- Introduction
- Setting up your account
- Balance
- Clusters
- Concept drift
- Coverage
- Datasets
- General fields
- Labels (predictions, confidence levels, label hierarchy, and label sentiment)
- Models
- Streams
- Model Rating
- Projects
- Precision
- Recall
- Annotated and unannotated messages
- Extraction Fields
- Sources
- Taxonomies
- Training
- True and false positive and negative predictions
- Validation
- Messages
- Access control and administration
- Manage sources and datasets
- Understanding the data structure and permissions
- Creating or deleting a data source in the GUI
- Preparing data for .CSV upload
- Uploading a CSV file into a source
- Creating a dataset
- Multilingual sources and datasets
- Enabling sentiment on a dataset
- Amending dataset settings
- Deleting a message
- Deleting a dataset
- Exporting a dataset
- Using Exchange integrations
- Model training and maintenance
- Understanding labels, general fields, and metadata
- Label hierarchy and best practices
- Comparing analytics and automation use cases
- Turning your objectives into labels
- Overview of the model training process
- Generative Annotation
- Dastaset status
- Model training and annotating best practice
- Training with label sentiment analysis enabled
- Understanding data requirements
- Train
- Introduction to Refine
- Precision and recall explained
- Precision and Recall
- How validation works
- Understanding and improving model performance
- Reasons for label low average precision
- Training using Check label and Missed label
- Training using Teach label (Refine)
- Training using Search (Refine)
- Understanding and increasing coverage
- Improving Balance and using Rebalance
- When to stop training your model
- Using general fields
- Generative extraction
- Using analytics and monitoring
- Automations and Communications Mining™
- Developer
- Uploading data
- Downloading data
- Exchange Integration with Azure service user
- Exchange Integration with Azure Application Authentication
- Exchange Integration with Azure Application Authentication and Graph
- Migration Guide: Exchange Web Services (EWS) to Microsoft Graph API
- Fetching data for Tableau with Python
- Elasticsearch integration
- General field extraction
- Self-hosted Exchange integration
- UiPath® Automation Framework
- UiPath® official activities
- How machines learn to understand words: a guide to embeddings in NLP
- Prompt-based learning with Transformers
- Efficient Transformers II: knowledge distillation & fine-tuning
- Efficient Transformers I: attention mechanisms
- Deep hierarchical unsupervised intent modelling: getting value without training data
- Fixing annotating bias with Communications Mining™
- Active learning: better ML models in less time
- It's all in the numbers - assessing model performance with metrics
- Why model validation is important
- Comparing Communications Mining™ and Google AutoML for conversational data intelligence
- Licensing
- FAQs and more

Communications Mining user guide
Coverage
Coverage is a term frequently used in machine learning (ML), and relates to how well a model covers the data it used to analyse. In Communications Mining™, this relates to the proportion of messages in the dataset that have informative label predictions, and is presented in the Validation page as a percentage score.
Informative labels are those labels that the platform understands to be useful as standalone labels, by looking at how frequently they are assigned with other labels. Labels that are always assigned with another label are down-weighted when the score is calculated. For example, parent labels that are never assigned on their own, or Urgent, if it is always assigned with another label.
The following visual shows what low versus high coverage would look like across an entire dataset. Imagine the shaded circles are messages that have informative label predictions:
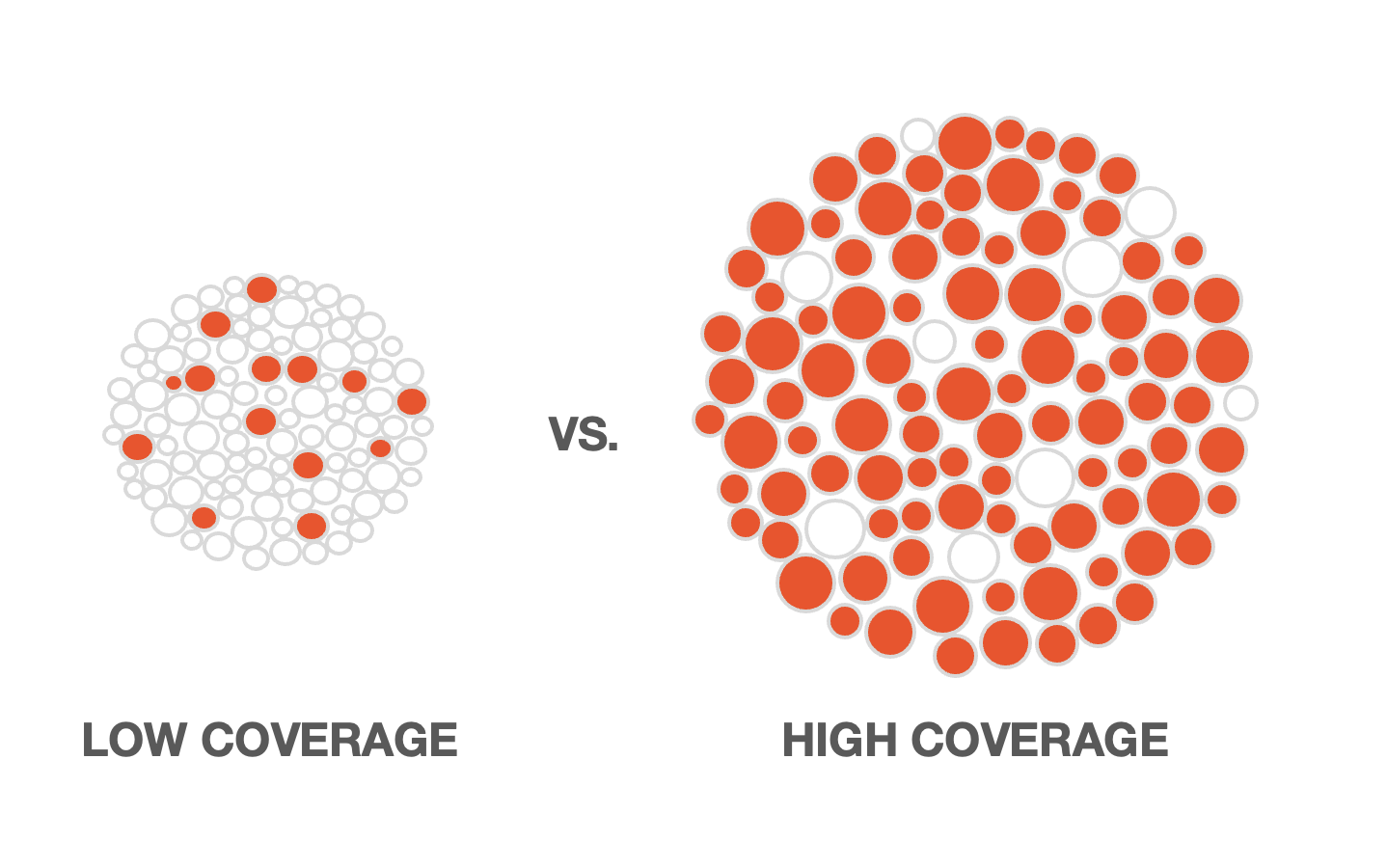
As a metric, coverage is a very helpful way of understanding if you have captured all of the different potential concepts in your dataset, and whether you have provided enough varied training examples for them so that the platform can effectively predict them.
In almost all cases, the higher the coverage of a model is, the better it performs, but you should not take it into account in isolation when checking model performance.
It is also very important that the labels in the taxonomy are healthy, meaning that they have high average precision, and no other performance warnings, and that the training data is a balanced representation of the dataset as a whole.
If your labels are unhealthy or the training data is not representative of the dataset, then the coverage of your model that the platform calculates will be unreliable.
Your model having high coverage is particularly important if you are using it to drive automated processes.
For more details on model coverage, and how to check the coverage of your model, check Understanding and improving model performance.