- 在开始之前
- 管理访问权限
- 入门指南
- 集成
- 使用流程应用程序
- 创建应用程序
- 正在加载数据
- Transforming data
- 自定义仪表板
- 发布流程应用程序
- 应用程序模板
- 通知
- 其他资源

Process Mining 用户指南
转换
文件夹结构
此页面上的信息仅适用于具有截止日期配置文件和seeds\文件夹的应用程序模板。
流程应用程序的转换包含一个dbt项目。下表描述了dbt项目文件夹的内容。
| 文件夹/文件 | 包含 |
|---|---|
dbt_packages\ | pm_utils包及其宏。 |
macros\ | 自定义宏的可选文件夹 |
models\ | .sql 定义转换的文件。 |
models\schema\ | .yml 定义数据测试的文件。 |
seeds | .csv 具有配置设置的 .csv 文件。 |
dbt_project.yml | dbt项目的设置。 |
事件日志和自定义流程应用程序模板具有简化的数据转换结构。使用这些应用程序模板创建的流程应用程序不具有此文件夹结构。
dbt_project.yml
dbt_project.yml 文件包含定义转换的dbt项目设置。“变量” 部分包含在转换中使用的变量。
日期/时间格式
每个应用程序模板都包含用于确定解析日期/时间数据的格式的变量。 如果输入数据的日期/时间格式与预期不同,则必须调整这些变量。
数据转换
数据转换在models\目录下的.sql文件中定义。数据转换组织在一组标准的子目录中。
有关详细信息,请查看转换结构。
The .sql files are written in Jinja SQL, which allows you to insert Jinja statements inside plain SQL queries. When dbt runs all .sql files, each .sql file results in a new view or table in the database.
通常, .sql文件具有以下结构: Select * from {{ ref('Table_A') }} Table_A 。
以下代码显示了一个 SQL 查询示例。
select
tableA."Field_1" as "Alias_1",
tableA."Field_2",
tableA."Field_3"
from {{ ref('tableA') }} as tableA
select
tableA."Field_1" as "Alias_1",
tableA."Field_2",
tableA."Field_3"
from {{ ref('tableA') }} as tableA
在某些情况下,对于使用旧版应用程序模板创建的流程应用程序, .sql文件具有以下结构:
- “With”语句:一个或多个包含所需子表的“with”语句。
{{ ref(‘My_table) }}引用由另一个 .sql 文件定义的表 文件。{{ source(var("schema_sources"), 'My_table') }}引用输入表。
-
主查询(主查询) :定义新表格的查询。
-
最终查询(一) :通常在末尾使用
Select * from table等查询。这样可以轻松地在调试时进行子选择。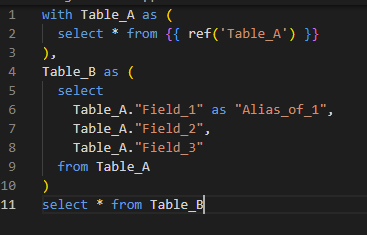
有关如何有效编写转换的更多提示,请参阅有关编写 SQL 的提示。
添加源表格
上传新的输入文件时,系统将自动在dbt项目的models\schema\sources.yml中添加新的源表。这样,其他模型就可以通过使用{{ source(var("schema_sources"), 'My_table') }}引用它。有关如何配置输入表的更多信息,请查看管理输入数据。
下图显示了一个示例。
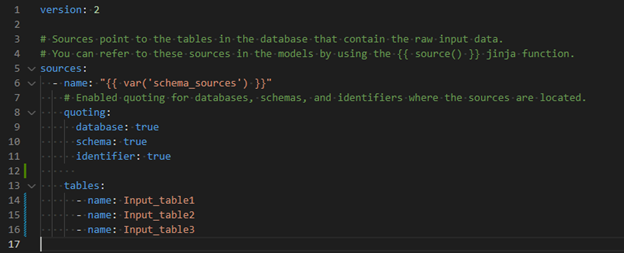
有关更详细的信息,请参阅有关 来源的 官方 dbt 文档 。
数据输出
数据转换必须输出相应应用程序所需的数据模型;每个预期的表格和字段都必须存在。
如果要向流程应用程序添加新字段,可以在转换中添加这些字段。
宏
宏可以轻松地重用常见的 SQL 结构。有关详细信息,请参阅有关 Jinja 宏的官方 dbt 文档。
pm_utils
pm-utils包包含一组通常在 Process Mining 转换中使用的宏。有关pm_utils宏的更多信息,请查看ProcessMining-pm-utils 。
下图显示了调用pm_utils.optional()宏的 Jinja 代码示例。

种子
种子是csv文件,用于将数据表添加到转换。有关详细信息,请参阅 Jinja 种子上的官方 dbt 文档。
在“Process Mining”中,这通常用于简化在转换中配置映射。
编辑种子文件后,通过选择“运行文件”或“运行全部”来运行文件,以更新相应的数据表。
有关使用种子文件的示例,请查看活动配置:定义活动顺序和模拟自动化潜力。
测试
models\schema\文件夹包含一组定义测试的.yml文件。这些将验证预期数据的结构和内容。有关详细信息,请参阅有关测试的官方 dbt 文档。
DBT 项目
数据转换用于将输入数据转换为适合Process Mining 的数据 。Process Mining中的转换将写入dbt项目。
本页介绍了dbt 。有关更详细信息,请参阅官方 dbt 文档。
pm-utils package
Process Mining应用程序模板附带一个名为pm_utils的dbt包。此pm-utils包包含用于 Process Mining dbt项目的实用工具函数和宏。有关pm_utils的更多信息,请参阅ProcessMining-pm-utils 。
更新用于应用程序模板的 pm-utils 版本
UiPath™通过添加新函数,不断改进pm-utils包。
当发布 pm-utils 包的新版本时,建议您更新转换中使用的版本,以确保使用 pm-utils 包的最新函数和宏。
您可以在pm-utils ProcessMining-pm-utils 的“版本” 面板中找到 包最新版的版本号。
请按照以下步骤更新转换中的 pm-utils 版本。
- 下载
pm-utils版本中的源代码 (zip)。 - 提取
zip文件并将文件夹重命名为pm_utils 。 - 从内联数据转换编辑器导出转换并提取文件。
- 将导出转换中的pm_utils文件夹替换为新的pm_utils文件夹。
- 再次压缩转换的内容,然后将其导入到数据转换编辑器中。