- Introduction
- Setting up your account
- Balance
- Clusters
- Concept drift
- Coverage
- Datasets
- General fields
- Labels (predictions, confidence levels, label hierarchy, and label sentiment)
- Models
- Streams
- Model Rating
- Projects
- Precision
- Recall
- Annotated and unannotated messages
- Extraction Fields
- Sources
- Taxonomies
- Training
- True and false positive and negative predictions
- Validation
- Messages
- Access control and administration
- Manage sources and datasets
- Understanding the data structure and permissions
- Creating or deleting a data source in the GUI
- Preparing data for .CSV upload
- Uploading a CSV file into a source
- Creating a dataset
- Multilingual sources and datasets
- Enabling sentiment on a dataset
- Amending dataset settings
- Deleting a message
- Deleting a dataset
- Exporting a dataset
- Using Exchange integrations
- Model training and maintenance
- Understanding labels, general fields, and metadata
- Label hierarchy and best practices
- Comparing analytics and automation use cases
- Turning your objectives into labels
- Overview of the model training process
- Generative Annotation
- Dastaset status
- Model training and annotating best practice
- Training with label sentiment analysis enabled
- Understanding data requirements
- Train
- Introduction to Refine
- Precision and recall explained
- Precision and Recall
- How validation works
- Understanding and improving model performance
- Reasons for label low average precision
- Training using Check label and Missed label
- Training using Teach label (Refine)
- Training using Search (Refine)
- Understanding and increasing coverage
- Improving Balance and using Rebalance
- When to stop training your model
- Using general fields
- Generative extraction
- Using analytics and monitoring
- Automations and Communications Mining™
- Developer
- Uploading data
- Downloading data
- Exchange Integration with Azure service user
- Exchange Integration with Azure Application Authentication
- Exchange Integration with Azure Application Authentication and Graph
- Migration Guide: Exchange Web Services (EWS) to Microsoft Graph API
- Fetching data for Tableau with Python
- Elasticsearch integration
- General field extraction
- Self-hosted Exchange integration
- UiPath® Automation Framework
- UiPath® official activities
- How machines learn to understand words: a guide to embeddings in NLP
- Prompt-based learning with Transformers
- Efficient Transformers II: knowledge distillation & fine-tuning
- Efficient Transformers I: attention mechanisms
- Deep hierarchical unsupervised intent modelling: getting value without training data
- Fixing annotating bias with Communications Mining™
- Active learning: better ML models in less time
- It's all in the numbers - assessing model performance with metrics
- Why model validation is important
- Comparing Communications Mining™ and Google AutoML for conversational data intelligence
- Licensing
- FAQs and more

Communications Mining user guide
Generative Annotation
Generative Annotation uses the Microsoft Azure OpenAI endpoint to generate AI-suggested labels to accelerate taxonomy design and early phases of model training, as well as reduce time-to-value for all Communications Mining™ use cases.
Generative Annotation includes:
- Cluster Suggestions - Suggested new or existing labels for clusters based on their identified themes.
- Assisted Annotating - Automatic predictions for labels based on the label names or descriptions.
Using Generative Annotation
Generative Annotation features are automatically enabled on datasets, no further action required.
Once a dataset is created, cluster suggestions are automatically generated within a short period of time. If a taxonomy has been uploaded, which is highly recommended, Communications Mining™ suggests both existing and new labels for clusters.
When you upload a taxonomy to a dataset, this also automatically triggers an initial model to be trained with no training data, only using label names and descriptions. This action may take a few minutes from when you have uploaded the taxonomy.
- For Cluster Suggestions, go to the Train tab, and select a clusters batch. Alternatively, go to the Discover tab, and select the Cluster mode to start annotating.
- For Assisted Annotating, go to the Train tab, and follow the recommended actions. Alternatively, go to the Explore tab, and select Shuffle or Teach Label mode to start annotating.
Note:
These features are not be available if your organization disabled the Azure OpenAI services.
Using Cluster Suggestions
You must have assigned the IXP Model Trainer role as an Automation Cloud™ user, or the Review and label permission as a legacy user.
Cluster suggestions will appear for each Cluster page. This can be one or multiple suggested labels for each cluster.
If you have Label sentiment analysis enabled, Cluster Suggestions will have a positive or negative sentiment, which can be highlighted in green or red.
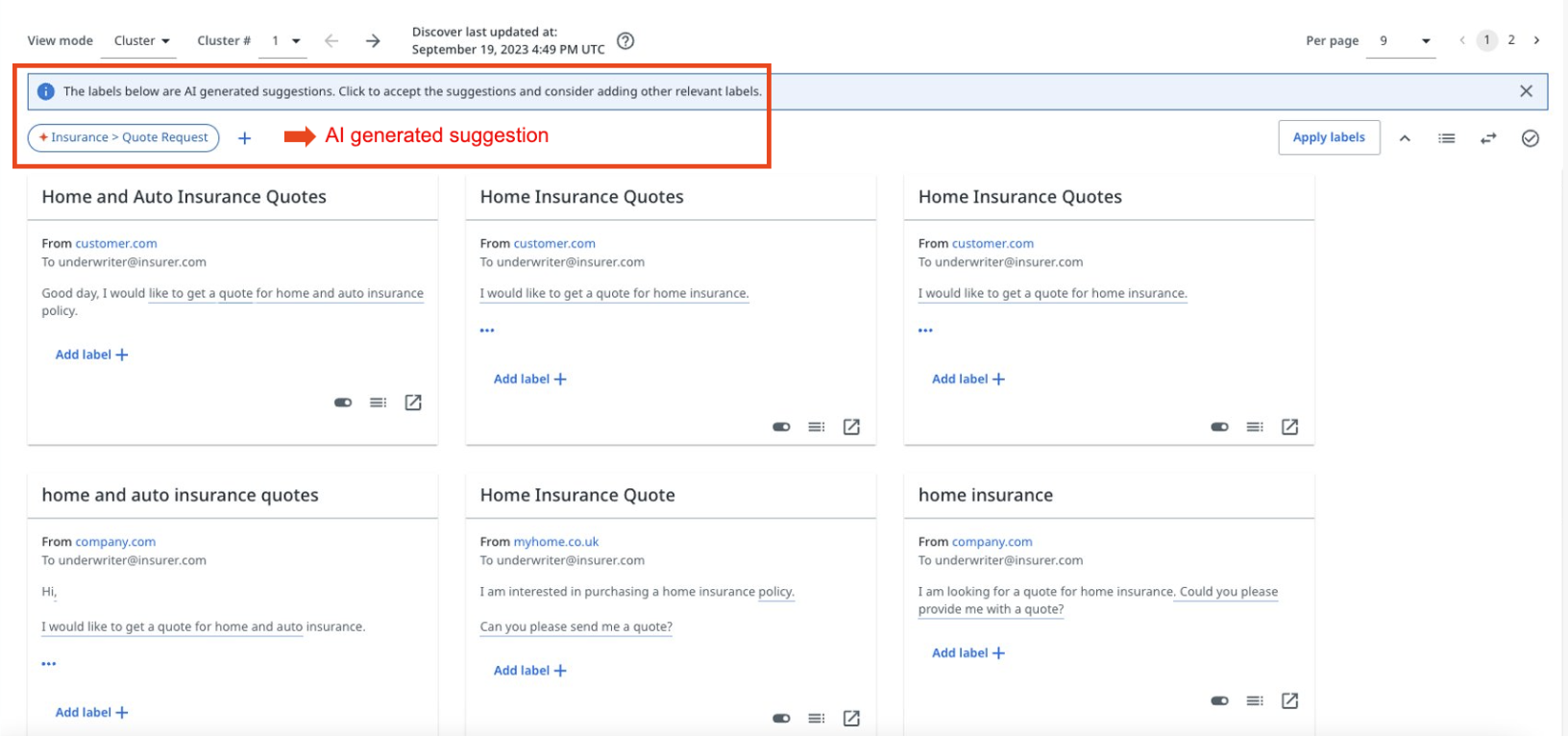
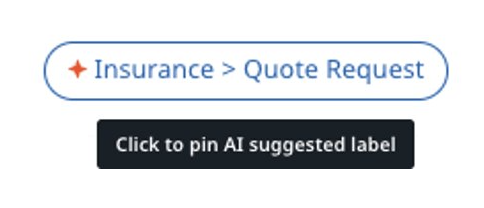
To identify an AI-suggested label, check the following image:
Model trainers should review each cluster suggestion, and perform one of the following::
- Accept it by selecting it.
- Assign a new label, if they do not agree with the given suggestion.
How Cluster suggestions support Model Training
Cluster suggestions can significantly speed up the first phase of the model training process by automatically generating suggested labels for each cluster. It can also help with taxonomy design, if users are struggling to define the concepts they want to train.
Cluster suggestions are generated based on the identified theme shared across the messages within a cluster.
The creation of clusters and generation of label suggestions is an automatic and completely unsupervised process with no human input required.
Label suggestions on clusters will be generated with or without a pre-defined taxonomy, but suggestions will be influenced and typically made more helpful by leveraging imported or existing labels.
Using Assisted Annotating
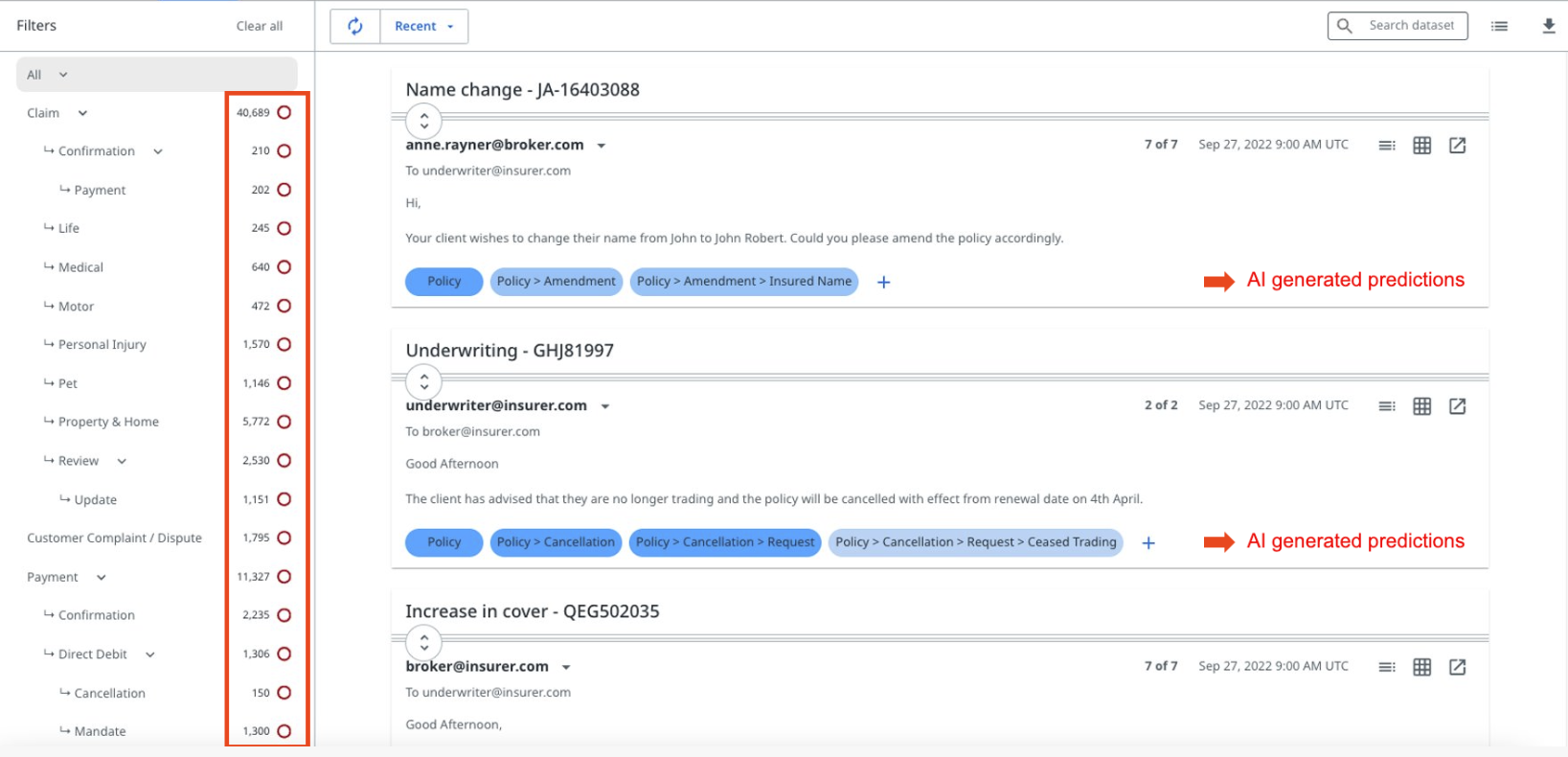
Prerequisites:
- You must have assigned the IXP Model Trainer role as an Automation Cloud™ user, or the Review and label permission as a legacy user.
- An imported list of label names.
- Optionally, an imported list of label descriptions is highly recommended. The platform uses descriptions as a training input to make predictions, so make sure you are clear and concise when describing the label concept.
Once the initial model has automatically trained using label names and descriptions as its training input, predictions will appear for many of the messages in the dataset.
These predictions work in the exact same way as they have done previously, meaning that they are just generated with no training data.
If you have Label sentiment analysis enabled, initial predictions will have either a positive or negative sentiment in different shades of green or red, depending on the confidence level.
Assisted Annotating works in any training batch or mode, but it is most effective to use in Shuffle and Teach Label. You should follow the regular annotating steps in each training batch in the Train or Explore tabs.
How Assisted Annotating supports model training
Assisted Annotating can significantly speed up the second phase of the model training process by automatically generating predictions for each label with sufficient context, with no training examples required.
Initial predictions will be driven by the quality of the label names and natural language descriptions, such as vague names might lead to vague or minimal predictions. Detailed label descriptions can boost the initial performance of the model.
As you train your dataset further, the platform uses both the label names and descriptions and your pinned examples to generate relevant label predictions.
These will keep improving with more training and ultimately rely only on annotated training examples when enough have been provided.
Assisted Annotating still requires supervised learning by accepting or rejecting the predictions, but it accelerates the most time-consuming part of model training by providing better predictions with zero or very few pinned examples.