- Vue d'ensemble (Overview)
- Automatisation de l'interface utilisateur
- À propos du package d'activités UIAutomation
- Applications et technologies automatisées avec UI Automation
- Compatibilité du projet
- UI-ANA-016 - Extraire l'URL ouverte du navigateur
- UI-ANA-017 - ContinuerSurErreur (ContinueOnError) True
- UI-ANA-018 - Répertorier les activités d'OCR/d'image
- UI-DBP-006 - Utilisation du conteneur
- UI-DBP-013 - Utilisation abusive de l’automatisation Excel
- UI-DBP-030 - Utilisation de variables interdites dans les sélecteurs
- UI-DBP-031 : Vérification de l’activité
- UI-PRR-001 - Simuler un clic
- UI-PRR-002 - Type de simulation
- UI-PRR-003 - Ouverture d'une utilisation abusive de l'application
- UI-PRR-004 - Délais codés en dur
- UI-REL-001 - Idx volumineux dans les sélecteurs
- UI-SEC-004 - Données d’e-mail du sélecteur
- UI-SEC-010 - Restrictions d'applications/d'URL
- UI-USG-011 - Attributs non autorisés
- UX-SEC-010 - Restrictions d'applications/d'URL
- UX-DBP-029 - Utilisation d'un mot de passe non sécurisé
- UI-PST-001 - Niveau du journal d'audit dans les paramètres du projet
- Outil de migration de navigateur UiPath
- Zone de détourage
- Enregistreur de Computer Vision
- À propos des éléments d'interface utilisateur
- Propriétés des activités de l'interface utilisateur
- Exemple d'utilisation des méthodes de saisie
- Méthodes de sortie ou de capture de données d'écran
- Exemple d'utilisation de méthodes de sortie ou de capture de données d'écran
- Génération de tables à partir de données non structurées
- Capture relative de données
- À propos de l'automatisation des images et des textes
- Activités liées à la souris et au clavier
- Exemple d'utilisation de l'automatisation de la souris et du clavier
- Les activités de type texte
- Exemple d'utilisation d'automatisation de texte
- Activités de type OCR
- Activités de type image
- Exemple d'utilisation de l'automatisation d'image et d'OCR
- Index des activités
- Activer (Activate)
- Base d'ancrage (Anchor Base)
- Lier à un navigateur (Attach Browser)
- Lier à une fenêtre (Attach Window)
- Block User Input
- Légende (Callout)
- Vérifier (Check)
- Cliquer (Click)
- Cliquer sur l'image (Click Image)
- Déclencheur de clic image (Click Image Trigger)
- Cliquer sur le texte OCR (Click OCR Text)
- Cliquer sur le texte (Click Text)
- Déclencheur de clic (Click Trigger)
- Fermer l'application (Close Application)
- Fermer l'onglet (Close Tab)
- Fermer la fenêtre (Close Window)
- Context Aware Anchor
- Copier le texte sélectionné (Copy Selected Text)
- Element Attribute Change Trigger
- Élément existant (Element Exists)
- Étendue de l'élément (Element Scope)
- Element State Change Trigger
- Export UI Tree
- Extraire les données structurées (Extract Structured Data)
- Rechercher les enfants (Find Children)
- Rechercher l'élément (Find Element)
- Rechercher l'image (Find Image)
- Rechercher les correspondances de l'image (Find Image Matches)
- Rechercher une position de texte OCR (Find OCR Text Position)
- Rechercher l'élément relatif (Find Relative Element)
- Rechercher la position du texte (Find Text Position)
- Obtenir la fenêtre active (Get Active Window)
- Obtenir l'ancêtre (Get Ancestor)
- Obtenir l'attribut (Get Attribute)
- Obtenir les infos de l'événement (Get Event Info)
- Récupérer du presse-papiers (Get From Clipboard)
- Obtenir le texte complet (Get Full Text)
- Obtenir le texte OCR (Get OCR Text)
- Récupérer le mot de passe (Get Password)
- Obtenir la position (Get Position)
- Obtenir l'élément source (Get Source Element)
- Obtenir le texte (Get Text)
- Obtenir le texte visible (Get Visible Text)
- Revenir en arrière (Go Back)
- Avancer (Go Forward)
- Accéder à l'accueil (Go Home)
- Google Cloud Vision OCR
- Masquer la fenêtre (Hide Window)
- Mettre en surbrillance (Highlight)
- Déclencheur de raccourci (Hotkey Trigger)
- Pointer (Hover)
- Pointer sur l'image (Hover Image)
- Pointer sur le texte OCR (Hover OCR Text)
- Pointer sur le texte (Hover Text)
- Image existante (Image Exists)
- Indiquer sur l'écran (Indicate On Screen)
- Injecter du code .NET
- Inject Js Script
- Invoquer la méthode ActiveX
- Déclencheur de pression de touche (Key Press Trigger)
- Charger l'image (Load Image)
- Agrandir la fenêtre (Maximize Window)
- Microsoft Azure ComputerVision OCR
- Reconnaissance optique des caractères Microsoft (Microsoft OCR)
- Microsoft Project Oxford Online OCR
- Réduire la fenêtre (Minimize Window)
- Surveiller les événements (Monitor Events)
- Déclencheur de souris (Mouse Trigger)
- Déplacer la fenêtre (Move Window)
- Accéder à (Navigate To)
- Texte OCR existant (OCR Text Exists)
- Sur affichage de l'élément (On Element Appear)
- Sur disparition de l'élément (On Element Vanish)
- Sur apparition de l'image (On Image Appear)
- Sur disparition de l'image (On Image Vanish)
- Ouvrir l'application (Open Application)
- Ouvrir le navigateur (Open Browser)
- Actualiser le navigateur (Refresh Browser)
- Relire l'événement utilisateur (Replay User Event)
- Restaurer la fenêtre (Restore Window)
- Enregistrer l'image (Save Image)
- Sélectionner l'élément (Select Item)
- Sélectionner plusieurs éléments (Select Multiple Items)
- Envoyer le raccourci (Send Hotkey)
- Définir la zone de détourage (Set Clipping Region)
- Définir le focus (Set Focus)
- Définir le texte (Set Text)
- Placer dans le presse-papiers (Set To Clipboard)
- Définir l'attribut Web (Set Web Attribute)
- Afficher la fenêtre (Show Window)
- Déclencher le processus (Start Process)
- Déclencheur système (System Trigger)
- Prendre une capture d'écran (Take Screenshot)
- Tesseract OCR
- Texte existant (Text Exists)
- Info-bulle
- Saisir dans (Type Into)
- Saisir un texte sécurisé (Type Secure Text)
- Utiliser le premier plan
- Attendre un attribut (Wait Attribute)
- Attendre que l'élément disparaisse (Wait Element Vanish)
- Attendre que l'image disparaisse (Wait Image Vanish)
- Vérification de l’accessibilité
- Application event trigger
- Block User Input
- Check/Uncheck
- Check App State
- Check Element
- Cliquer (Click)
- Click Event Trigger
- Glisser et déposer
- Extract Table Data
- Find Elements
- For Each UiElement
- Get Browser Data
- Get Clipboard (Obtenir le Presse-papiers)
- Obtenir le texte (Get Text)
- Get URL
- Go To URL
- Mettre en surbrillance (Highlight)
- Pointer (Hover)
- Inject Js Script
- Raccourcis clavier
- Keypress Event Trigger
- Mouse scroll
- Navigate Browser
- Enregistrer l'image (Save Image)
- Sélectionner l'élément (Select Item)
- Set Browser Data
- Set Clipboard (Définir le Presse-papiers)
- Définir le navigateur du runtime (Set Runtime Browser)
- Définir le focus (Set Focus)
- Définir le texte (Set Text)
- Prendre une capture d'écran (Take Screenshot)
- Saisir dans (Type Into)
- Unblock User Input
- Use Application/Browser
- Window operation
- Joindre
- Vérifier (Check)
- Cliquer (Click)
- Glisser et déposer
- Extraire des données
- Obtenir l'attribut (Get Attribute)
- ObtenirEnfants
- ObtenirCibleRuntime
- GetText
- Get URL
- GoToUrl
- Mettre en surbrillance (Highlight)
- Pointer (Hover)
- IsEnabled
- Raccourci clavier
- Mouse scroll
- Ouvrir
- Sélectionner l'élément (Select Item)
- Prendre une capture d'écran (Take Screenshot)
- Saisir dans (Type Into)
- ÉtatAttente
- Effectuez une recherche par navigateur et récupérez les résultats à l'aide des API UI Automation
- Navigation sur le Web
- Rechercher des images
- Cliquer sur des images
- Déclencher et surveiller des événements
- Créer et remplacer des fichiers
- Pages HTML : extraire et manipuler des informations
- Manipulation des fenêtres
- Sélection de liste automatisée
- Rechercher et manipuler des éléments de fenêtre
- Gérer l'automatisation du texte
- Charger et traiter des images
- Gérer les actions activées par la souris
- Automatiser l'exécution des applications
- Exécution automatisée d'une application locale
- Navigation avec le navigateur
- Automatisation Web
- Exemple de fonctionnalités du déclencheur
- Activer la prise en charge d’UI Automation dans DevExpress
- Computer Vision Local Server
- Automatisation mobile
- Notes de publication
- À propos de l'architecture d'automatisation des appareils mobiles
- Compatibilité du projet
- Get Log Types
- Get Logs
- Get Page Source
- Get Device Orientation
- Get Session Identifier
- Installer l'application
- Gérer l'application actuelle
- Gérer une autre application
- Ouvrir DeepLink
- Ouvrir l'URL
- Mobile Device Connection
- Balayer directionnel
- Dessiner un modèle
- Positional Swipe
- Press Hardware Button
- Set Device Orientation
- Prendre une capture d'écran (Take Screenshot)
- Prendre une partie de capture d'écran
- Élément existant (Element Exists)
- Execute Command
- Obtenir l'attribut (Get Attribute)
- Get Selected Item
- Obtenir le texte (Get Text)
- Set Selected Item
- Définir le texte (Set Text)
- Balayer
- Tap
- Saisir texte
- Premiers pas avec les API d’automatisation mobile
- Gestion des boîtes de dialogue contextuelles dans les automatisations mobiles
- Creating variables from selector attributes
- Créer des workflows d'automatisation mobile
- Utiliser l’automatisation mobile pour les applications de banque mobile
- Automatisation pour les applications React Native
- Terminal
- Notes de publication
- À propos du package d'activités Terminal
- Compatibilité du projet
- Meilleures pratiques
- Rechercher un texte (Find Text)
- Get Color At Position
- Obtenir la position du curseur (Get Cursor Position)
- Obtenir le champ (Get Field)
- Obtenir le champ en position (Get Field at Position)
- Accéder à la zone d'écran (Get Screen Area)
- Obtenir le texte (Get Text)
- Obtenir le texte en position (Get Text at Position)
- Déplacer le curseur (Move Cursor)
- Move Cursor to Text
- Envoyer la touche Contrôle (Send Control Key)
- Envoyer les touches (Send Keys)
- Envoyer les touches en toute sécurité (Send Keys Secure)
- Définir le champ (Set Field)
- Définir le champ en position (Set Field at Position)
- Session de terminal (Terminal Session)
- Attendre le texte de champ (Wait Field Text)
- Wait Screen Ready
- Attendre le texte d'écran (Wait Screen Text)
- Attendre le texte en position (Wait Text at Position)
- API d'automatisation codée par terminal
Activités UIAutomation
Les méthodes de sortie ou de capture de données d'écran sont des activités qui permettent d'extraire des données, que ce soit à partir d'un élément d'une interface utilisateur ou à partir d'un document (comme par exemple un fichier .pdf).
Pour determiner quelle méthode employer pour l'automatisation de votre processus métier, examinons leurs caractéristiques respectives :
| Méthode de capacité | Vitesse | Précision | Exécution en arrière-plan | Capable d'extraire la position du texte | Capable d'extraire un texte caché | Prise en charge de Citrix |
|---|---|---|---|---|---|---|
| FullText | 10/10 | 100 % | oui | non | oui | non |
| Native | 8/10 | 100 % | non | oui | non | non |
| OCR | 3/10 | 98 % | non | oui | non | oui |
Texte complet (FullText) est la méthode par défaut : elle est rapide et précise, mais contrairement à la méthode de type Native, elle ne peut pas extraire la position du texte à l'écran.
Ces deux méthodes ne fonctionnent que dans le cadre d'applications de bureau. De plus, la méthode Native ne fonctionne qu'avec les applications conçues pour le rendu de texte avec l'interface GDI (Graphics Device Interface).
La méthode OCR (pour la reconnaissance optique de caractères) n'est pas toujours fiable à 100 %, mais elle peut être utile car elle fonctionne avec toutes les applications (et notamment Citrix). Studio utilise deux moteurs OCR par défaut : Google Tesseract et Microsoft Modi.
Vous pouvez modifier les langues pour les moteurs OCR et vous pouvez en savoir plus sur l' Installation des langues pour OCR.
| Méthode de capacité | Prise en charge de plusieurs langues | Superficie préférée | Prise en charge de l'inversion des couleurs | Définition d'un format de texte attendu | Filtrage des caractères autorisés | Résultat optimal avec les polices de Microsoft |
|---|---|---|---|---|---|---|
| Google Tesseract | Peut être ajouté | Petite | oui | oui | oui | non |
| Microsoft MODI | Par défaut | Grande | non | non | non | oui |
Pour commencer à extraire du texte à partir de diverses sources, cliquez sur le bouton Capture de données d'écran (Screen Scraping) à partir du groupe des Assistants (Wizards) de l'onglet Design.
L'assistant pour la capture de données d'écran permet de pointer la souris sur un élément de l'interface utilisateur et d'extraire le texte contenu dans celui-ci, grâce à une des trois méthodes de sortie décrites plus haut. Studio sélectionne automatiquement une méthode de capture et l'affiche en haut de la fenêtre Assistant pour la capture des données d'écran (Screen Scraper Wizard).
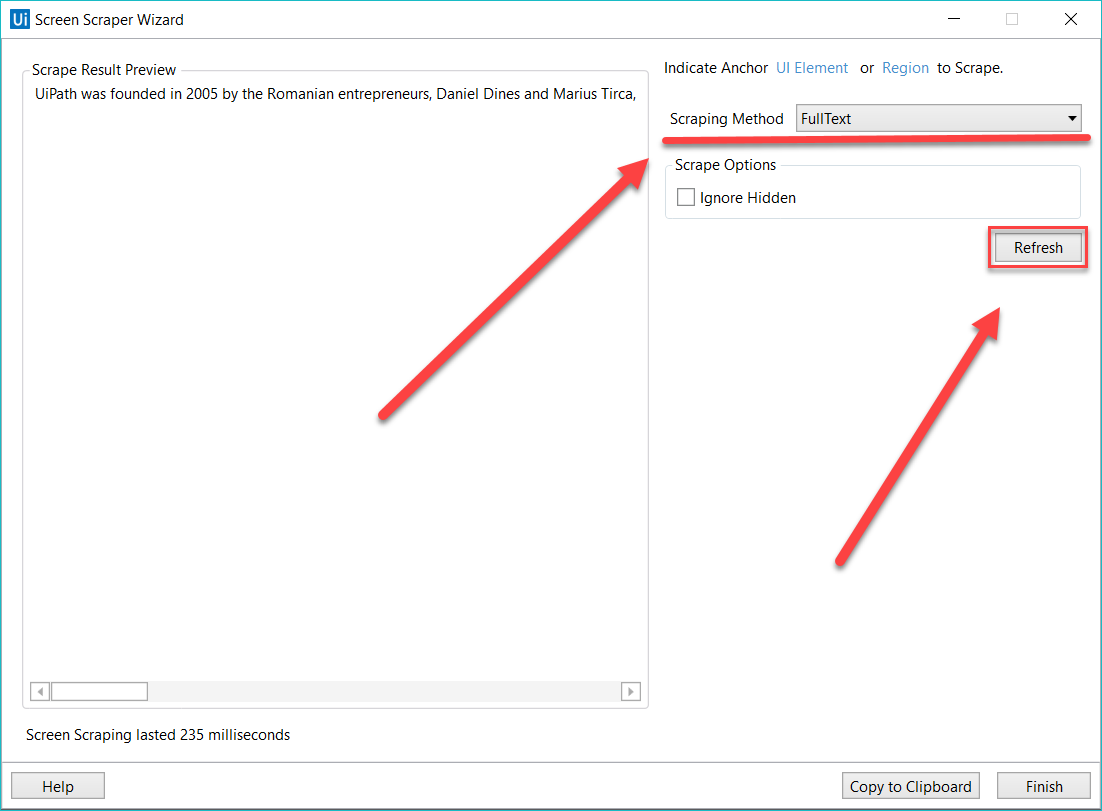
Pour modifier la méthode de capture, sélectionnez la méthode de votre choix dans le module Options (Options), puis cliquez sur Actualiser (Refresh).
Lorsque vous êtes satisfait des résultats de l'extraction, cliquez sur Copier dans le Presse-papiers et sur Terminer. La dernière option copie le texte extrait dans le Presse-papiers. Il peut être ajouté à une activité Generate Data Table dans le panneau Concepteur . Tout comme l’ enregistrement de poste de travail, l’extraction de données d’écran génère un conteneur qui contient des activités, ainsi que des sélecteurs partiels pour chaque activité.
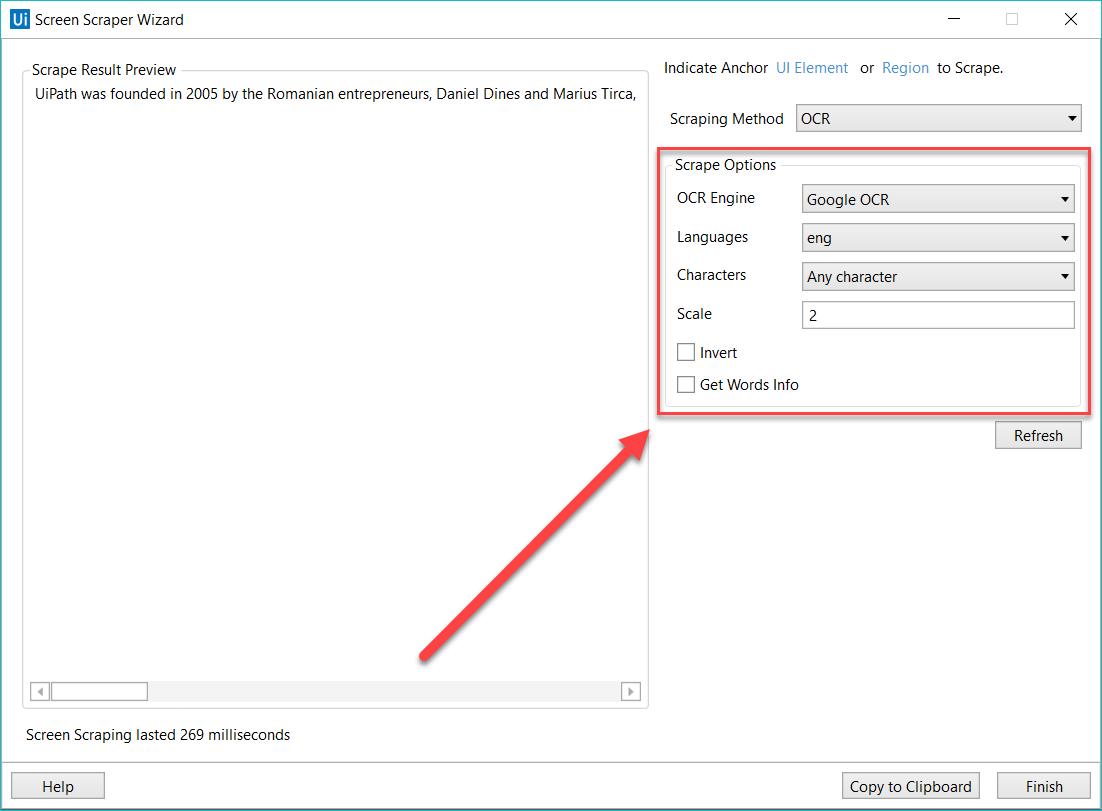
Il est possible d'explorer les différentes fonctionnalités liées aux type de capture de données d'écran à partir de la fenêtre Assistant pour la capture des données d'écran (Screen Scraper Wizard), dans le module Options (Options) :
- FullText

- Ignorer les éléments masqués (Ignore Hidden) : les textes masqués présents dans l'élément d'interface utilisateur sélectionné ne sont pas copiés si cette case est cochée.
- Native

- Aucun formatage (No Formatting) : lorsque cette case est cochée, le texte est copié mais le formatage du texte n'est pas conservé. En cas contraire, la position relative du texte extrait est conservée.
- Obtenir les infos de mots (Get Words Info) : lorsque cette case est cochée, Studio extrait également les coordonnées d'écran de chaque mot. En outre, le champ Personnaliser les séparateurs (Custom Separators) permet de spécifier les caractères utilisés comme séparateurs. Si le champ est vide, tous les séparateurs de textes connus sont utilisés.
- Reconnaissance optique des caractères Google (Google OCR)

- Langues (Languages) : l'anglais est la seule langue disponible par défaut.
- Caractères (Characters) permet de sélectionner les types de caractères à extraire, parmi les options suivantes : Tous les caractères (Any character), Nombres uniquement (Numbers only), Lettres (Letters), Majuscules (Uppercase), Minuscules (Lowercase), Numéros de téléphone(Phone numbers), Devises (Currency), Date et Sur mesure(Custom). Si vous sélectionnez l'option sur mesure (Custom), deux champs supplémentaires apparaissent : Autoriser (Autorisé) et Refusé (Denied) pour vous permettre d'autoriser ou d'interdire la capture de caractères particuliers et de créer ainsi vos propres règles.
- Inverser (Invert): lorsque cette case est cochée, les couleurs de l'élément d'interface utilisateur sont inversées avant la capture des données, ce qui est utile lorsque l'arrière-plan est plus sombre que le texte.
- Échelle (Scale): il s'agit du facteur de mise à l'échelle de l'image ou de l'élément sélectionné dans l'interface utilisateur. Plus ce facteur est élevé, plus l'image est élargie. Cette option est recommandée pour les petites images et pour favoriser la détection OCR.
- Get Words Info : permet d'obtenir la position de chaque mot capturé sur un écran donné.
Remarque :
Dans certains cas d'UiPath Studio, le moteur Google Tesseract peut contenir des fichiers d'entraînement : Wikipedia, GitHub) qui ne fonctionnent pas pour certaines langues autres que l'anglais. L'exécution d'un projet avec ces fichiers d'entraînement corrompus peut entraîner la levée d'une exception. Pour résoudre ce problème, téléchargez le fichier d'entraînement pour la langue que vous souhaitez utiliser à partir d' ici et copiez-le dans le dossier tessdata du répertoire d'installation UiPath. Pour vérifier si les fichiers d'entraînement que vous avez téléchargés fonctionnent, vous pouvez télécharger ce projet de test.
- UiPath Screen OCR
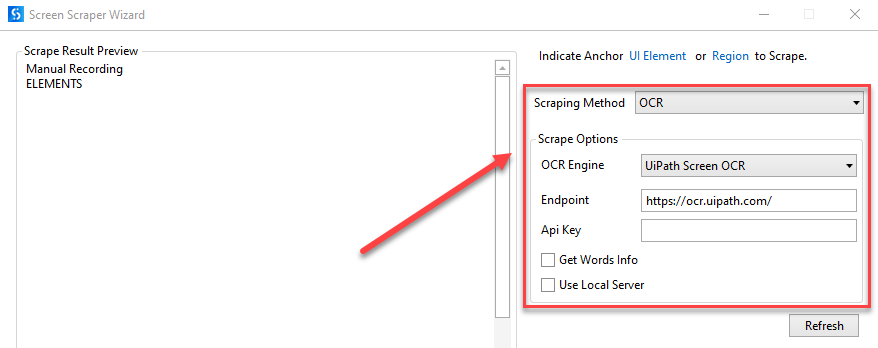
- Point de terminaison – le point de terminaison où le modèle OCR est hébergé, soit publiquement, soit via une compétence ML dans AI Center.
- Clé API – la clé API du point de terminaison.
- Get Words Info : permet d'obtenir la position de chaque mot capturé sur un écran donné.
- Utiliser le serveur local (Utiliser le serveur local) - sélectionnez cette option si vous souhaitez exécuter l'OCR localement (nécessite le pack de serveur local Computer Vision)
- Reconnaissance optique des caractères Microsoft (Microsoft OCR)
Important :
Le moteur d'extraction Microsoft OCR ne prend pas en charge les workflows .NET 5.

- Langues : permet de changer la langue du texte capturé. La langue sélectionnée par défaut est l'anglais.
- Échelle (Scale): il s'agit du facteur de mise à l'échelle de l'image ou de l'élément sélectionné dans l'interface utilisateur. Plus ce facteur est élevé, plus l'image est élargie. Cette option est recommandée pour les petites images et pour favoriser la détection OCR.
- Extraire informations des mots (Get Words Info) : permet d'obtenir la position de chaque mot capturé sur un écran donné.
Nous avons vu qu'il est possible d'extraire un texte à partir d'un élément donné dans une interface utilisateur. Il est de surcroît possible d'extraire les valeurs de plusieurs types d'attributs liés à cet élément, la position exacte de l'élément à l'écran, ou encore son ancêtre.
Ces données peuvent être extraites grâce à des activités spécifiques, accessibles à partir des options UI Automation > Element > Trouver (Find) et UI Automation > Element > Attribut (Attribute) dans le module Activités (Activities).
Voici la liste des activités proposées :
-
Obtenir l'ancêtre (Get Ancestor): cette activité permet de récupérer un ancêtre à partir d'un élément donné dans une interface utilisateur. Vous pouvez indiquer à quel niveau lancer la recherche dans la hiérarchie de l'interface utilisateur, puis stocker les résultats de la recherche dans une variable de type UiElement.
-
Obtenir l'attribut (Get Attribute) permet de récupérer la valeur d'un attribut pour un élément donné d'une interface utilisateur. Une fois que l'élément de l'interface utilisateur est indiqué à l'écran, une liste déroulante contenant tous les attributs disponibles s'affiche.
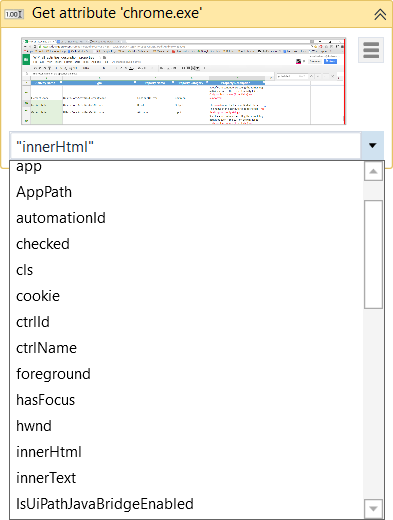
-
Extraire Position (Get Position): cette activité permet de récupérer le rectangle englobant pour l'UiElement spécifié et prend uniquement en charge les variables Rectangle.
Studio UiPath propose également une option de capture relative de données d'écran : il s'agit d'une méthode de capture qui identifie l'emplacement du texte à extraire par rapport à un point d’ancrage. Pour en savoir plus, consultez la section Capture relative de données.
Grâce à l'assistant pour la capture de données d'écran (Screen Scraping Wizard), il est également possible de générer des tables avec des données non structurées et de stocker les données dans des variables de type Table des données (DataTable). Pour plus d'informations, veuillez consulter la rubrique Génération de tables à partir de données non structurées.