- はじめる前に
- スタート アップ ガイド
- Integrations
- プロセス アプリを使用する
- アプリを作成する
- データを読み込む
- プロセス アプリをカスタマイズする
- ダッシュボードをパブリッシュする
- アプリ テンプレート
- その他のリソース
- すぐに使えるタグと期限日
- ローカル環境でデータ変換を編集する
- ローカルのテスト環境を設定する
- イベント ログをデザインする
- SAP Ariba の抽出ツールを拡張する
- パフォーマンス特性
Process Mining ポータルでは、新しいアプリを簡単に作成できます。[ 新しいアプリを作成 ] ボタンを選択するとウィザードが開き、ステップバイステップの手順に従って新しいアプリを作成できます。[新しいアプリを作成] ウィザードのどの手順で作業を中断しても、現在のステートが保存されます。このため、以前にウィザードを終了した際のステートでアプリの作成を継続できます。
新しいアプリを作成する
- Process Mining ポータルで [開発] タブに移動し、[新しいアプリを作成] を選択します。
注:
初めてのアプリの場合は、[Process Mining へようこそ] ページで [ 新しいアプリを作成 ] を選択できます。 [ 開発 ] タブにリダイレクトされます。
ウィザードが起動し、[アプリ テンプレートを選択] ステップが表示されます。このステップでは、アプリに使用するアプリ テンプレートを選択できます。
アプリ テンプレートを選択する
既存のアプリ テンプレートを、新しいアプリのベースとして使用することもできます。
利用可能なアプリ テンプレートの概要については、「アプリ テンプレート」をご覧ください。
- 新しいアプリのベースとして使用するアプリケーション テンプレートを示すタイルの [アプリを作成] ボタンを選択します。
[基本的な情報] ステップに、選択したプロセス アプリの既定の情報が表示されます。
アプリのプロパティを定義する
-
[アプリ名] フィールドで名前を編集して、新しいプロセス アプリの一意の名前を定義します。
注:入力した名前と同じ名前のアプリがテナントに既に存在する場合、メッセージが表示され、[保存して次へ] ボタンが無効化されます。
-
必要に応じて、[説明] フィールドの説明を編集します。
-
[保存して次へ] を選択します。
注:入力した名前と同じ名前のアプリが既に存在するにもかかわらず、[すべてのプロセス アプリ] リストにその名前が表示されない場合があります。この場合、そのアプリの表示権限を持っていない可能性があります。
以下の画像でご確認ください。
[データ ソース] ステップが表示されます。
データ ソースを選択する
サンプル データセットを使用したり、.csv ファイルを使用してデータセットをアップロードしたり、抽出器を使用してデータを読み込んだりできます。データは新しいプロセス アプリを作成した後に取り込まれます。
パフォーマンス上およびセキュリティ上の理由から、アプリの開発やデータ変換のテストには小規模なデータセットを使用することを強くお勧めします。 開発データセットは、データ変換のテストに使用されます。パブリッシュ済みのプロセス アプリのダッシュボードに表示されるデータには影響しません。 ビジネス ユーザーがアプリを使用する準備が整ったら、アプリをパブリッシュして、パブリッシュ済みのプロセス アプリで使用する新しいデータを取り込むことができます。
- データ ソースに適用するオプションを選択します。
- [保存して次へ] を選択します。
サンプル データを使用
[サンプル データを使用] オプションが、プロセス アプリでサンプル データが利用可能な場合にのみ有効化されるようになりました。
データセットをアップロードする
.csv ファイルを使用してデータセットをアップロードすることもできます。
データが大量にある場合は、CData Sync や Theobald Xtract Universal (SAP の場合) を使用してデータをアップロードすることをお勧めします。
新しいプロセス アプリを作成する際は、新しいアプリの作成に使用するアプリ テンプレートで求められる形式のデータがあることを必ず確認してください。詳しくは、「アプリ テンプレート」をご覧ください。
テーブル名とフィールド名では大文字と小文字が区別されます。データセットのフィールド名 (列ヘッダー) が入力テーブルのフィールド名と一致しており、ファイル名がテーブル名と一致していることを必ず確認してください。
.csv ファイルにサフィックス _raw が付いていることを確認してください。
データ ファイルをアップロードするには以下の手順に従います。
- プロセス アプリのデータを含む 1 つまたは複数のファイルをドラッグ アンド ドロップするか、アイコン
 を選択してコンピューターからファイルを選択します。
を選択してコンピューターからファイルを選択します。 - データセットについて検出された詳細で、エンコード、区切り文字、引用符文字を確認します。必要に応じて、適切な設定を選択します。
抽出器を使用してデータをアップロード
アプリを作成するプロセスの後半の [抽出器を使用してデータをアップロード] ステップで、抽出器で使用する詳細情報をコピーできます。「アプリの作成を完了する」をご覧ください。
プロセス モデルを選択する
プロセス アプリに使用するプロセス モデルの種類を選択できます。
[プロセス モデルを検出] と [BPMN モデルをインポート] によって、排他的、並列、およびループの動きに対して詳細な意味を持つイベントが提供されることで、プロセスの精度が向上しますが、アプリのスケーラビリティに影響が出る可能性があります。その結果、Process Mining アプリでサポートされる実際のイベントの最大数に影響が及ぶ可能性があります。
- プロセス アプリのプロセス モデルの種類を選択します。
- [保存してレビュー] を選択します。
直接フォロー グラフ
直後に続く プロセス モデル (隣接関係グラフ) では、簡潔さと読みやすさに重点を置いており、イベント ログを明確かつ直接的に表示します。これらのプロセス モデルは直感的で理解しやすいため、アクティビティの基本的なフローを簡単に理解できます。プロセス内の複雑な動作 (並列処理など) の一部をキャプチャすることはできませんが、プロセス モデルの 直後に続く アクティビティは、プロセスを分析するための有用な開始点となります。
[ 直後に続く アクティビティ] の関係は、プロセス内でアクティビティが発生する順序を表します。これは、プロセスの実行中に実行されたアクティビティのレコードを含むイベント ログに基づいています。Process Mining の手法では、イベント ログを分析することによって、通常実行されるアクティビティを 1 つずつ特定できます。これら 2 つのアクティビティの間で、エッジは A➝B として定義されます。
たとえば、プロセス内のパス A→B と C→D を並行して実行できる場合、2 つのパスのアクティビティはイベント ログ内で複数の順序で発生する可能性があります。「直接フォロー グラフ」のアプローチでは、これらのイベントは並列で実行されるとは見なされず、結果のプロセス フローは、たとえば A➝C➝B➝D のようになります。
ただし、[プロセス モデルを検出] または BPMN プロセス モデルでは、並列構造が考慮されます。
プロセス モデルを検出
プロセス モデルを検出すると、プロセスの構造をより深く理解することができます。プロセス全体 (イベント ログ全体) を高度なプロセス マイニング手法で分析することで、並列に発生するアクティビティ、意思決定の一部であるアクティビティ、またはより複雑なループの一部であるアクティビティが自動的に検出されます。この関係は「プロセス セマンティクス」と呼ばれます。
次の表では、検出プロセス モデルで使用されるプロセス セマンティクスの種類について説明します。
| セマンティクス ノードの種類 | 説明 | 図示 |
|---|---|---|
| 並列ゲートウェイ (AND) | 並列に発生する 2 つ以上の分岐を表します。 | |
| 排他的選択ゲートウェイ (XOR) | 2 つ以上の分岐間の排他的な選択 (判断ポイント) を表します。 | |
| ループ ゲートウェイ | 1 つのループ本体パスと 1 つ以上のリワーク パスを持つ反復可能なサブプロセスを表します。 |
BPMN モデルをインポート
独自の BPMN 2.0 モデルをインポートし、プロセス アプリのプロセス モデルとして使用する場合は、[BPMN モデルをインポート] を選択します。
BPMN モデルを使用すると、高度なプロセス アルゴリズムによってイベント ログ データが BPMN モデル上にマッピングされ、BPMN モデルとデータがどのように関連しているかを分析できます。
-
インポートする BPMN 2.0 モデルを含む
.bpmnファイルをドラッグ アンド ドロップします。
ファイルが正常にインポートされると、[ 保存してレビュー ] ボタンが有効になります。2. [保存してレビュー ] を選択して、BPMN モデルのインポートを完了します。
プロセス アプリの作成後に別の BPMN モデルを使用する場合は、プロセス マネージャーで BPMN モデルをインポートできます。
BPMN モデルの要件
以下のセクションでは、BPMN 2.0 モデルを正常にインポートして Process Mining で使用するための要件について説明します。
BPMN モデルの一般的な要件
- BPMN は BPMN 2.0 標準に準拠している必要があります。
- BPMN には単一のプロセス定義が含まれている必要があります。
- BPMN には、サポートされている要素のみを含めることができます。
- BPMN 内のすべてのノードに ID が必要です。
- BPMN モデルに含めるノードは 999 個以下にする必要があります。
サポートされている BPMN 要素
以下の BPMN 要素がサポートされています。
- 開始イベント
- 終了イベント
- タスク
- 排他的選択ゲートウェイ
- 並列ゲートウェイ
- シーケンス フロー
タスクとフローの要件
| 要件 | 例 |
|---|---|
| 開始イベントを定義する必要があります。開始イベントは 1 つだけ存在できます。 | |
| 終了イベントを定義する必要があります。終了イベントは 1 つだけ存在できます。 | |
| 少なくとも 1 つのアクティビティ タスクを定義する必要があります。 | |
| BMPM モデルには、少なくとも 2 つのシーケンス・フローが定義されている必要があります。 | |
| タスクに一意のラベルを付ける必要があります。 | |
| すべてのシーケンス・フローにソースとターゲットが必要です。 | |
| 各タスクに 1 つの入力シーケンス フローと 1 つの出力シーケンス フローが必要です。 | |
| 開始イベントの出力エッジは 1 つだけです。 | |
| 終了イベントの入力エッジは 1 つだけです。 | |
| BPMN 内のすべてのノードとシーケンス フローが 1 つのモデル内で接続されています。 |
ゲートウェイの要件
BPMN のゲートウェイはペアを形成する必要があります。各ペアには開始ゲートウェイが 1 つあり、ここでプロセス フローを複数のプロセス フローに分割します。各ペアには終了ゲートウェイが 1 つあり、ここで分割されたプロセス フローを 1 つのフローに結合します。この構造をブロックと呼びます。ブロック内のフローに、他のブロックを入れ子にして含めることができます。ただし、ブロック内のフローに出入りするフローは、分割ゲートウェイと結合ゲートウェイを経由するものだけです。
次の図に、ゲートウェイのペアでブロックを形成する BPMN モデルの例を示します。ブロックは強調表示されています。
| 要件 | 例 |
|---|---|
| 各ゲートウェイは、分割ゲートウェイまたは結合ゲートウェイのいずれかです。 | |
| 分割ゲートウェイには、1 つの入力エッジと、少なくとも 2 つの出力エッジがあります。 | 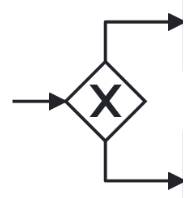 |
| 結合ゲートウェイには、少なくとも 2 つの入力エッジと 1 つの出力エッジがあります。 | 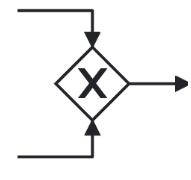 |
| すべての分割ゲートウェイには同じタイプの対応する結合ゲートウェイがあり、その逆も同様です。 | |
| 分割ゲートウェイと結合ゲートウェイのすべてのペアと、そのペア間の要素は、単一入口単一出口コンポーネント、つまり単一の入口エッジと単一の出口エッジのみを持つモデル コンポーネントです。 | |
| 分割ゲートウェイからそれに対応する結合ゲートウェイにつながる各パスも、単一入口単一出口である必要があります。 | |
| 対応する並列の分割ゲートウェイと結合ゲートウェイとの間に直接のシーケンス フローを存在させることはできません。 | |
| プロセスの前のポイントに戻るループ フローを記述した、排他的選択を行う分割 - 結合ゲートウェイのすべてのペアには、空のメイン パスと空のやり直しパスを設定することはできません。こうすると、タスクを実行することなく無限にループできるためです。 |
アプリの作成を完了する
プロセス アプリ
- アプリの詳細を確認します。
- [アプリを作成] を選択します。
プロセス アプリが作成され、[開発中のプロセス アプリ] のリストに表示されます。プロセス アプリのデータ取り込みの進行状況を示すバーが表示されます。
データの取り込みが完了すると、新しいアプリがパブリッシュされ [開発中のプロセス アプリ] リストに表示されます。
これで、必要に応じてアプリをカスタマイズしたり、変換を編集したりできます。詳しくは、「プロセス アプリをカスタマイズする」をご覧ください。
アプリは開発モードにあるため、開発環境でのみ使用できます。ビジネス ユーザーがアプリを利用できるようにするには、アプリをパブリッシュする必要があります。「ダッシュボードをパブリッシュする」をご覧ください。
抽出器を使用してデータをアップロード
「データ ソースを選択する」の手順で [抽出器を使用してデータをアップロード] オプションを選択した場合は、「抽出器を使用してデータをアップロード」の手順が表示されます。
end of upload API
抽出器を使用してデータを読み込む場合、抽出ジョブの post-event で end of upload API を使用して、抽出が完了したことを通知します。「ジョブを作成する」をご覧ください。
- end of upload API をコピーし、メモ帳ファイルなどに保存します。
- [完了] を選択します。