- Introduction
- Setting up your account
- Balance
- Clusters
- Concept drift
- Coverage
- Datasets
- General fields
- Labels (predictions, confidence levels, label hierarchy, and label sentiment)
- Models
- Streams
- Model Rating
- Projects
- Precision
- Recall
- Annotated and unannotated messages
- Extraction Fields
- Sources
- Taxonomies
- Training
- True and false positive and negative predictions
- Validation
- Messages
- Access control and administration
- Manage sources and datasets
- Understanding the data structure and permissions
- Creating or deleting a data source in the GUI
- Preparing data for .CSV upload
- Uploading a CSV file into a source
- Creating a dataset
- Multilingual sources and datasets
- Enabling sentiment on a dataset
- Amending dataset settings
- Deleting a message
- Deleting a dataset
- Exporting a dataset
- Using Exchange integrations
- Model training and maintenance
- Understanding labels, general fields, and metadata
- Label hierarchy and best practices
- Comparing analytics and automation use cases
- Turning your objectives into labels
- Overview of the model training process
- Generative Annotation
- Dastaset status
- Model training and annotating best practice
- Training with label sentiment analysis enabled
- Understanding data requirements
- Train
- Introduction to Refine
- Precision and recall explained
- Precision and Recall
- How validation works
- Understanding and improving model performance
- Reasons for label low average precision
- Training using Check label and Missed label
- Training using Teach label (Refine)
- Training using Search (Refine)
- Understanding and increasing coverage
- Improving Balance and using Rebalance
- When to stop training your model
- Using general fields
- Generative extraction
- Using analytics and monitoring
- Automations and Communications Mining™
- Developer
- Uploading data
- Downloading data
- Exchange Integration with Azure service user
- Exchange Integration with Azure Application Authentication
- Exchange Integration with Azure Application Authentication and Graph
- Migration Guide: Exchange Web Services (EWS) to Microsoft Graph API
- Fetching data for Tableau with Python
- Elasticsearch integration
- General field extraction
- Self-hosted Exchange integration
- UiPath® Automation Framework
- UiPath® official activities
- How machines learn to understand words: a guide to embeddings in NLP
- Prompt-based learning with Transformers
- Efficient Transformers II: knowledge distillation & fine-tuning
- Efficient Transformers I: attention mechanisms
- Deep hierarchical unsupervised intent modelling: getting value without training data
- Fixing annotating bias with Communications Mining™
- Active learning: better ML models in less time
- It's all in the numbers - assessing model performance with metrics
- Why model validation is important
- Comparing Communications Mining™ and Google AutoML for conversational data intelligence
- Licensing
- FAQs and more

Communications Mining user guide
Training using Teach Label (Explore)
You must have assigned the Source - Read and Dataset - Review permissions as an Automation Cloud user, or the View sources and Review and annotate permissions as a legacy user.
Teach is the second step in the Explore phase and its purpose is to show predictions for a label where the model is most confused if it applies or not. Like previous steps, we need to confirm if the prediction is correct or incorrect, and by doing so provide the model strong training signals. It is the most important label-specific training mode.
Teach Label is a training mode designed exclusively for annotating unreviewed messages. As such, the reviewed filter is disabled in this mode.
Key steps
-
Select Teach Label from the dropdown menu as shown in the following image.
-
Select the label you wish to train, where the default selection in Teach mode is to show unreviewed messages.
-
You will be presented with a selection of messages where the model is most confused as to whether the selected label applied or not. This means you should review the predictions and apply the label if they are correct, or apply other labels if they are incorrect.
Note:- Predictions will range outwards from ~50% for data with no sentiment and 66% for data with sentiment enabled.
- Make sure you apply all other labels that apply as well as the specific label you are focusing on.
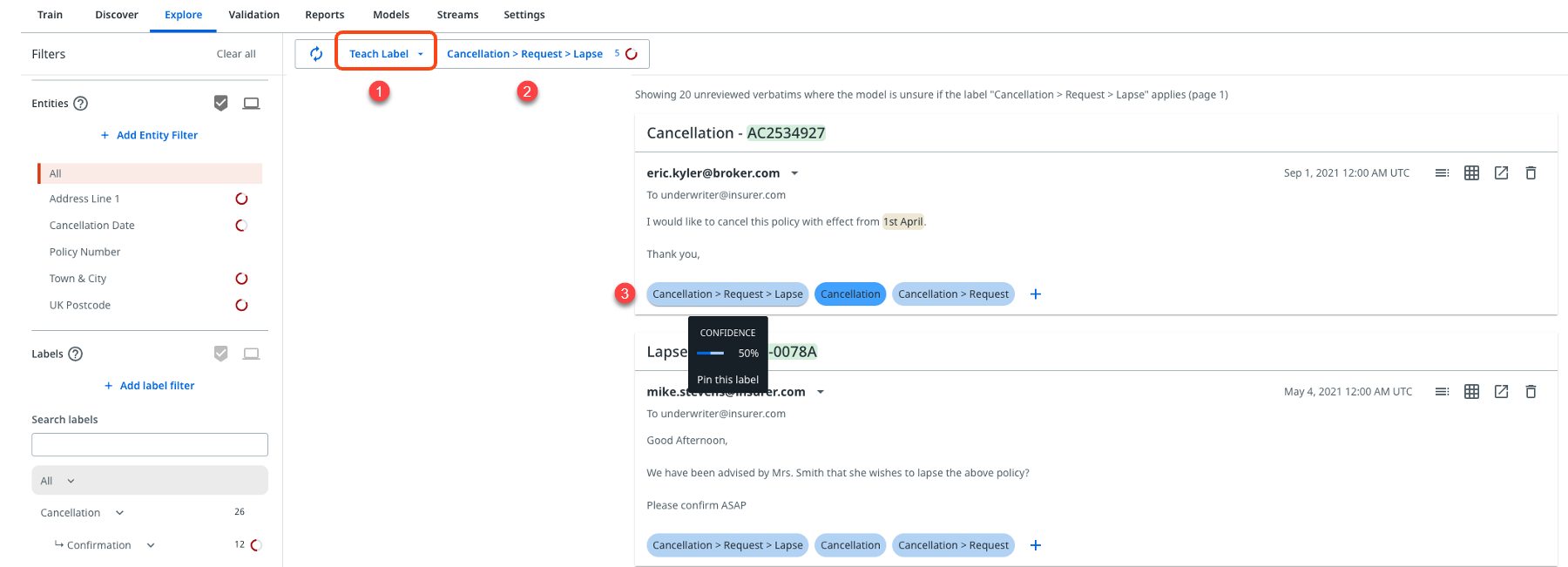
You should use this training mode as required to boost the number of training examples for each label to above 25, so that the platform can then accurately estimate the performance of the label.
The number of examples required for each label to perform well will depend on a number of factors. In the Refine phase we cover how to understand and improve the performance of each label.
The platform will regularly recommend using Teach Label as a means of improving the performance of specific labels by providing more varied training examples that it can use to identify other instances in your dataset where the label should apply.
Solutions for insufficient Teach examples
You may find after Discover and Shuffle that some labels still have very few examples, and where Teach Label mode does not surface useful training examples. In this case, you are recommended to use the following training modes to provide the platform with more examples to learn from:
Option 1 - Search
Searching for terms or phrases in Explore works the same as searching in Discover. One of two key differences is that in Explore you must review and annotate search results individually, rather than in bulk. You can search in Explore by simply typing in your search term in the search box at the top left of the page.
However, too much Search can biasyour model which is something we want to avoid. Add no more than 10 examples per label in this training mode to avoid annotating bias. Make sure you also allow the platform time to retrain before going back to Teach mode.
For more details, check Training using Search in the Explore tab.
Option 2 - Label
Although training using Label is not one of the main steps outlined in the Explore phase, it can still be useful in this phase of training. In Label mode, the platform shows you messages where that label is predicted in descending order of confidence, that is, with the most confident predictions first and least confident at the bottom.
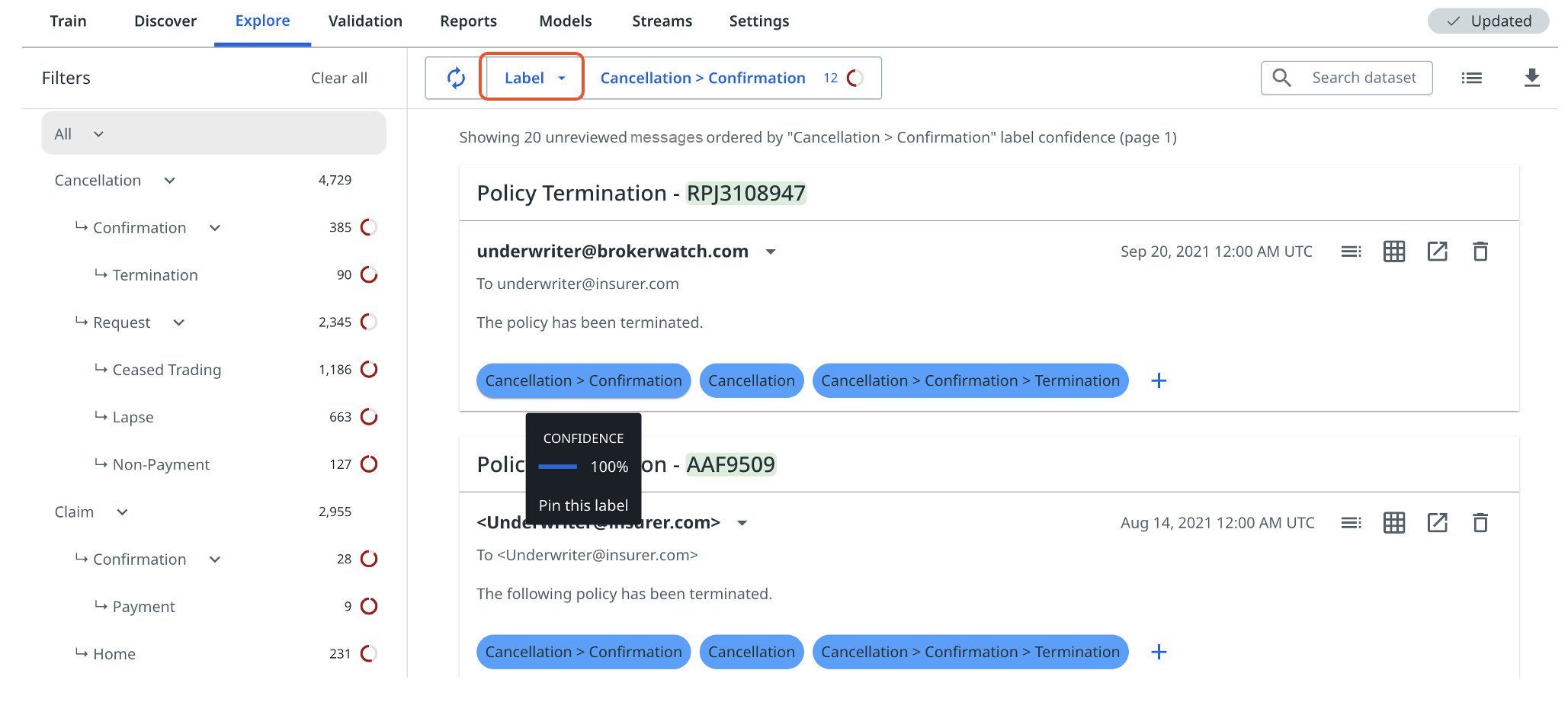
However, it is only useful to review predictions that are not high-confidence, above 90%. This is because when the model is very confident, that is, above 90%, then by confirming the prediction you are not telling the model any new information, it is already confident that the label applies. Look for less confident examples further down the page if needed. Although, if predictions have high confidences and are wrong, then make sure to apply the correct labels, thus rejecting the incorrect predictions.
Useful tips
- If for a label there are multiple different ways of saying the same thing, for example, A, B, or C, make sure that you give the platform training examples for each way of saying it. If you give it 30 examples of A, and only a few of B and C, the model will struggle to pick up future examples of B or C for that label.
- Adding a new label to a mature taxonomy may mean it has not been applied to previously reviewed messages. This then requires going back and teaching the model on new labels, using the Missed label function.