- Introduction
- Setting up your account
- Balance
- Clusters
- Concept drift
- Coverage
- Datasets
- General fields
- Labels (predictions, confidence levels, label hierarchy, and label sentiment)
- Models
- Streams
- Model Rating
- Projects
- Precision
- Recall
- Annotated and unannotated messages
- Extraction Fields
- Sources
- Taxonomies
- Training
- True and false positive and negative predictions
- Validation
- Messages
- Access control and administration
- Manage sources and datasets
- Understanding the data structure and permissions
- Creating or deleting a data source in the GUI
- Preparing data for .CSV upload
- Uploading a CSV file into a source
- Creating a dataset
- Multilingual sources and datasets
- Enabling sentiment on a dataset
- Amending dataset settings
- Deleting a message
- Deleting a dataset
- Exporting a dataset
- Using Exchange integrations
- Model training and maintenance
- Understanding labels, general fields, and metadata
- Label hierarchy and best practices
- Comparing analytics and automation use cases
- Turning your objectives into labels
- Overview of the model training process
- Generative Annotation
- Dastaset status
- Model training and annotating best practice
- Training with label sentiment analysis enabled
- Understanding data requirements
- Train
- Introduction to Refine
- Precision and recall explained
- Precision and Recall
- How validation works
- Understanding and improving model performance
- Reasons for label low average precision
- Training using Check label and Missed label
- Training using Teach label (Refine)
- Training using Search (Refine)
- Understanding and increasing coverage
- Improving Balance and using Rebalance
- When to stop training your model
- Using general fields
- Generative extraction
- Using analytics and monitoring
- Automations and Communications Mining™
- Developer
- Uploading data
- Downloading data
- Exchange Integration with Azure service user
- Exchange Integration with Azure Application Authentication
- Exchange Integration with Azure Application Authentication and Graph
- Migration Guide: Exchange Web Services (EWS) to Microsoft Graph API
- Fetching data for Tableau with Python
- Elasticsearch integration
- General field extraction
- Self-hosted Exchange integration
- UiPath® Automation Framework
- UiPath® official activities
- How machines learn to understand words: a guide to embeddings in NLP
- Prompt-based learning with Transformers
- Efficient Transformers II: knowledge distillation & fine-tuning
- Efficient Transformers I: attention mechanisms
- Deep hierarchical unsupervised intent modelling: getting value without training data
- Fixing annotating bias with Communications Mining™
- Active learning: better ML models in less time
- It's all in the numbers - assessing model performance with metrics
- Why model validation is important
- Comparing Communications Mining™ and Google AutoML for conversational data intelligence
- Licensing
- FAQs and more

Communications Mining user guide
Understanding and increasing coverage
You must have assigned the Source - Read and Dataset - Review permissions as an Automation Cloud user, or the View sources and Review and annotate permissions as a legacy user.
Coverage is a term frequently used in Machine Learning and relates to how well a model 'covers' the data it's used to analyse. In the platform, this relates to the proportion of messages in the dataset that have informative label predictions, and is presented in Validation as a percentage score.
Informative labels are those labels that the platform understands to be useful as standalone labels, by looking at how frequently they're assigned with other labels. Labels that are always assigned with another label, e.g. parent labels that are never assigned on their own or Urgent if it's always assigned with another label, are down-weighted when the score is calculated.
The following visual gives an indication of what low coverage versus high coverage would look like across an entire dataset. Imagine the shaded circles are messages that have informative label predictions.
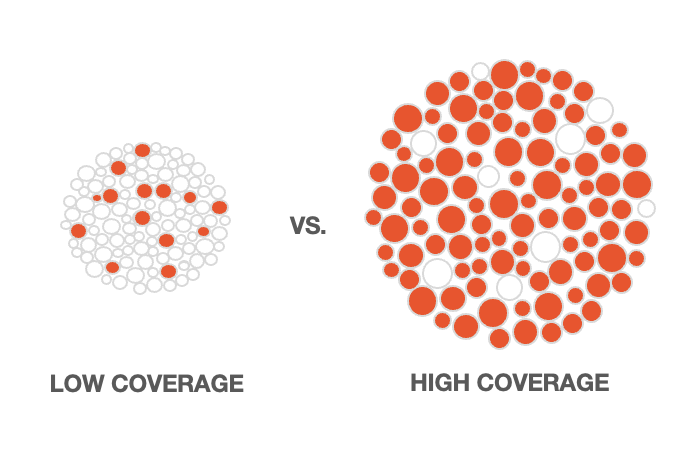
As a metric, coverage is a very helpful way of understanding if you've captured all of the different potential concepts in your dataset, and whether you've provided enough varied training examples for them so that the platform can effectively predict them.
In almost all cases, the higher the coverage of the model is, the better it performs, but it should not be considered in isolation when checking model performance.
Make sure that the labels in the taxonomy are healthy, meaning that they have high average precision and no other performance warnings, and that the training data is a balanced representation of the dataset as a whole. If your labels are unhealthy or the training data is not representative of the dataset, then the coverage of your model that the platform calculates will be unreliable.
Your model having high coverage is particularly important if you are using it to drive automated processes.
Coverage in context
Consider how coverage applies in a use case such as automatically routing different requests received by a shared email inbox in a business.
For a model designed to help automatically route different requests, low coverage would mean that lots of requests were inaccurately routed, or sent for manual review as the model could not identify them.
If there are 10 key processes managed by the team working in the mailbox, but the taxonomy only effectively captures 7 of those, this would likely lead to a poor coverage score. Alternatively the model may incorrectly predict the remaining processes as other processes, as it has not been taught what they actually are. This would lead to an artificially high coverage score.
During the automation the remaining three processes would likely be missed, sent for manual review, or falsely classified as a different process and routed to the wrong place.
It's also important that for each of the processes, there are sufficient varied training examples that capture the varied expressions used when discussing the process. If there are not, each label will have lower recall and the model's coverage will be low.
The following visual demonstrates how this example might look in practice - we have multiple clients sending multiple request types through email. Each client may write the same request type in a different way:
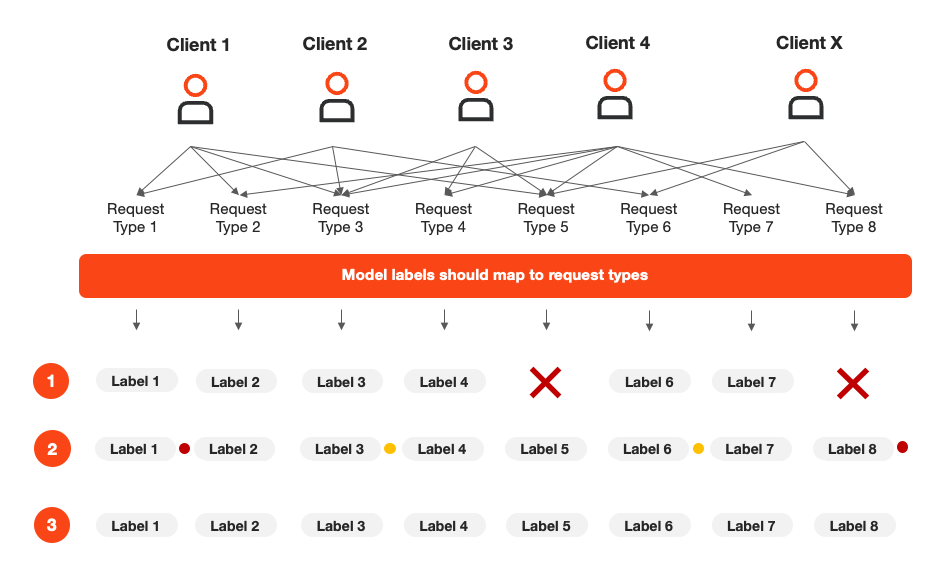
There are three different model scenarios shown, each with a different potential impact on coverage:
 | Not all request types, that is, the concepts covered by the taxonomy - Likely to have low coverage |
 | All request types covered, but some labels are unhealthy and may not have enough examples – Coverage may be low and is likely to be unreliable |
 | All request types covered and labels are all healthy – High coverage that's likely to be reliable |
Checking the model coverage
In Validation, the Model Rating functionality provides a detailed breakdown of model performance across the most important contributing factors, including coverage.
Users are provided with a percentage score of the proportion of messages that are predicted to have informative label predictions, which in turn correlates to a rating and a contribution to the overall model rating.
The platform also provided the proportion of messages that have at least one label predicted, but this is not what determines the score and the rating for this factor.
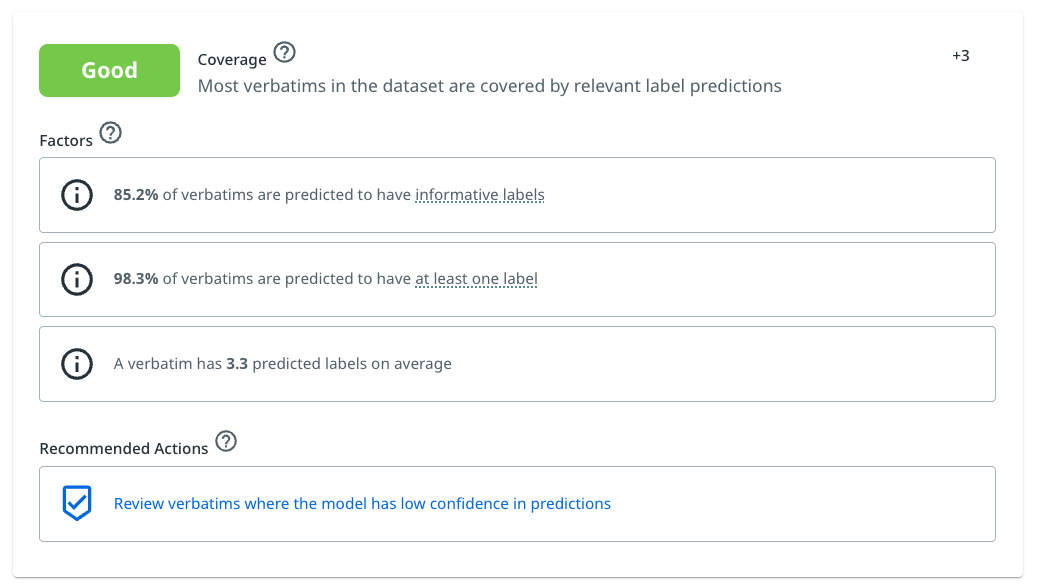
In the following example we can notice that:
- The coverage for this model is 85.2%.
- This translates to an assessed rating of Good for this factor.
- This also translates to a positive contribution to the overall model rating of +3.
Example breakdown of coverage shown in Validation
It's important to remember that coverage as a performance measure should always be understood in conjunction with the health of the labels in the taxonomy and the balance of the dataset. Before you consider the coverage score provided by the platform to be reliable, you should also ensure that you have at least a Good rating for the other factors that contribute to the Model Rating.
How high a model coverage should be
At a minimum, your coverage should be high enough that the platform provides a 'Good' rating. If it reaches this stage your model is performing well, and you can choose to optimize it further based on the requirements of your use case.
Just like humans, machine learning models do have their limits, so you should not expect to achieve 100% coverage. You may get close to this, but only if your data is extremely simple and repetitive, or you annotate a very high proportion of the dataset.
Reaching an Excellent rating can potentially be challenging depending on the data, and is not always necessary depending on the use case.
For automation focused use cases, having high coverage is particularly important, so it is likely in these instances you will want to optimise coverage as much as possible and achieve an Excellent rating.
For analytics focused use cases, having very high coverage is slightly less critical. It is often sufficient for models to be able to identify the most frequently occurring concepts, as these provide the greatest insights and potential opportunities for change and improvements.
It's worth noting that an analytics focused model will typically sacrifice some accuracy in order to broadly capture a very wide range of concepts in its' taxonomy.
Increasing the coverage of the model
Like for the other contributing factors, the platform provides useful recommended 'next best actions' that users can take to improve the coverage of your model. For more details, refer to the images in this section and the previous one.
The recommended actions act as links that take you directly to the suggested training mode.
In the case of coverage, the platform will most often recommend training in Low Confidence mode, as this mode allows users to annotate the least covered of all the messages in the dataset. For more details, check Training using Low confidence.
After completing a reasonable amount of training in the recommended training mode (how much will depend on how low the coverage is to start with), users can check back in to see how it has improved once the model has retrained and Validation has updated. If required, they can repeat the process to continue to improve their scores.
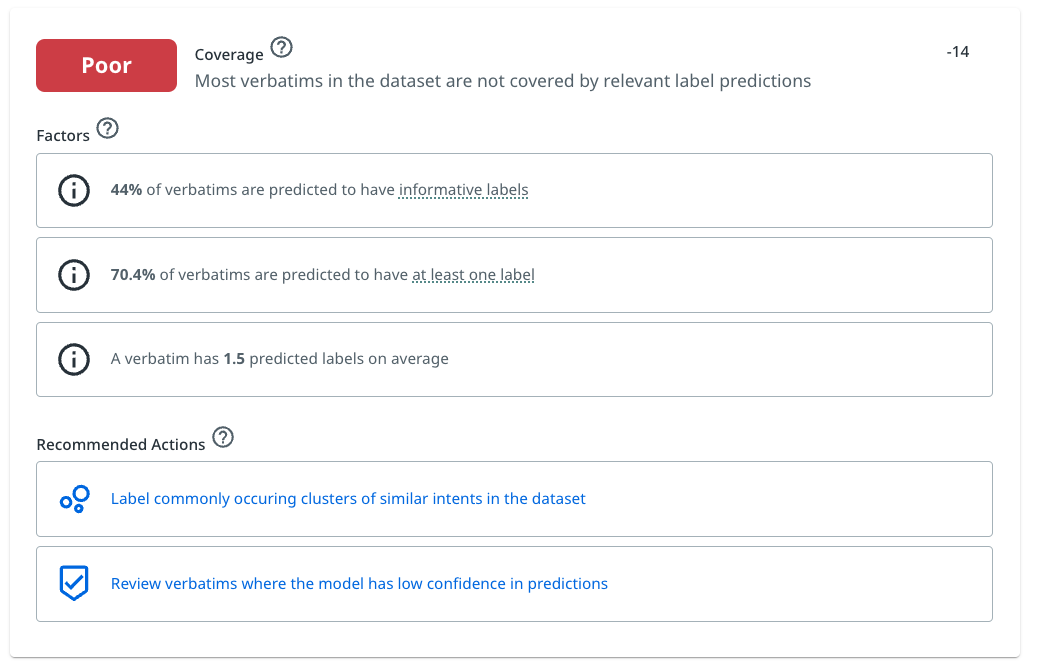
When coverage is very low, typically early on in the training process, the platform may also recommend other training modes it thinks would be beneficial, such as annotating clusters of similar messages in Discover as shown in the following example.
Example factor card showing low coverage for a model and recommended actions
Coverage check for specific labels
The platform is able to intelligently identify which labels in a taxonomy are 'informative' when assessing a model's coverage and presents this in the Model Rating.
If, however, you want to assess the proportion of a dataset that is likely to be covered by predictions for a specific set of labels in your taxonomy, you can do this in the Reports page.
To do so, you can select all of the labels in question in the label filter bar in Reports (as shown below).
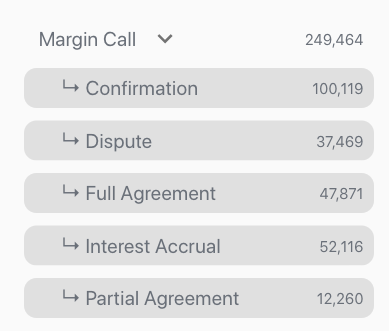
The message count at the top of the page in Reports updates based on filters applied. When you select labels from the label filter, the count updates to show the number of messages that are likely to have at least one of the selected labels predicted.
Message count in Reports

In this example dataset of emails solely relating to a margin call process in a bank (which contains 260,000 emails), you can see that it is likely that 237,551 messages out of the 260,000 will have at least one of the selected labels predicted. Indicating a good coverage of approximately 91.4%.
This should not be your only check to test the overall coverage of your model. The most reliable measure of coverage for the whole dataset is presented in the Model Rating, and should be considered in conjunction with the overall performance of the labels in the taxonomy.