- Vue d'ensemble (Overview)
- Automatisation de l'interface utilisateur
- À propos du package d'activités UIAutomation
- Applications et technologies automatisées avec UI Automation
- Compatibilité du projet
- UI-ANA-016 - Extraire l'URL ouverte du navigateur
- UI-ANA-017 - ContinuerSurErreur (ContinueOnError) True
- UI-ANA-018 - Répertorier les activités d'OCR/d'image
- UI-DBP-006 - Utilisation du conteneur
- UI-DBP-013 - Utilisation abusive de l’automatisation Excel
- UI-DBP-030 - Utilisation de variables interdites dans les sélecteurs
- UI-DBP-031 : Vérification de l’activité
- UI-PRR-001 - Simuler un clic
- UI-PRR-002 - Type de simulation
- UI-PRR-003 - Ouverture d'une utilisation abusive de l'application
- UI-PRR-004 - Délais codés en dur
- UI-REL-001 - Idx volumineux dans les sélecteurs
- UI-SEC-004 - Données d’e-mail du sélecteur
- UI-SEC-010 - Restrictions d'applications/d'URL
- UI-USG-011 - Attributs non autorisés
- UX-SEC-010 - Restrictions d'applications/d'URL
- UX-DBP-029 - Utilisation d'un mot de passe non sécurisé
- UI-PST-001 - Niveau du journal d'audit dans les paramètres du projet
- Outil de migration de navigateur UiPath
- Zone de détourage
- Enregistreur de Computer Vision
- À propos des éléments d'interface utilisateur
- Propriétés des activités de l'interface utilisateur
- Exemple d'utilisation des méthodes de saisie
- Méthodes de sortie ou de capture de données d'écran
- Exemple d'utilisation de méthodes de sortie ou de capture de données d'écran
- Génération de tables à partir de données non structurées
- Capture relative de données
- À propos de la capture de données
- Exemple d'utilisation de capture de données
- À propos de l'automatisation des images et des textes
- Activités liées à la souris et au clavier
- Exemple d'utilisation de l'automatisation de la souris et du clavier
- Les activités de type texte
- Exemple d'utilisation d'automatisation de texte
- Activités de type OCR
- Activités de type image
- Exemple d'utilisation de l'automatisation d'image et d'OCR
- Index des activités
- Activer (Activate)
- Base d'ancrage (Anchor Base)
- Lier à un navigateur (Attach Browser)
- Lier à une fenêtre (Attach Window)
- Block User Input
- Légende (Callout)
- Vérifier (Check)
- Cliquer (Click)
- Cliquer sur l'image (Click Image)
- Déclencheur de clic image (Click Image Trigger)
- Cliquer sur le texte OCR (Click OCR Text)
- Cliquer sur le texte (Click Text)
- Déclencheur de clic (Click Trigger)
- Fermer l'application (Close Application)
- Fermer l'onglet (Close Tab)
- Fermer la fenêtre (Close Window)
- Context Aware Anchor
- Copier le texte sélectionné (Copy Selected Text)
- Element Attribute Change Trigger
- Élément existant (Element Exists)
- Étendue de l'élément (Element Scope)
- Element State Change Trigger
- Export UI Tree
- Extraire les données structurées (Extract Structured Data)
- Rechercher les enfants (Find Children)
- Rechercher l'élément (Find Element)
- Rechercher l'image (Find Image)
- Rechercher les correspondances de l'image (Find Image Matches)
- Rechercher une position de texte OCR (Find OCR Text Position)
- Rechercher l'élément relatif (Find Relative Element)
- Rechercher la position du texte (Find Text Position)
- Obtenir la fenêtre active (Get Active Window)
- Obtenir l'ancêtre (Get Ancestor)
- Obtenir l'attribut (Get Attribute)
- Obtenir les infos de l'événement (Get Event Info)
- Récupérer du presse-papiers (Get From Clipboard)
- Obtenir le texte complet (Get Full Text)
- Obtenir le texte OCR (Get OCR Text)
- Récupérer le mot de passe (Get Password)
- Obtenir la position (Get Position)
- Obtenir l'élément source (Get Source Element)
- Obtenir le texte (Get Text)
- Obtenir le texte visible (Get Visible Text)
- Revenir en arrière (Go Back)
- Avancer (Go Forward)
- Accéder à l'accueil (Go Home)
- Google Cloud Vision OCR
- Masquer la fenêtre (Hide Window)
- Mettre en surbrillance (Highlight)
- Déclencheur de raccourci (Hotkey Trigger)
- Pointer (Hover)
- Pointer sur l'image (Hover Image)
- Pointer sur le texte OCR (Hover OCR Text)
- Pointer sur le texte (Hover Text)
- Image existante (Image Exists)
- Indiquer sur l'écran (Indicate On Screen)
- Injecter du code .NET
- Inject Js Script
- Invoquer la méthode ActiveX
- Déclencheur de pression de touche (Key Press Trigger)
- Charger l'image (Load Image)
- Agrandir la fenêtre (Maximize Window)
- Microsoft Azure ComputerVision OCR
- Reconnaissance optique des caractères Microsoft (Microsoft OCR)
- Microsoft Project Oxford Online OCR
- Réduire la fenêtre (Minimize Window)
- Surveiller les événements (Monitor Events)
- Déclencheur de souris (Mouse Trigger)
- Déplacer la fenêtre (Move Window)
- Accéder à (Navigate To)
- Texte OCR existant (OCR Text Exists)
- Sur affichage de l'élément (On Element Appear)
- Sur disparition de l'élément (On Element Vanish)
- Sur apparition de l'image (On Image Appear)
- Sur disparition de l'image (On Image Vanish)
- Ouvrir l'application (Open Application)
- Ouvrir le navigateur (Open Browser)
- Actualiser le navigateur (Refresh Browser)
- Relire l'événement utilisateur (Replay User Event)
- Restaurer la fenêtre (Restore Window)
- Enregistrer l'image (Save Image)
- Sélectionner l'élément (Select Item)
- Sélectionner plusieurs éléments (Select Multiple Items)
- Envoyer le raccourci (Send Hotkey)
- Définir la zone de détourage (Set Clipping Region)
- Définir le focus (Set Focus)
- Définir le texte (Set Text)
- Placer dans le presse-papiers (Set To Clipboard)
- Définir l'attribut Web (Set Web Attribute)
- Afficher la fenêtre (Show Window)
- Déclencher le processus (Start Process)
- Déclencheur système (System Trigger)
- Prendre une capture d'écran (Take Screenshot)
- Tesseract OCR
- Texte existant (Text Exists)
- Info-bulle
- Saisir dans (Type Into)
- Saisir un texte sécurisé (Type Secure Text)
- Utiliser le premier plan
- Attendre un attribut (Wait Attribute)
- Attendre que l'élément disparaisse (Wait Element Vanish)
- Attendre que l'image disparaisse (Wait Image Vanish)
- Vérification de l’accessibilité
- Application event trigger
- Block User Input
- Check/Uncheck
- Check App State
- Check Element
- Cliquer (Click)
- Click Event Trigger
- Glisser et déposer
- Extract Table Data
- Find Elements
- For Each UiElement
- Get Browser Data
- Get Clipboard (Obtenir le Presse-papiers)
- Obtenir le texte (Get Text)
- Get URL
- Go To URL
- Mettre en surbrillance (Highlight)
- Pointer (Hover)
- Inject Js Script
- Raccourcis clavier
- Keypress Event Trigger
- Mouse scroll
- Navigate Browser
- Sélectionner l'élément (Select Item)
- Set Browser Data
- Set Clipboard (Définir le Presse-papiers)
- Définir le navigateur du runtime (Set Runtime Browser)
- Définir le focus (Set Focus)
- Définir le texte (Set Text)
- Prendre une capture d'écran (Take Screenshot)
- Saisir dans (Type Into)
- Unblock User Input
- Use Application/Browser
- Window operation
- Joindre
- Vérifier (Check)
- Cliquer (Click)
- Glisser et déposer
- Extraire des données
- Obtenir l'attribut (Get Attribute)
- ObtenirEnfants
- ObtenirCibleRuntime
- GetText
- Get URL
- GoToUrl
- Mettre en surbrillance (Highlight)
- Pointer (Hover)
- IsEnabled
- Raccourci clavier
- Mouse scroll
- Ouvrir
- Sélectionner l'élément (Select Item)
- Prendre une capture d'écran (Take Screenshot)
- Saisir dans (Type Into)
- ÉtatAttente
- Effectuez une recherche par navigateur et récupérez les résultats à l'aide des API UI Automation
- Navigation sur le Web
- Rechercher des images
- Cliquer sur des images
- Déclencher et surveiller des événements
- Créer et remplacer des fichiers
- Pages HTML : extraire et manipuler des informations
- Manipulation des fenêtres
- Sélection de liste automatisée
- Rechercher et manipuler des éléments de fenêtre
- Gérer l'automatisation du texte
- Charger et traiter des images
- Gérer les actions activées par la souris
- Automatiser l'exécution des applications
- Exécution automatisée d'une application locale
- Navigation avec le navigateur
- Automatisation Web
- Exemple de fonctionnalités du déclencheur
- Activer la prise en charge d’UI Automation dans DevExpress
- Computer Vision Local Server
- Automatisation mobile
- Notes de publication
- À propos de l'architecture d'automatisation des appareils mobiles
- Compatibilité du projet
- Get Log Types
- Get Logs
- Get Page Source
- Get Device Orientation
- Get Session Identifier
- Installer l'application
- Gérer l'application actuelle
- Gérer une autre application
- Ouvrir DeepLink
- Ouvrir l'URL
- Mobile Device Connection
- Balayer directionnel
- Dessiner un modèle
- Positional Swipe
- Press Hardware Button
- Set Device Orientation
- Prendre une capture d'écran (Take Screenshot)
- Prendre une partie de capture d'écran
- Élément existant (Element Exists)
- Execute Command
- Obtenir l'attribut (Get Attribute)
- Get Selected Item
- Obtenir le texte (Get Text)
- Set Selected Item
- Définir le texte (Set Text)
- Balayer
- Tap
- Saisir texte
- Premiers pas avec les API d’automatisation mobile
- Gestion des boîtes de dialogue contextuelles dans les automatisations mobiles
- Creating variables from selector attributes
- Créer des workflows d'automatisation mobile
- Utiliser l’automatisation mobile pour les applications de banque mobile
- Automatisation pour les applications React Native
- Terminal
- Notes de publication
- À propos du package d'activités Terminal
- Compatibilité du projet
- Meilleures pratiques
- Rechercher un texte (Find Text)
- Get Color At Position
- Obtenir la position du curseur (Get Cursor Position)
- Obtenir le champ (Get Field)
- Obtenir le champ en position (Get Field at Position)
- Accéder à la zone d'écran (Get Screen Area)
- Obtenir le texte (Get Text)
- Obtenir le texte en position (Get Text at Position)
- Déplacer le curseur (Move Cursor)
- Move Cursor to Text
- Envoyer la touche Contrôle (Send Control Key)
- Envoyer les touches (Send Keys)
- Envoyer les touches en toute sécurité (Send Keys Secure)
- Définir le champ (Set Field)
- Définir le champ en position (Set Field at Position)
- Session de terminal (Terminal Session)
- Attendre le texte de champ (Wait Field Text)
- Wait Screen Ready
- Attendre le texte d'écran (Wait Screen Text)
- Attendre le texte en position (Wait Text at Position)
- API d'automatisation codée par terminal

Activités UIAutomation
Exemple d'utilisation de capture de données
Pour mieux comprendre comment profiter de la fonctionnalité d'extraction des données, créons un projet d'automatisation qui extrait des informations spécifiques de Wikipedia et qui les écrit dans un tableur Excel. Vous pouvez utiliser ce type d'automatisation dans des scénarios différents, tels que l'extraction de listes de produits et de leurs prix des sites Web de commerce électronique.
Il est conseillé d'utiliser Internet Explorer (version 11 ou au-delà), Mozilla Firefox (version 50 ou au-delà), ou Google Chrome (la version la plus récente) pour exécuter vos projets d'automatisation Web.
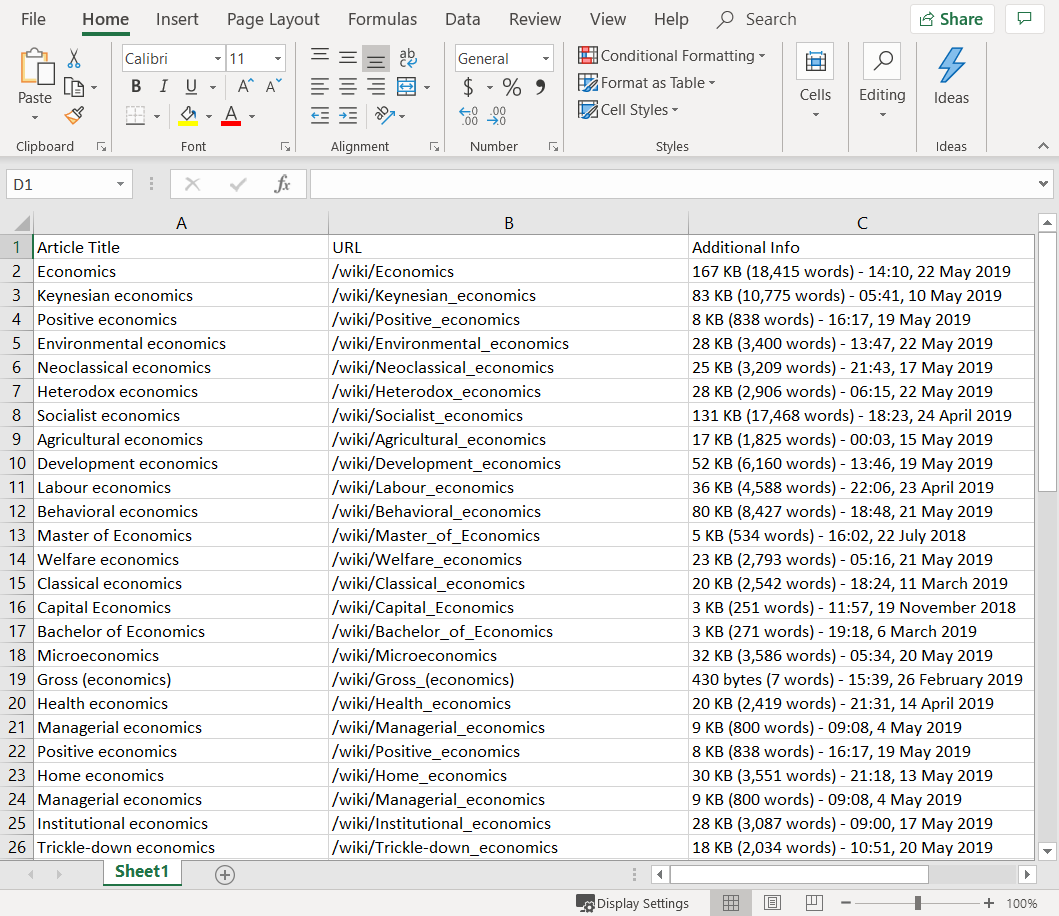
Disons que vous voulez commencer à étudier les sciences économiques et que vous voulez obtenir une liste d'articles Wikipedia sur le sujet, avec les URL et les informations supplémentaires fournies dans les résultats de la recherche pour chaque article. Vous pouvez procéder comme suit :
-
Ouvrez Internet Explorer et accédez à en.wikipedia.org.
-
Dans la case Rechercher dans Wikipedia (Search Wikipedia), entrez « sciences économiques », puis cliquez sur « contenant... sciences économiques » dans le menu déroulant qui s'affiche. Une page Web s'ouvre et affiche les résultats de la recherche.
-
Dans Studio, créez un processus d'automatisation.
-
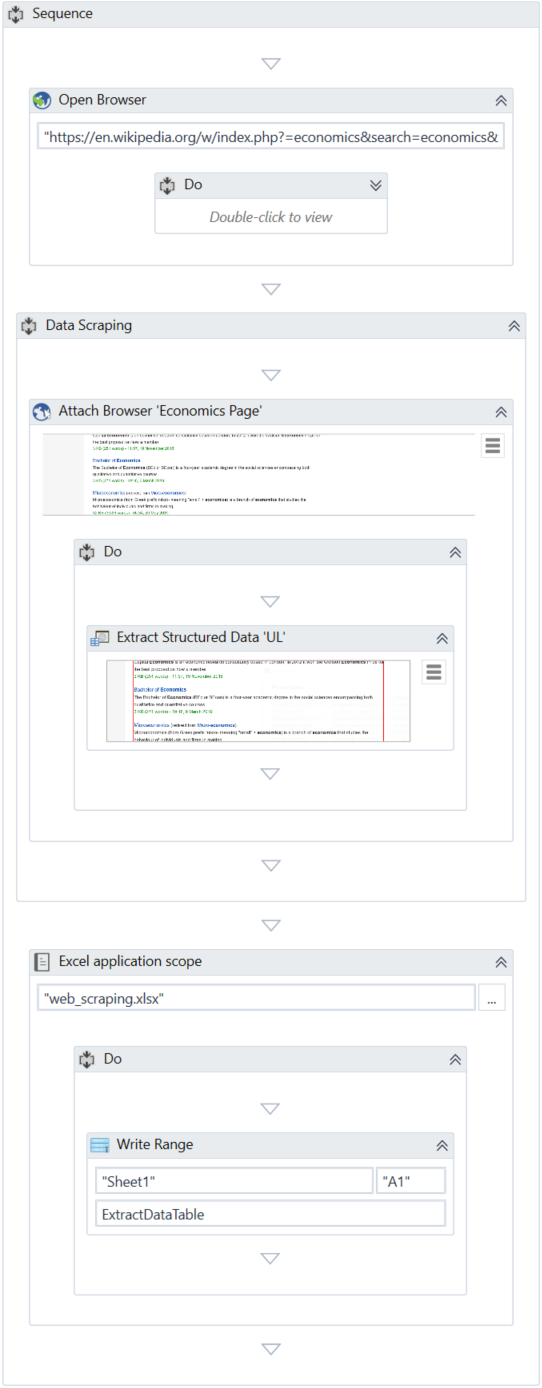
Dans le panneau Activités , ajoutez une activité Ouvrir le navigateur au panneau Designer et, dans le champ Url , collez l'URL de la page Web avec les résultats de la recherche. Dans notre exemple, l'URL est:
"https://en.wikipedia.org/w/index.php?search=economics%20&title=Special%3ASearch&fulltext=1&ns0=1". -
Dans l'onglet du ruban Conception (Design), groupe Assistants (Wizards), cliquez sur Extraction des données (Data Scraping). L'Assistant d'extraction (Extract Wizard) est affiché.
-
En suivant l'assistant, sélectionnez les premier et dernier éléments sur la page Web. L'étape de l'assistant Configurer les colonnes (Configure Columns) est affichée et les champs que vous avez sélectionnés sont mis en surbrillance dans le navigateur Web.
-
Cochez la case Extraire l'URL (Extract URL) et remplacez le nom des en-têtes de colonnes par un terme pertinent, par exemple « Titre de l'article » et « URL ».

-
Cliquez sur Suivant. Un aperçu des données est affiché dans l'étape de l'assistant Prévisualiser les données . Notez que du fait que la page Wikipedia utilise des URL relatives, la colonne URL contient également ces URL. Vous pouvez corriger cela dans la sortie Excel après l'exécution du projet en ajoutant la chaîne "https://en.wikipedia.org" au début de chaque cellule dans la colonne URL.

-
Cliquez sur le bouton Extraire les données corrélées (Extract Correlated Data) pour extraire des informations supplémentaires sur les articles. L'Assistant d'extraction (Extract Wizard) redémarre.
-
En suivant à nouveau l'assistant, indiquez les informations sur la taille et la date de la dernière modification disponible pour chaque article. Vous accédez à nouveau à l'étape Configurer les colonnes (Configure Columns).
-
Remplacez le nom du nouvel en-tête de colonne par « Informations supplémentaires » et cliquez sur Suivant (Next). Les données sont affichées dans l'étape de l'assistant Prévisualiser les données (Preview Data). Vous pouvez éventuellement modifier l'ordre des colonnes en les faisant glisser en place.
-
Dans Nombre maximum de résultats (Maximum number of results), entrez 60. La recherche Wikipedia répertorie 20 résultats par page et, pour notre exemple, nous voulons extraire les trois premières pages des résultats de la recherche.

- Cliquez sur Terminer (Finish). La fenêtre Indiquer le lien suivant (Indicate Next Link) est affichée et vous invite à indiquer le bouton ou la flèche Suivant (Next) sur lequel vous devez cliquer si les données couvrent plus d'une page.
- Cliquez sur Oui (Yes) et sélectionnez le bouton 20 suivants (next 20) au-dessous des résultats de la recherche dans Wikipedia. Le projet est mis à jour et une séquence Extraction des données (Data Scraping) est affichée dans le panneau Concepteur (Designer). Une variable DataTable,
ExtractDataTablea été générée automatiquement. - Dans le panneau Variables (Variables), remplacez l'étendue de la variable
ExtractDataTablegénérée automatiquement par Sequence. De cette façon, la variable est disponible en dehors de son étendue actuelle, la séquence Extraction des données (Data Scraping). - Ajoutez une activité Excel Application Scope sous la séquence Extraction des données .
- Dans le panneau Propriétés (Properties) de l'activité Excel Application Scope, dans le champ WorkbookPath, entrez
"web_scraping.xlsx". Lors de l'exécution du projet, un fichier ayant ce nom est créé dans le dossier de projet pour stocker les données à partir de l'extraction. Vous pouvez également spécifier un fichier qui existe déjà sur votre machine. - Dans la séquence Do de l'activité Excel Application Scope , ajoutez une activité Write Range et dans le panneau Propriétés :
- Dans le champ DataTable, ajoutez la variable
ExtractDataTable. - Cochez la case AddHeaders pour inclure les noms de colonnes dans la sortie.
- Appuyez sur F5 pour exécuter le projet.
- Ouvrez le fichier Excel que vous avez défini à l'étape 17. Remarque : toutes les colonnes sont correctement remplies.