- Introduction
- Setting up your account
- Balance
- Clusters
- Concept drift
- Coverage
- Datasets
- General fields
- Labels (predictions, confidence levels, label hierarchy, and label sentiment)
- Models
- Streams
- Model Rating
- Projects
- Precision
- Recall
- Annotated and unannotated messages
- Extraction Fields
- Sources
- Taxonomies
- Training
- True and false positive and negative predictions
- Validation
- Messages
- Access control and administration
- Manage sources and datasets
- Understanding the data structure and permissions
- Creating or deleting a data source in the GUI
- Preparing data for .CSV upload
- Uploading a CSV file into a source
- Creating a dataset
- Multilingual sources and datasets
- Enabling sentiment on a dataset
- Amending dataset settings
- Deleting a message
- Deleting a dataset
- Exporting a dataset
- Using Exchange integrations
- Model training and maintenance
- Understanding labels, general fields, and metadata
- Label hierarchy and best practices
- Comparing analytics and automation use cases
- Turning your objectives into labels
- Overview of the model training process
- Generative Annotation
- Dastaset status
- Model training and annotating best practice
- Training with label sentiment analysis enabled
- Understanding data requirements
- Train
- Introduction to Refine
- Precision and recall explained
- Precision and Recall
- How validation works
- Understanding and improving model performance
- Reasons for label low average precision
- Training using Check label and Missed label
- Training using Teach label (Refine)
- Training using Search (Refine)
- Understanding and increasing coverage
- Improving Balance and using Rebalance
- When to stop training your model
- Using general fields
- Generative extraction
- Using analytics and monitoring
- Automations and Communications Mining™
- Developer
- Uploading data
- Downloading data
- Exchange Integration with Azure service user
- Exchange Integration with Azure Application Authentication
- Exchange Integration with Azure Application Authentication and Graph
- Migration Guide: Exchange Web Services (EWS) to Microsoft Graph API
- Fetching data for Tableau with Python
- Elasticsearch integration
- General field extraction
- Self-hosted Exchange integration
- UiPath® Automation Framework
- UiPath® official activities
- How machines learn to understand words: a guide to embeddings in NLP
- Prompt-based learning with Transformers
- Efficient Transformers II: knowledge distillation & fine-tuning
- Efficient Transformers I: attention mechanisms
- Deep hierarchical unsupervised intent modelling: getting value without training data
- Fixing annotating bias with Communications Mining™
- Active learning: better ML models in less time
- It's all in the numbers - assessing model performance with metrics
- Why model validation is important
- Comparing Communications Mining™ and Google AutoML for conversational data intelligence
- Licensing
- FAQs and more

Communications Mining user guide
Train
You must have assigned the IXP Analyst and IXP Model Trainer roles as an Automation Cloud user, or the View sources and Review and label permissions as a legacy user.
Overview
The main page in the Train tab provides useful information about the training done so far, the performance of the model, and a list of prioritized next best training actions to take. This acts similarly to the Validation page. It is a fully guided label training experience.
The progress indicators give you further context while training the model with more granular validation feedback. These indicators encourage you to complete foundational training actions before focusing on specific performance factors. Make sure you build a sufficient proportion of training data before focusing on model refinement.
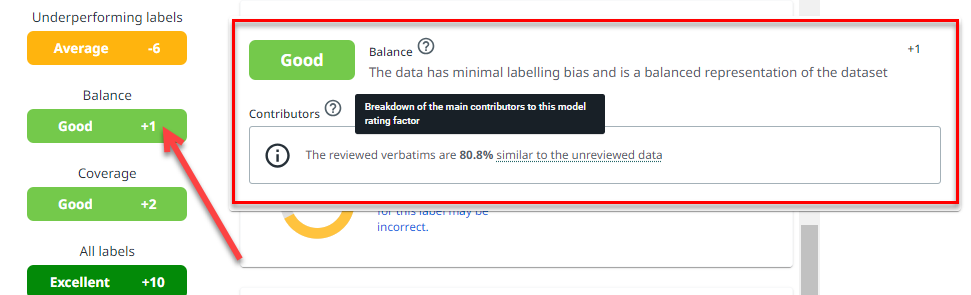
Hover over the annotation progress areas to view additional performance information and underlying contributors. In the following example, you can check the additional performance information once the foundational training actions are complete:
Training an action
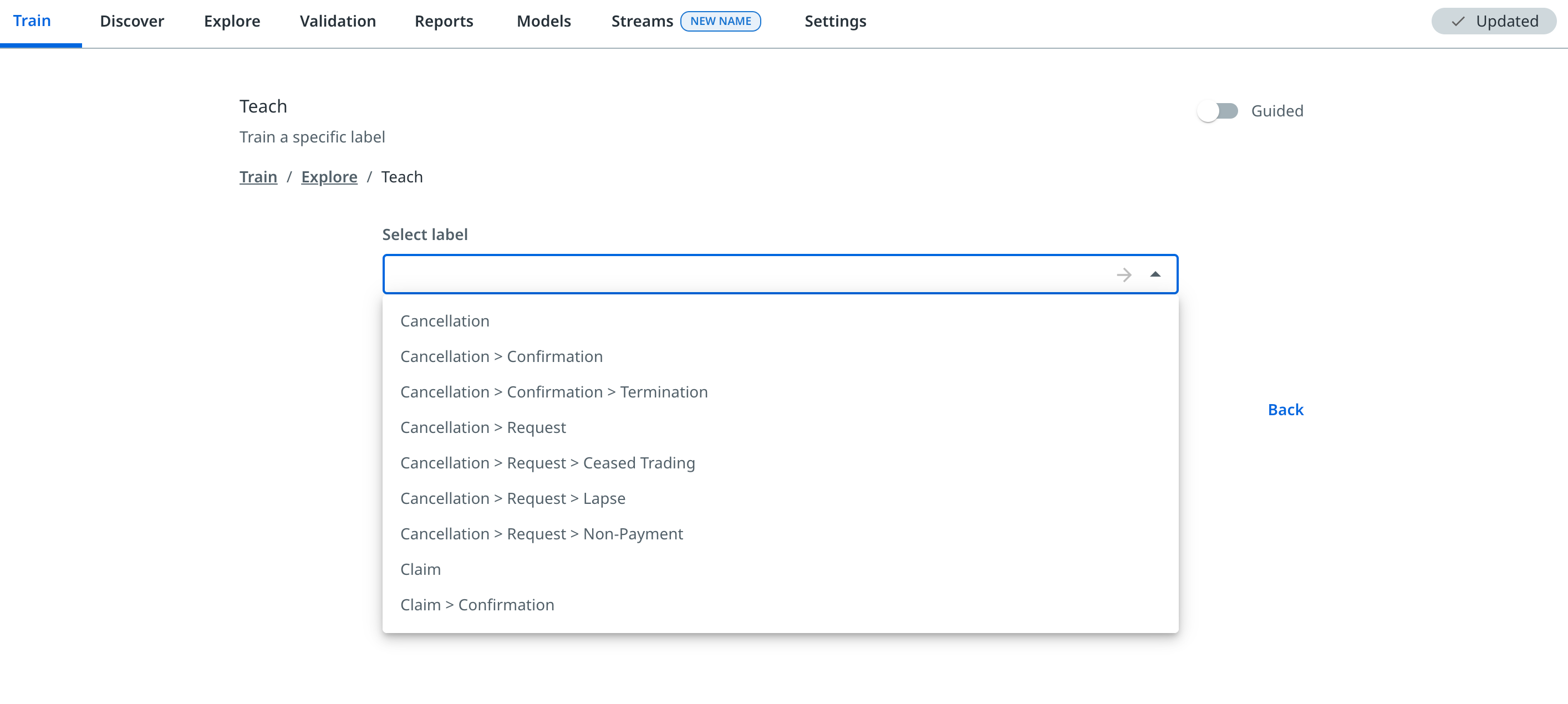
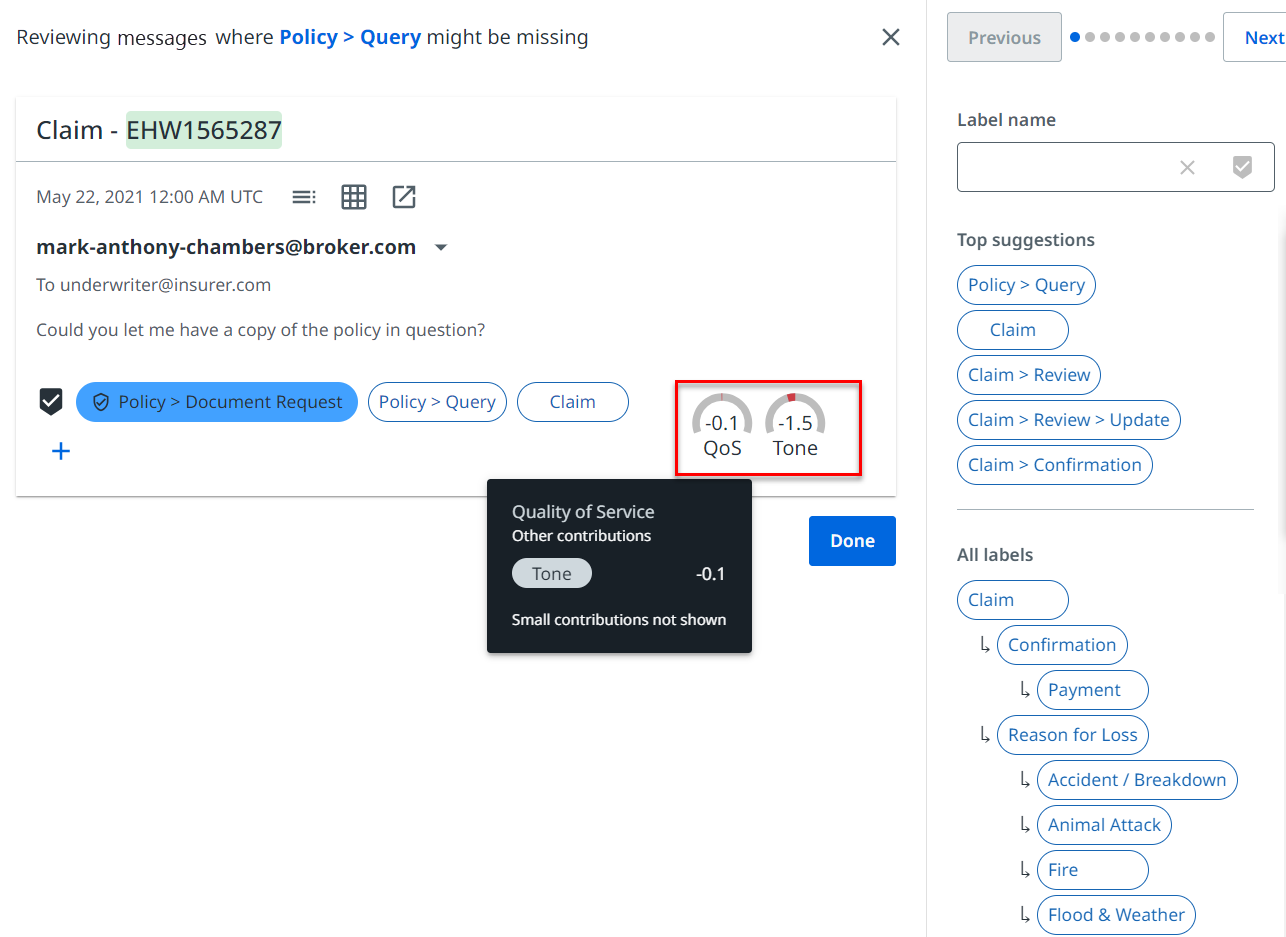
To train an action, proceed as follows:
-
In the Train tab, select a training action, for example, Annotate random messages to go to the specific training batch interface. Depending on the recommended action, the number of messages or clusters of messages in the batch is 10, but it can vary.
-
Apply the labels, and general fields, to the messages on the screen.
-
Select Done.
-
Select Next from the side panel to move to the next message or cluster.
-
At the end of the batch, you will notice a summary of the training actions you took.
-
To choose your next session, select another recommended action.
Note:The training that you complete triggers a retraining, and the next best actions also update as soon as possible. It is normal if more sessions of the same recommended action are required, and you might notice the same actions on the page. There is no need to wait for new actions to appear, to jump into another similar session.
If you prefer to train without the guidance of the platform, you can disable the Guided toggle icon, and select which sessions to complete. For more details, check Using Train without guidance enabled for labels.
Train impact on the model training process
The Train page will further become the main place to complete all of your model training from start to finish. Currently, Train is an add-on to the existing feature set, meaning that you can use as-is all of the functionalities you are used to, and you can train models as you usually do.
You are recommended to use Train for a guided label training experience, and provide feedback to your UiPath® account manager if you encounter any issues or challenges.
Label training
All of the pre-existing training modes are still available as they were through the Discover and Explore pages.
Training labels in the Train tab:
- Guides you from the moment you create a dataset with the next best actions to take to advance your label training. This includes uploading a taxonomy before you begin training.
- Guides you through the usual steps for the model training process, with the exception of recommending Search:
- For an effective training mode, use the Search action sparingly, to provide the model with a limited set of initial examples for labels that do not have enough training data yet. To use this action, go to Discover, Explore, or temporarily disable the guidance in Train. For more details, check Using Train without guidance enabled for labels.
- Provides need to know performance feedback in the main page and through its recommendations. If you need detailed feedback on model performance, go to the Validation page.
Note:
Hover over the annotation progress areas to view the additional progress indicators.
General field training
Toggle between training labels and general fields on the train tab if you have general fields enabled on your dataset.
Similar to training labels, all of the pre-existing training modes for general fields are still available as they were through the Explore page.
Training general fields in Train:
- Guides you from the moment you create a dataset with the next best actions to take to advance your general field training.
- Guides you through the usual steps for training general fields during the model training process.
- Provides need to know performance feedback in the main page and through its recommendations. If you need detailed feedback on general field performance, go to the Validation tab, and then to General field Validation.
- During the beginning of the model training process, if the platform does not have enough examples of general fields to learn from, it will recommend Shuffle by default. Once you provide enough examples, it will recommend more targeted training for specific general fields.
Using Train without guidance enabled for labels
The default setting for the Train page is to have platform guidance enabled, as this is our recommendation.
If you are a confident model trainer, and you know the actions that you already want to take, you can disable the guidance, using the toggle in the top right-hand of the page:

The platform will still highlight the phase considered the most appropriate. You can find the usual training actions within each phase, and you can target specific labels as needed. Check the following image: