitaires et des macros pour les projets dbt Process Mining. Pour plus d'informations sur pm_utils , consultez ProcessMining-pm-utils.
Mise à jour de la version pm-utils utilisée pour votre modèle d'application
UiPath® améliore constamment le package pm-utils en ajoutant de nouvelles fonctions.
Lorsqu'une nouvelle version du paquet pm-utils est publiée, il est conseillé de mettre à jour la version utilisée dans vos transformations, pour vous assurer que vous utilisez les dernières fonctions et macros du paquet pm-utils .
Vous trouverez le numéro de version de la dernière version du package pm-utils dans le panneau Versions de ProcessMining-pm-utils.
Suivez ces étapes pour mettre à jour la version pm-utils dans vos transformations.
- Téléchargez le code source (zip) à partir de la version
pm-utils. - Extrayez le fichier
zipet renommez-le dans le dossier pm_utils. - Exportez les transformations à partir de l'éditeur de transformations de données intégré et extrayez les fichiers.
- Remplacez le dossier pm_utils des transformations exportées par le nouveau dossier pm_utils .
- Compressez à nouveau le contenu des transformations et importez-les dans l' éditeur de transformations de données .
- Structure des dossiers
- dbt_project.yml
- Transformations de données
- Ajout de tables sources
- Sortie de données
- Macros
- pm_utils
- Graines
- Configuration des activités : Définition de l'ordre des activités
- Tests
- Projets dbt
- pm-utils package
- Mise à jour de la version pm-utils utilisée pour votre modèle d'application