- Introduction
- Setting up your account
- Balance
- Clusters
- Concept drift
- Coverage
- Datasets
- General fields
- Labels (predictions, confidence levels, label hierarchy, and label sentiment)
- Models
- Streams
- Model Rating
- Projects
- Precision
- Recall
- Annotated and unannotated messages
- Extraction Fields
- Sources
- Taxonomies
- Training
- True and false positive and negative predictions
- Validation
- Messages
- Access control and administration
- Manage sources and datasets
- Understanding the data structure and permissions
- Creating or deleting a data source in the GUI
- Preparing data for .CSV upload
- Uploading a CSV file into a source
- Creating a dataset
- Multilingual sources and datasets
- Enabling sentiment on a dataset
- Amending dataset settings
- Deleting a message
- Deleting a dataset
- Exporting a dataset
- Using Exchange integrations
- Model training and maintenance
- Understanding labels, general fields, and metadata
- Label hierarchy and best practices
- Comparing analytics and automation use cases
- Turning your objectives into labels
- Overview of the model training process
- Generative Annotation
- Dastaset status
- Model training and annotating best practice
- Training with label sentiment analysis enabled
- Understanding data requirements
- Train
- Introduction to Refine
- Precision and recall explained
- Precision and Recall
- How validation works
- Understanding and improving model performance
- Reasons for label low average precision
- Training using Check label and Missed label
- Training using Teach label (Refine)
- Training using Search (Refine)
- Understanding and increasing coverage
- Improving Balance and using Rebalance
- When to stop training your model
- Using general fields
- Generative extraction
- Using analytics and monitoring
- Automations and Communications Mining™
- Developer
- Uploading data
- Downloading data
- Exchange Integration with Azure service user
- Exchange Integration with Azure Application Authentication
- Exchange Integration with Azure Application Authentication and Graph
- Migration Guide: Exchange Web Services (EWS) to Microsoft Graph API
- Fetching data for Tableau with Python
- Elasticsearch integration
- General field extraction
- Self-hosted Exchange integration
- UiPath® Automation Framework
- UiPath® official activities
- How machines learn to understand words: a guide to embeddings in NLP
- Prompt-based learning with Transformers
- Efficient Transformers II: knowledge distillation & fine-tuning
- Efficient Transformers I: attention mechanisms
- Deep hierarchical unsupervised intent modelling: getting value without training data
- Fixing annotating bias with Communications Mining™
- Active learning: better ML models in less time
- It's all in the numbers - assessing model performance with metrics
- Why model validation is important
- Comparing Communications Mining™ and Google AutoML for conversational data intelligence
- Licensing
- FAQs and more

Communications Mining user guide
Validation
The Validation page shows users detailed information on the performance of their model, for both labels and general fields.
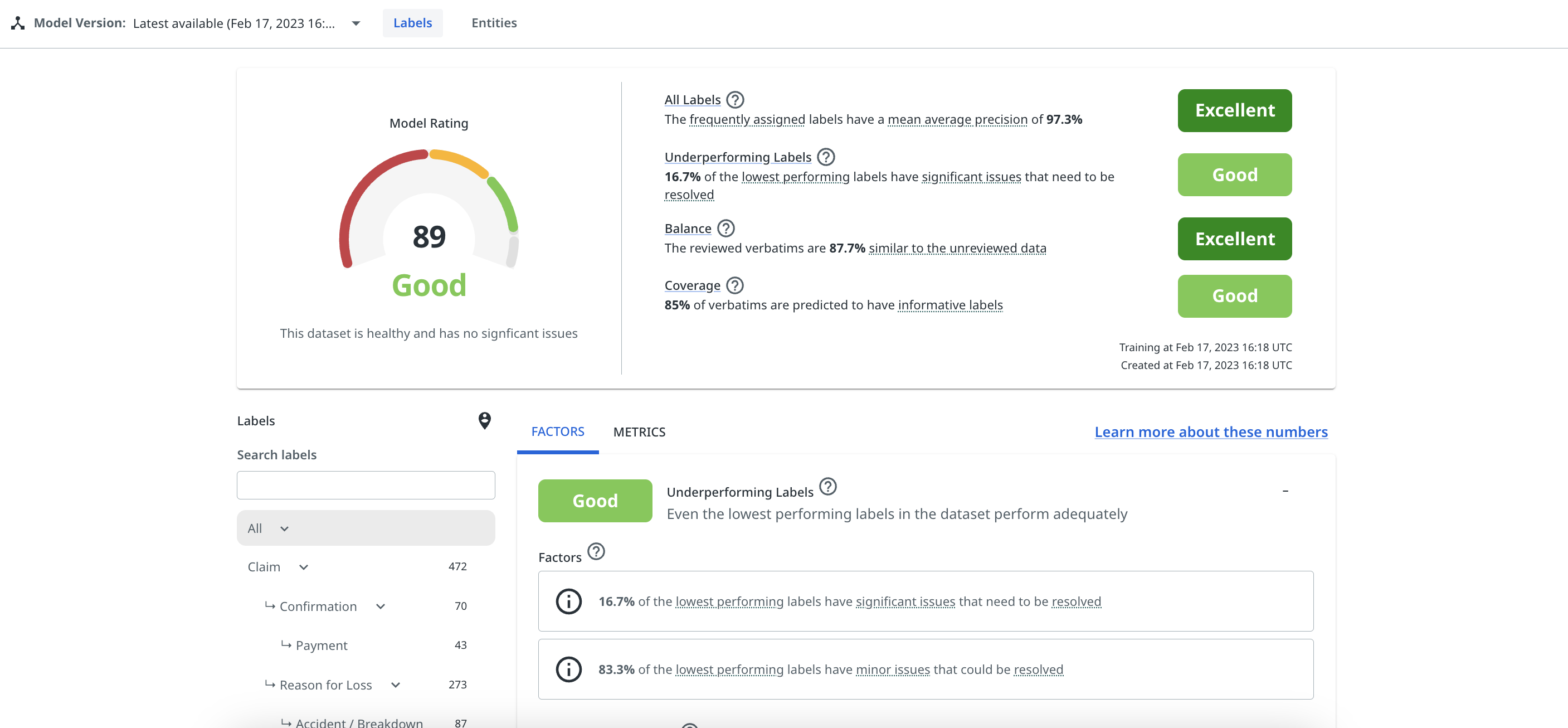
In the Labels tab, users can view their overall label Model Rating, including a detailed breakdown of the factors that make up their rating, and other metrics on their dataset and the performance of individual labels.
In the General fields tab, users can view statistics on the performance of general field predictions for all of the general fields enabled in the dataset.
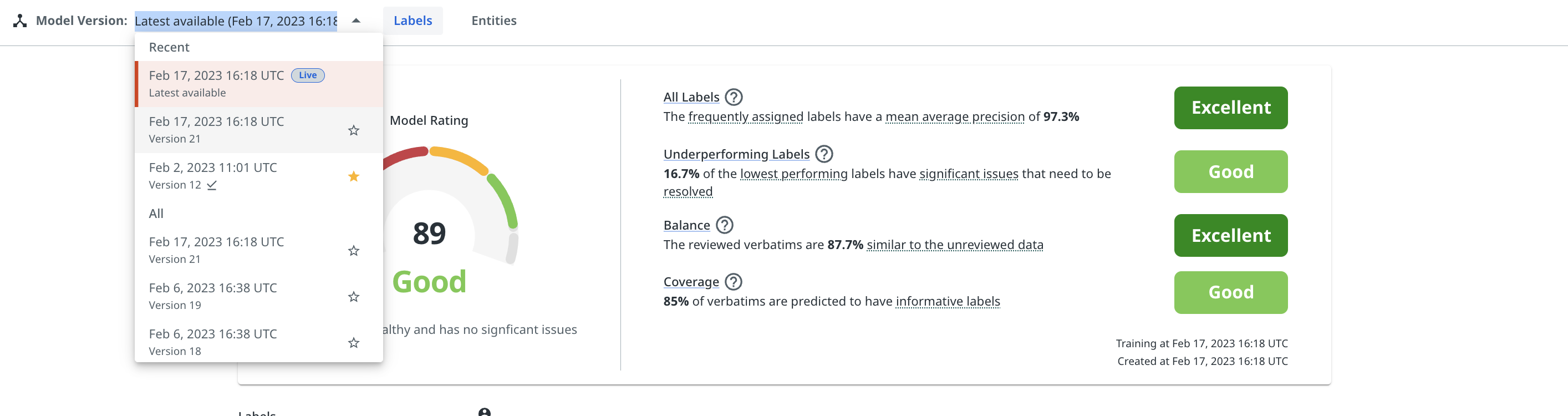
The Model Version dropdown menu allows you to view all validation scores across past model versions on a given dataset. You can also prioritize or star individual ones, so that they appear at the top of the list in the future. This tool can be useful for tracking and comparing progress as you build your model.
Labels
The Factors tab shows:
- the four key factors that contribute to model rating: balance, coverage, average label performance, and the performance of the worst-performing labels.
- for each factor, it provides a score and a breakdown of the factor score contributors.
- selectable recommended next best actions to improve the score of each factor.
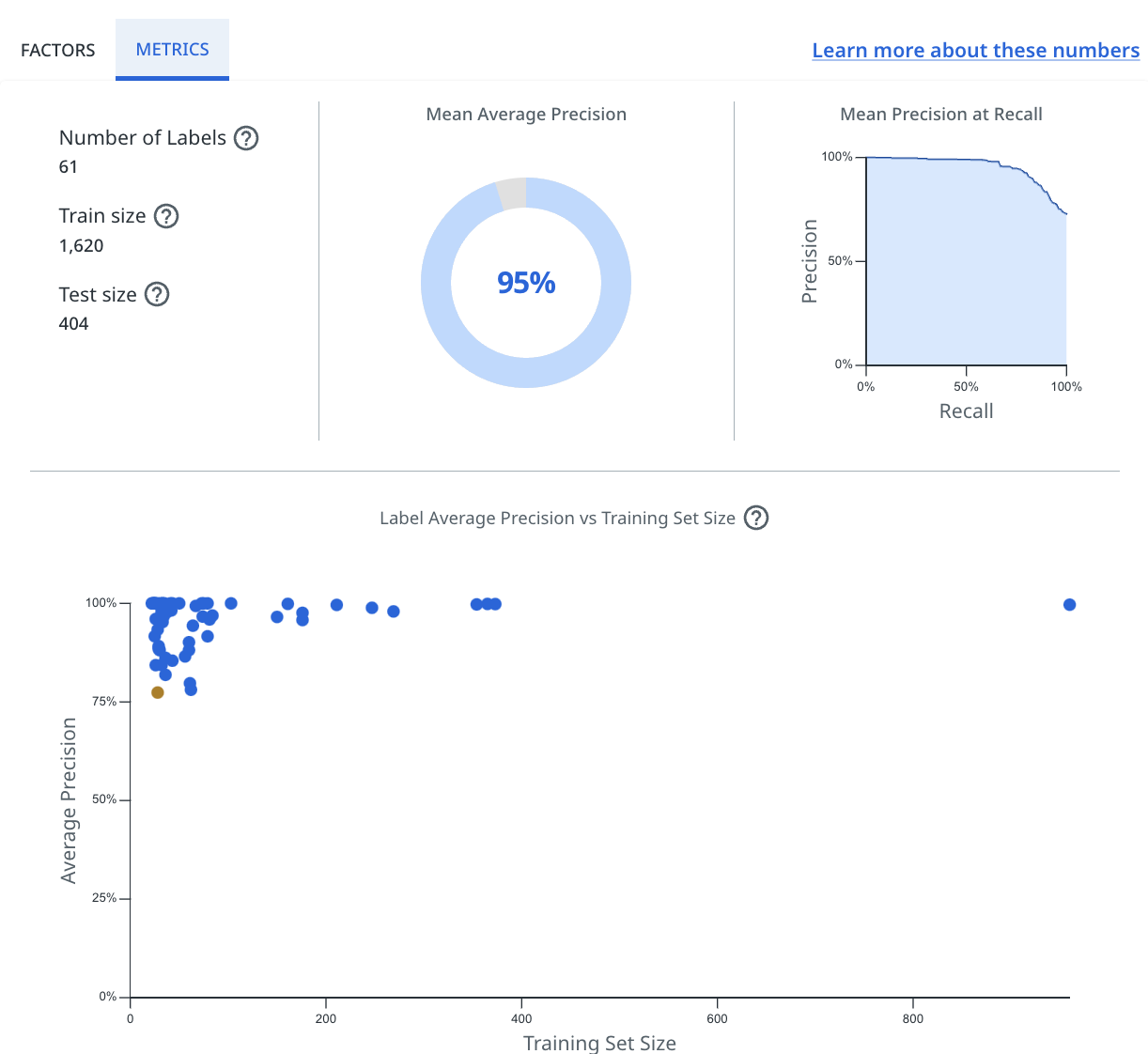
The Metrics tab shows:
-
the training set size – the number of messages on which the model was trained.
-
the test set size – the number of messages on which the model was evaluated.
-
number of labels – the total number of labels in your taxonomy.
-
Mean precision at recall – a graphic showing the average precision at a given recall value across all labels.
-
Mean average precision – a statistic showing the average precision across all labels.
-
a chart showing, across all labels, the average precision per label versus training set size.
The Validation page also allows users to select individual labels from their taxonomy to drill-down into their performance.
After selecting a label, users can view the average precision for that label, as well as the precision versus recall for that label based on a given confidence threshold, which users can adjust themselves.
For more details on how validation for labels actually works, and how to use it, check How validation works.
General fields
The General Fields tab shows:
- The number of general fields in the train set – the number of annotated general fields on which the validation model was trained.
- The number of general fields in the test set – the number of annotated general fields on which the validation model was evaluated.
- The number of messages in the train set – the number of messages that have annotated general fields in the train set.
- The number of messages in the test set – the number of messages that have annotated general fields in the test set
- Average precision - the average precision score across all general fields.
- Average recall - the average recall score across all general fields.
- Average F1 score - the average F1 score across all general fields, where the F1 score is the harmonic mean of precision and recall, and weights them equally.
- The same statistics, but for each individual general field.
For more details on how validation for general fields works, and how to use it, check Using general fields.