- Información general
- Automatización de IU
- Acerca del paquete de actividades de automatización de IU
- Aplicaciones y tecnologías automatizadas con UI Automation
- Compatibilidad de proyectos
- UI-ANA-016: Introducir URL para abrir el navegador
- UI-ANA-017: ContinueOnError verdadero
- UI-ANA-018: enumerar actividades de OCR / imagen
- UI-DBP-006: uso del contenedor
- UI-DBP-013: uso incorrecto de la automatización de Excel
- UI-DBP-030: uso de variables prohibidas en selectores
- UI-DBP-031: verificación de actividad
- UI-PRR-001: Simular clic
- UI-PRR-002: Simular tipo
- UI-PRR-003: uso incorrecto de aplicación abierta
- UI-PRR-004: retrasos codificados
- UI-REL-001: Idx grande en selectores
- UI-SEC-004: datos de correo electrónico del selector
- UI-SEC-010: Restricciones de aplicaciones / URL
- UI-USG-011: atributos no permitidos
- UX-SEC-010: restricciones de aplicaciones / URL
- UX-DBP-029: uso no seguro de contraseña
- UI-PST-001: nivel de registro de auditoría en la configuración del proyecto
- Herramienta de migración del navegador de UiPath
- Recorte de región
- Grabadora de Computer Vision
- Acerca de la automatización de imágenes y texto
- Actividades con el ratón y el teclado
- Ejemplo de uso de la automatización de ratón y teclado
- Actividades de texto
- Ejemplo de uso de la automatización de texto
- Actividades de OCR
- Actividades de imagen
- Ejemplo de uso de la automatización de OCR y la automatización de imágenes
- Índice de actividades
- Activar
- Base de anclaje
- Asociar navegador
- Asociar ventana
- Bloquear entrada de usuario
- Aviso
- Comprobar
- Clic
- Clic en imagen
- Desencadenador de clic de imagen
- Clic en texto OCR
- Clic en el texto
- Desencadenador de clic
- Cerrar aplicación
- Cerrar pestaña
- Cerrar ventana
- Anclaje consciente de contexto
- Copiar texto seleccionado
- Desencadenador de cambio del atributo del elemento
- Elemento existente
- Ámbito del elemento
- Desencadenador de cambio de estado de elemento
- Exportar el árbol de la IU
- Extraer datos estructurados
- Buscar elementos secundarios
- Buscar elemento
- Buscar imagen
- Buscar coincidencias de imágenes
- Buscar texto OCR
- Buscar elemento relativo
- Buscar posición de texto
- Obtener ventana activa
- Obtener antecesor
- Obtener atributo
- Obtener información de atributo
- Obtener a partir del portapapeles
- Obtener texto completo
- Obtener texto OCR
- Obtener contraseña
- Obtener posición
- Obtener elemento de origen
- Obtener texto
- Obtener texto visible
- Volver
- Avanzar
- Ir a inicio
- Google Cloud Vision OCR
- Ocultar ventana
- Resaltar
- Desencadenador de tecla de acceso rápido
- Mantener el puntero
- Mantener el puntero en imagen
- Mantener el puntero sobre texto OCR
- Mantener el puntero en el texto
- Imagen existente
- Indicar en pantalla
- Insertar código .NET
- Inject Js Script
- Invocar método de ActiveX
- Desencadenador de pulsación de tecla
- Cargar imagen
- Maximizar ventana
- Microsoft Azure Computer Vision OCR
- Microsoft OCR
- Microsoft Project Oxford Online OCR
- Minimizar ventana
- Supervisar eventos
- Desencadenador del ratón
- Mover ventana
- Ir a
- Texto OCR existente
- Apariencia en elemento
- Fuga en elemento
- Apariencia en imagen
- Fuga en imagen
- Abrir aplicación
- Abrir navegador
- Actualizar navegador
- Reproducir evento de usuario
- Restaurar ventana
- Guardar imagen
- Seleccionar elemento
- Seleccionar varios elementos
- Enviar tecla de acceso rápido
- Establecer región de recorte
- Establecer foco
- Establecer texto
- Establecer en portapapeles
- Establecer atributo web
- Mostrar ventana
- Iniciar proceso
- Desencadenador del sistema
- Realizar captura
- Tesseract OCR
- Texto existente
- Información sobre herramientas
- Escribir en
- Escribir Texto Seguro
- Utilizar primer plano
- Esperar a atributo
- Esperar a fuga de elemento
- Esperar a fuga de imagen
- Comprobación de accesibilidad
- Desencadenador de eventos de aplicación
- Bloquear entrada de usuario
- Marcar/Desmarcar
- Comprobar estado de aplicación
- Comprobar elemento
- Clic
- Clic desencadenador de eventos
- Arrastrar y soltar
- Extraer datos de tabla
- Buscar elementos
- Para cada elemento de interfaz de usuario
- Obtener datos del navegador
- Obtener Portapapeles
- Obtener texto
- Obtener URL
- Ir a URL
- Resaltar
- Mantener el puntero
- Inject Js Script
- Atajos del teclado
- Desencadenador de eventos de pulsación de tecla
- Desplazamiento del ratón
- Navegar por el navegador
- Seleccionar elemento
- Establecer datos del navegador
- Configurar el portapapeles
- Establecer navegador de Runtime
- Establecer foco
- Establecer texto
- Realizar captura
- Escribir en
- Desbloquear entrada de usuario
- Utilizar Aplicación/Navegador
- Operación de ventana
- Transacción de llamada
- Clic en imagen en pantalla
- Hacer clic en botón de barra de herramientas
- Expandir tabla jerárquica ALV
- Expandir árbol ALV
- Expandir árbol
- Lectura de barra de estado
- Inicio de sesión en SAP
- Inicio de sesión en SAP
- Desencadenador de cambio de atributos de sesión de SAP
- Seleccionar fechas en el calendario
- Seleccionar elemento de menú
- Ámbito de la celda de la tabla
- Transacción de llamada
- Clic en imagen en pantalla
- Hacer clic en botón de barra de herramientas
- Expandir tabla jerárquica ALV
- Expandir árbol ALV
- Expandir árbol
- Lectura de barra de estado
- Inicio de sesión en SAP
- Inicio de sesión en SAP
- Seleccionar fechas en el calendario
- Seleccionar elemento de menú
- Ámbito de la celda de la tabla
- Realizar búsquedas en el navegador y recuperar resultados mediante las API de automatización de IU
- Exploración web
- Buscar imágenes
- Hacer clic en imágenes
- Eventos de desencadenador y supervisor
- Crear y anular archivos
- Páginas HTML: extraer y manipular información
- Manipulación de ventana
- Selección de lista automatizada
- Buscar y manipular elementos de ventana
- Gestionar automatización de texto
- Cargar y procesar imágenes
- Gestionar acciones activadas por el ratón
- Automatizar tiempo de ejecución de aplicación
- Ejecución automática de una aplicación local
- Navegación de explorador
- Automatización web
- Ejemplo de ámbito de desencadenador
- Habilitar soporte de automatización de IU en DevExpress
- Computer Vision Local Server
- Automatización móvil
- Notas relacionadas
- Acerca de la arquitectura de automatización de dispositivos móviles
- Compatibilidad de proyectos
- Obtener tipos de registro
- Obtener registros
- Obtener origen de la página
- Obtener la orientación del dispositivo
- Obtener identificador de sesión
- Instalar aplicación
- Administrar aplicación actual
- Administrar otras aplicaciones
- Abrir enlace profundo
- Abrir URL
- Conexión de dispositivo móvil
- Deslizamiento direccional
- Patrón de dibujo
- Pase de dedo posicional
- Pulse un botón del hardware
- Establecer orientación del dispositivo
- Realizar captura
- Tomar parte de la captura de pantalla
- Elemento existente
- Ejecutar comando
- Obtener atributo
- Obtener elemento seleccionado
- Obtener texto
- Establecer elemento seleccionado
- Establecer texto
- Deslizamiento
- Pulsar
- Escribir Texto
- Primeros pasos con las API de automatización móvil
- Gestionar cuadros de diálogo emergentes en automatizaciones móviles
- Creating variables from selector attributes
- Creación de flujos de trabajo de automatización móvil
- Utilizar automatización móvil para una aplicación de banca móvil
- Automatización para aplicaciones React Native
- Terminal
- Notas relacionadas
- Acerca del paquete de actividades de Terminal
- Compatibilidad de proyectos
- Mejores prácticas
- Buscar texto
- Obtener color de la posición
- Obtener la posición del cursor
- Obtener campo
- Obtener campo en posición
- Obtener área de pantalla
- Obtener texto
- Obtener texto en posición
- Mover cursor
- Mover cursor al texto
- Enviar tecla de control
- Teclas de envío
- Teclas de envío seguras
- Establecer campo
- Configurar campo en posición
- Sesión del terminal
- Esperar texto de campo
- Esperar a que la pantalla esté lista
- Esperar texto en pantalla
- Esperar texto en posición

Actividades UIAutomation
Métodos de salida o raspado de pantalla
Los métodos de salida o extracción de pantalla hacen referencia a aquellas actividades que te permiten extraer datos de un elemento o documento concreto de la IU, como puede ser un archivo .pdf.
Para entender cuál es mejor para automatizar el proceso de tu negocio, vamos a ver las diferencias entre ambos.
| Método de capacidad | Velocidad | Precisión | Ejecución en segundo plano | Extraer la posición del texto | Extraer el texto oculto | Soporte para Citrix |
|---|---|---|---|---|---|---|
| Texto completo | 10/10 | 100 % | Sí | No | Sí | No |
| Nativo | 8/10 | 100 % | No | Sí | No | No |
| OCR | 3/10 | 98 % | No | Sí | No | Sí |
TextoCompleto es el método predeterminado, es rápido y preciso, pero al contrario que el método Nativo, no puede extraer las coordenadas de pantalla del texto.
Ambos métodos funcionan únicamente con aplicaciones de escritorio pero el método Nativo solo funciona con las aplicaciones diseñadas para representar texto con la interfaz de dispositivos gráficos (GDI).
El OCR no es 100 % preciso, pero puede ser útil a la hora de extraer el texto que los otros dos métodos no hayan podido, ya que funciona con todas las aplicaciones, Citrix incluida. Studio utiliza dos motores OCR, de forma predeterminada: Google Tesseract y Microsoft Modi.
Los idiomas se pueden cambiar para los motores de OCR y puedes averiguar cómo Instalar idiomas de OCR.
| Método de capacidad | Compatibilidad con múltiples idiomas | Tamaño de área preferido | Soporte para la Inversión del color | Establece el Formato de texto previsto | Filtra los Caracteres permitidos | Mejor con fuentes de Microsoft |
|---|---|---|---|---|---|---|
| Google Tesseract | Se puede añadir | Pequeño | Sí | Sí | Sí | No |
| Microsoft MODI | Compatible de forma predeterminada | Grande | No | No | No | Sí |
Para comenzar a extraer texto de varias fuentes, haz clic en el botón de Extracción de pantalla, en el grupo Asistentes de la pestaña en la cinta Diseño.
El asistente de extracción de pantalla te permite señalar un elemento de la interfaz de usuario y extraer texto de él, utilizando uno de los tres métodos de salida descritos arriba. Studio escoge de forma automática un método de extracción de pantalla para ti y lo muestra en la parte superior de la ventana del Asistente de extracción de pantalla.
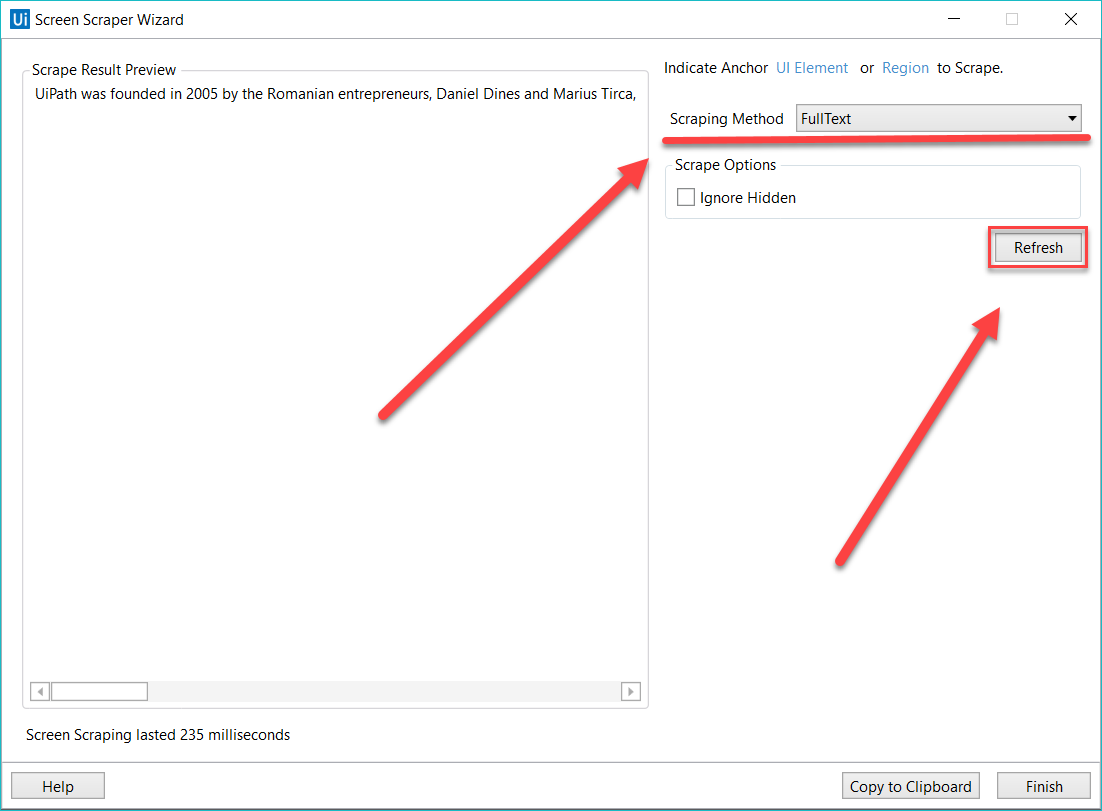
Para cambiar el método de extracción de pantalla, selecciona uno distinto del panel Opciones y luego haz clic en Actualizar.
Cuando estés satisfecho con los resultados de la extracción, haz clic en Copiar al portapapeles y luego en Finalizar. La última opción copia el texto extraído en el Portapapeles, y puede añadirse a una actividad Generar tabla de datos en el panel Diseñador . Al igual que la grabación de escritorio, la extracción de pantalla genera un contenedor (con el selector de la ventana de nivel superior) que contiene actividades y selectores parciales para cada actividad.
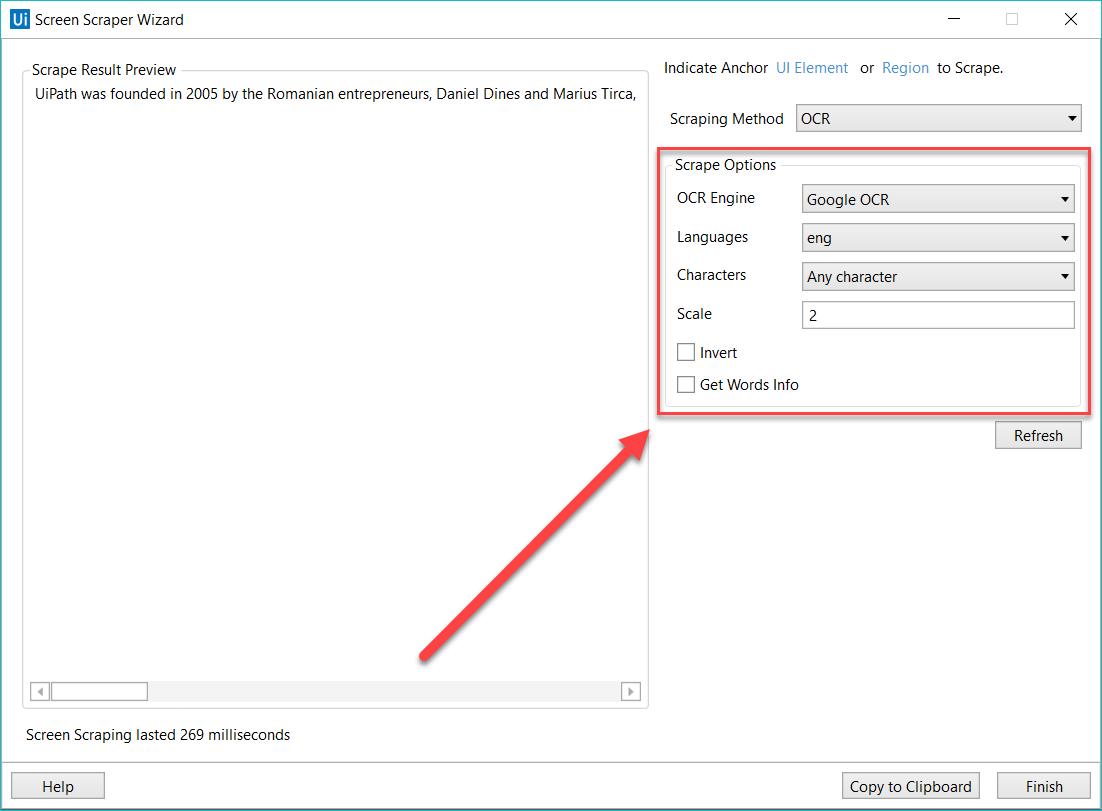
Cada tipo de extracción de pantalla aparece con diferentes características en el Asistente de extracción de pantalla del panel Opciones:
- Texto completo

- Ignorar ocultos - cuando se marca esta casilla no se copia el texto oculto del elemento seleccionado de la interfaz de usuario.
- Nativo

- Sin formato - cuando se marca esta casilla, el texto copiado no extrae información acerca del formato del texto. De lo contrario, se conservaría la posición relativa del texto extraído.
- Obtener información de las palabras - cuando se marca esta casilla, Studio también extrae las coordenadas de pantalla de cada palabra. Además, se mostrará el campo Separadores personalizados, que te permite especificar los caracteres utilizados como separadores. Si el campo se deja vacío, se utilizan todos los separadores de texto conocidos.
- Google OCR

- Idiomas - el inglés es el único disponible de forma predeterminada.
- Caracteres - te permite seleccionar qué tipo de caracteres deben extraerse. Están disponibles las siguientes opciones: Cualquier carácter, Solo números, Letras, Mayúsculas, Minúsculas, Números de teléfono, Moneda, Fecha y Personalizado. Si seleccionas Personalizado, se mostrarán dos campos adicionales, Permitidos y Denegados, que te permiten crear reglas personalizadas sobre el tipo de caracteres a extraer o evitar.
- Invertir - cuando se marca esta casilla, los colores del elemento de la interfaz de usuario se invierten antes de la extracción. Esto resulta útil cuando el fondo es más oscuro que el color del texto.
- Escala - el factor de escalado del elemento o imagen de la IU escogido. Cuanto mayor sea el número, más se ampliará la imagen. Esto puede facilitar una mejor lectura OCR y es lo recomendado para imágenes pequeñas.
- Obtener información sobre las palabras - obtiene la posición en pantalla de cada palabra extraída.
Nota:
En algunas instancias de Studio, el motor Google Tesseract puede tener archivos de entrenamiento (sobre archivos de entrenamiento: Wikipedia, GitHub) que no funcionan para ciertos idiomas distintos del inglés. Ejecutar un proyecto con estos archivos de entrenamiento dañados puede provocar que se lance una excepción. Para solucionar este problema, descarga el archivo de entrenamiento para el idioma que deseas utilizar desde aquí y cópialo en la carpeta tessdata del directorio de instalación de UiPath. Para comprobar si los archivos de entrenamiento que descargaste funcionan, puedes descargar este proyecto de prueba.
- UiPath Screen OCR
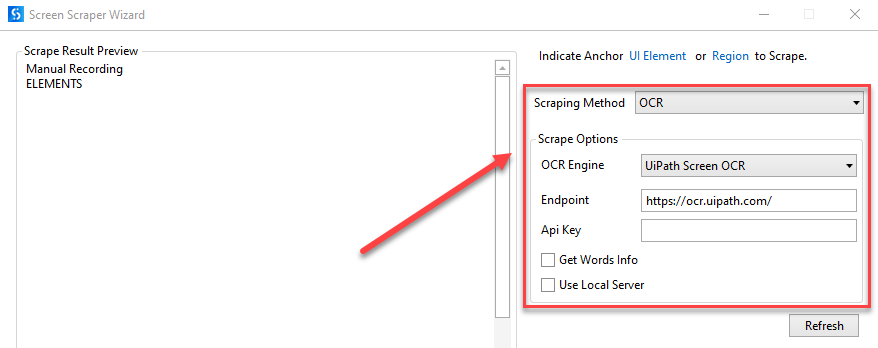
- PuntoFinal - el punto final donde se aloja el modelo OCR, ya sea de forma pública o a través de una habilidad ML en AI Center.
- Clave API - la clave API del punto final.
- Obtener información sobre las palabras - obtiene la posición en pantalla de cada palabra extraída.
- Usar el servidor local: selecciona esta opción si quieres ejecutar el OCR localmente (requiere Computer Vision Local Server Pack)
- Microsoft OCR
Importante:
El motor de extracción de Microsoft OCR no es compatible con flujos de trabajo .NET 5.

- Idiomas - te permite cambiar el idioma del texto extraído. El idioma seleccionado de forma predeterminada es el inglés.
- Escala - el factor de escalado del elemento o imagen de la IU escogido. Cuanto mayor sea el número, más se ampliará la imagen. Esto puede facilitar una mejor lectura OCR y es lo recomendado para imágenes pequeñas.
- Obtener información sobre las palabras - obtiene la posición en pantalla de cada palabra extraída.
Además de obtener el texto de los elementos de la interfaz de usuario indicados, también puedes extraer el valor de varios tipos de atributos, su posición exacta en pantalla y su antecesor.
Este tipo de información puede extraerse mediante actividades dedicadas localizadas en el panel Actividades, bajo Automatización de la interfaz de usuario > Elemento > Buscar y Automatización de la interfaz de usuario > Elemento > Atributo.
Dichas actividades son:
-
Obtener antecesor : te permite recuperar un antecesor de un elemento de la IU especificado. Puedes indicar en qué nivel de la jerarquía de la IU se encuentra el antecesor y almacenar los resultados en una variable ElementoDeIU.
-
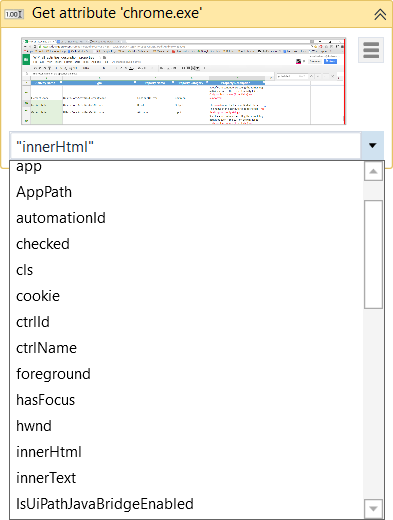
Obtener atributo : recupera el valor de un atributo de elemento de la IU especificado. Una vez que indiques el elemento de la IU en la pantalla, se mostrará una lista desplegable con todos los atributos disponibles.
-
Obtener posición : recupera el rectángulo delimitador del ElementoDeIU especificado y solo admite variables Rectángulo.
UiPath Studio también cuenta con Extracción relativa, un método de extracción que identifica la ubicación del texto a recuperar en relación con un anclaje. Para obtener más información, consulta Extracción relativa.
También puedes generar tablas a partir de datos no estructurados y almacenar la información en variables de TablaDeDatos, utilizando el Asistente de extracción de pantalla. Para obtener más información, consulta Generar tablas a partir de datos no estructurados.