- Überblick
- UI-Automatisierung (UI Automation)
- Über das UIAutomation-Aktivitätspaket
- Mit UI-Automatisierung automatisierte Anwendungen und Technologien
- Projektkompatibilität
- UI-ANA-016 – URL zum Öffnen eines Browsers abrufen
- UI-ANA-017 – ContinueOnError True
- UI-ANA-018 – OCR-/Bildaktivitäten auflisten
- UI-DBP-006 – Containernutzung
- UI-DBP-013 – Falscher Gebrauch von Excel-Automatisierung
- UI-DBP-030 – Verwendung unzulässiger Variablen in Selektoren
- UI-DBP-031 – Aktivitätsverifizierung
- UI-PRR-001 – Klick simulieren
- UI-PRR-002 – Typ simulieren
- UI-PRR-003 – Offener Anwendungsmissbrauch
- UI-PRR-004 – Hartcodierte Verzögerungen
- UI-REL-001 – Große IDX in Selektoren
- UI-SEC-004 – Selektor-E-Mail-Daten
- UI-SEC-010 – App-/URL-Einschränkungen
- UI-USG-011 – Nicht zulässige Attribute
- UX-SEC-010 – App-/URL-Einschränkungen
- UX-DBP-029 – Unsichere Kennwortnutzung
- UI-PST-001 – Prüfungsprotokollebene in Projekteinstellungen
- UiPath-Browsermigrationstool
- Clippingbereich
- Computer Vision Recorder
- Aktivitätenindex
- Aktivieren (Activate)
- Ankerbasis (Anchor Base)
- Browser anhängen (Attach Browser)
- Fenster anhängen (Attach Window)
- Benutzeingabe blockieren (Block User Input)
- Textfeld (Callout)
- Prüfen (Check)
- Klicken (Click)
- Bild anklicken (Click Image)
- Bild-Trigger anklicken (Click Image Trigger)
- OCR-Text anklicken (Click OCR Text)
- Text anklicken (Click Text)
- Trigger anklicken (Click Trigger)
- Anwendung schließen (Close Application)
- Registerkarte schließen (Close Tab)
- Fenster schließen (Close Window)
- Kontextbewusster Anker
- Ausgewählten Text kopieren (Copy Selected Text)
- Element Attribute Change Trigger
- Element vorhanden (Element Exists)
- Elementumfang (Element Scope)
- Element State Change Trigger
- Export UI Tree
- Strukturierte Daten extrahieren (Extract Structured Data)
- Untergeordnete Elemente finden (Find Children)
- Element finden (Find Element)
- Bild finden (Find Image)
- Bildübereinstimmung finden (Find Image Matches)
- OCR-Textposition finden (Find OCR Text Position)
- Relatives Element finden (Find Relative Element)
- Textposition finden (Find Text Position)
- Aktives Fenster abrufen (Get Active Window)
- Vorgänger-Element erhalten (Get Ancestor)
- Attribut erhalten (Get Attribute)
- Ereignisinfo erhalten (Get Event Info)
- Aus Zwischenablage erhalten (Get From Clipboard)
- Volltext erhalten (Get Full Text)
- OCR-Text erhalten (Get OCR Text)
- Passwort erhalten (Get Password)
- Position erhalten (Get Position)
- Quellelement erhalten (Get Source Element)
- Text erhalten (Get Text)
- Sichtbaren Text erhalten (Get Visible Text)
- Zurück (Go Back)
- Weiter (Go Forward)
- Zur Startseite (Go Home)
- Google Cloud Vision OCR
- Fenster ausblenden (Hide Window)
- Markieren (Highlight)
- Hotkey-Trigger (Hotkey Trigger)
- Darauf zeigen (Hover)
- Auf Bild zeigen (Hover Image)
- Auf OCR-Text zeigen (Hover OCR Text)
- Text beim Darauf zeigen (Hover Text)
- Bild vorhanden (Image Exists)
- Auf Bildschirm anzeigen (Indicate On Screen)
- .NET-Code einfügen
- Inject Js Script
- ActiveX-Methode aufrufen
- Tastendruck-Trigger (Key Press Trigger)
- Bild laden (Load Image)
- Fenster maximieren (Maximize Window)
- Microsoft Azure ComputerVision OCR
- Microsoft OCR
- Microsoft Project Oxford Online OCR
- Fenster minimieren (Minimize Window)
- Ereignisse überwachen (Monitor Events)
- Maus-Trigger (Mouse Trigger)
- Fenster verschieben (Move Window)
- Navigieren zu (Navigate To)
- OCR-Text vorhanden (OCR Text Exists)
- Auf Element erscheinen (On Element Appear)
- Auf Element verschwinden (On Element Vanish)
- Auf Bild erscheinen (On Image Appear)
- Auf Bild verschwinden (On Image Vanish)
- Anwendung öffnen (Open Application)
- Browser öffnen (Open Browser)
- Browser aktualisieren (Refresh Browser)
- Benutzerereignis wiedergeben (Replay User Event)
- Fenster wiederherstellen (Restore Window)
- Bild speichern (Save Image)
- Objekt auswählen (Select Item)
- Mehrere Objekte auswählen (Select Multiple Items)
- Hotkey senden (Send Hotkey)
- Ausschneidebereich einstellen (Set Clipping Region)
- Fokus legen auf (Set Focus)
- Text einstellen (Set Text)
- Auf Zwischenablage setzen (Set To Clipboard)
- Web-Attribut setzen (Set Web Attribute)
- Fenster anzeigen (Show Window)
- Prozess starten (Start Process)
- System-Trigger (System Trigger)
- Screenshot anfertigen (Take Screenshot)
- Tesseract OCR
- Text vorhanden (Text Exists)
- Tooltip
- Eingeben in (Type Into)
- Sicheren Text eingeben (Type Secure Text)
- Vordergrund verwenden
- Attribut abwarten (Wait Attribute)
- Warten, bis Element verschwindet (Wait Element Vanish)
- Warten, bis Bild verschwindet (Wait Image Vanish)
- Prüfung der Barrierefreiheit
- Application event trigger
- Benutzeingabe blockieren (Block User Input)
- Check/Uncheck
- Check App State
- Check Element
- Klicken (Click)
- Click Event Trigger
- Ziehen und Ablegen
- Extract Table Data
- Find Elements
- For Each UI Element
- Get Browser Data
- Clipboard abrufen
- Text erhalten (Get Text)
- Get URL
- Zu URL wechseln
- Markieren (Highlight)
- Darauf zeigen (Hover)
- Inject Js Script
- Tastenkombinationen
- Keypress Event Trigger
- Mouse Scroll
- Navigate Browser
- Bild speichern (Save Image)
- Objekt auswählen (Select Item)
- Set Browser Data
- Clipboard festlegen
- Set Runtime Browser
- Fokus legen auf (Set Focus)
- Text einstellen (Set Text)
- Screenshot anfertigen (Take Screenshot)
- Eingeben in (Type Into)
- Unblock User Input
- Use Application/Browser
- Window operation
- Anhängen
- Prüfen (Check)
- Klicken (Click)
- Ziehen und Ablegen
- Daten extrahieren
- Attribut erhalten (Get Attribute)
- GetChildren
- GetRuntimeTarget
- GetText
- Get URL
- GoToUrl
- Markieren (Highlight)
- Darauf zeigen (Hover)
- IsEnabled
- Tastaturkürzel (Keyboard Shortcut)
- Mouse Scroll
- Offen
- Objekt auswählen (Select Item)
- Screenshot anfertigen (Take Screenshot)
- Eingeben in (Type Into)
- Wartestatus
- Führen Sie eine Browsersuche durch und rufen Sie Ergebnisse mithilfe von UIAutomation-APIs ab
- Web-Browsing
- Finden von Bildern
- Klicken auf Bilder
- Auslösen und Überwachen von Ereignissen
- Erstellen und Überschreiben von Dateien
- HTML-Seiten: Extrahieren und Bearbeiten von Informationen
- Bearbeiten von Fenstern
- Automatisierte Listenauswahl
- Finden und Bearbeiten von Fensterelementen
- Verwalten der Textautomatisierung
- Laden und Verarbeiten von Bildern
- Verwalten von mausaktivierten Aktionen
- Automatisieren der Anwendungslaufzeit
- Automatisierte Ausführung einer lokalen Anwendung
- Browsernavigation
- Web-Automatisierung
- Beispiel für Trigger Scope
- Aktivieren der Unterstützung für die UI-Automatisierung in DevExpress
- Computer Vision Local Server
- Mobile Automation
- Versionshinweise
- Über die Architektur der Automatisierung von Mobilgeräten
- Projektkompatibilität
- Get Log Types
- Get Logs
- Get Page Source
- Get Device Orientation
- Get Session Identifier
- Install App
- Manage Current App
- Manage Other App
- DeepLink öffnen
- Open URL
- Mobile Device Connection
- Richtungswechsel
- Muster zeichnen
- Positional Swipe
- Press Hardware Button
- Set Device Orientation
- Screenshot anfertigen (Take Screenshot)
- Take Screenshot Part
- Element vorhanden (Element Exists)
- Execute Command
- Attribut erhalten (Get Attribute)
- Get Selected Item
- Text erhalten (Get Text)
- Set Selected Item
- Text einstellen (Set Text)
- Wischen
- Tap
- Type Text
- Terminal
- Versionshinweise
- Über das Terminal-Aktivitätspaket
- Projektkompatibilität
- Best Practices
- Find Text
- Get Color At Position
- Get Cursor Position
- Feld erhalten (Get Field)
- Feld an Position erhalten (Get Field at Position)
- Bildschirmbereich erhalten (Get Screen Area)
- Text erhalten (Get Text)
- Text an Position erhalten (Get Text at Position)
- Cursor bewegen (Move Cursor)
- Move Cursor to Text
- Strg-Taste senden (Send Control Key)
- Tasten senden (Send Keys)
- Sichere Tasten senden (Send Keys Secure)
- Feld setzen (Set Field)
- Feld an Position setzen (Set Field at Position)
- Terminalsitzung (Terminal Session)
- Warte auf Feldtext (Wait Field Text)
- Wait Screen Ready
- Warte auf Bildschirmtext (Wait Screen Text)
- Warte auf Text an Position (Wait Text at Position)
- Terminalcodierte Automatisierungs-APIs

UIAutomation-Aktivitäten
Ausgabe- oder Screen-Sraping-Methoden
Ausgabe- oder Screen-Scraping-Methoden beziehen sich auf solche Aktivitäten, mit denen Sie Daten aus einem bestimmten UI-Element oder Dokument, z. B. einer PDF-Datei, extrahieren können.
Um zu verstehen, welcher für die Automatisierung Ihres Geschäftsprozesses besser geeignet ist, sehen wir uns die Unterschiede zwischen ihnen an.
| Funktionsmethode | Geschwindigkeit | Genauigkeit | Ausführung im Hintergrund | Textposition extrahieren | Ausgeblendeten Text extrahieren | Unterstützung für Citrix: |
|---|---|---|---|---|---|---|
| FullText | 10/10 | 100% | ja | nein | ja | nein |
| Nativ | 8/10 | 100% | nein | ja | nein | nein |
| OCR | 3/10 | 98% | nein | ja | nein | ja |
FullText ist die Standardmethode, sie ist schnell und zuverlässig, jedoch kann sie im Gegensatz zur Native-Methode die Bildschirmkoordinaten des Texts nicht extrahieren.
Beide Methoden funktionieren nur mit Desktop-Anwendungen, aber die Native-Methode funktioniert nur mit Apps, die zum Wiedergeben von Text mit dem Graphics Device Interface (GDI) erstellt wurden.
OCR ist nicht zu 100 % genau, kann aber nützlich sein, um Text zu extrahieren, den die beiden anderen Methoden nicht verwenden konnten, da es mit allen Anwendungen, einschließlich Citrix, funktioniert. Studio verwendet standardmäßig zwei OCR-Engines: Google Tesseract und Microsoft Modi.
Sprachen können für OCR-Engines geändert werden und erfahren Sie, wie Sie OCR-Sprachen installieren.
| Funktionsmethode | Unterstützung mehrerer Sprachen | Bevorzugte Bereichsgröße | Unterstützung für Farbinvertierung | Legen Sie das Erwartete Textformat fest | Zulässige Zeichen filtern | Am besten mit Microsoft-Schriftarten |
|---|---|---|---|---|---|---|
| Google Tesseract | Kann hinzugefügt werden | Klein | ja | ja | ja | nein |
| MIcrosoft MODI | Standardmäßig unterstützt | Groß | nein | nein | nein | ja |
Um Text aus verschiedenen Quellen zu extrahieren, klicken Sie auf die Schaltfläche Screen-Scraping(Screen Scraping)auf der Registerkarte des Menübands Design in der Gruppe Assistenten (Wizards).
Der Screen-Scraping-Assistent ermöglicht es Ihnen, mithilfe einer der drei oben beschriebenen Ausgabemethoden auf ein UI-Element zu zeigen und den Text daraus zu extrahieren. Studio wählt automatisch eine Screen-Scraping-Methode für Sie aus und zeigt diese oben im Fenster Screen Scraper Wizard an.
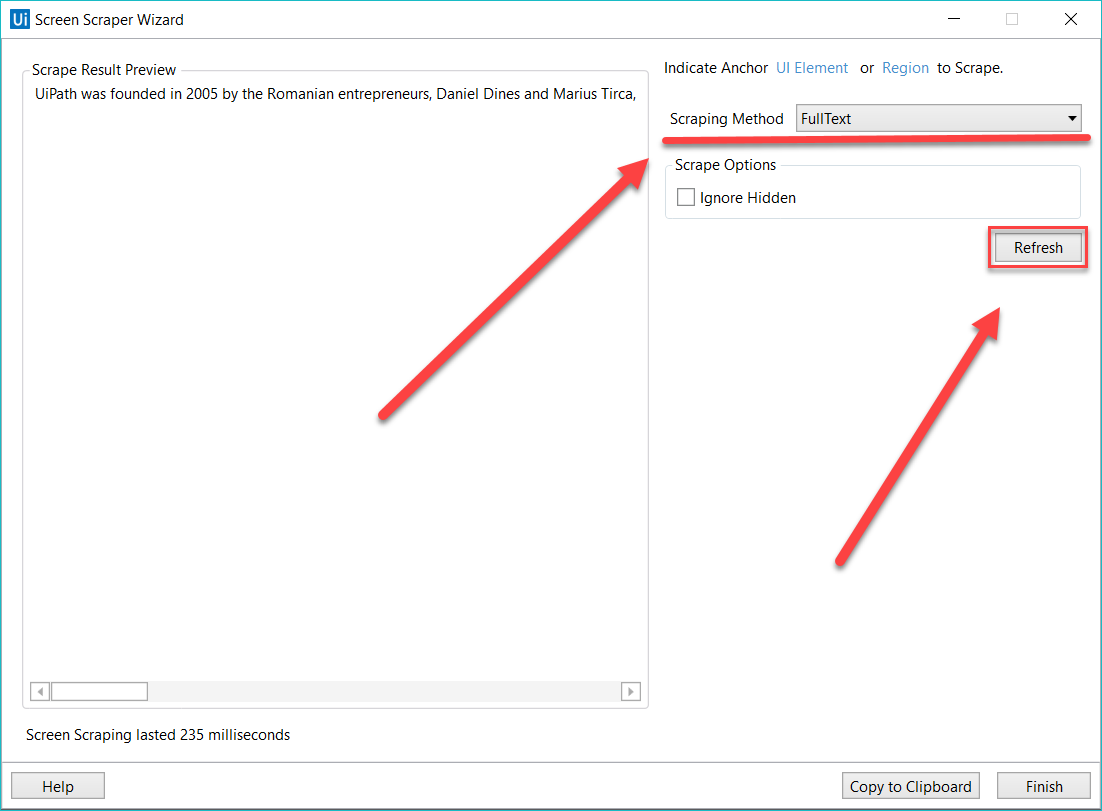
Um die Methode des Screen-Scraping zu ändern, wählen Sie eine andere aus dem Panel Optionen (Options) und klicken Sie anschließend auf Aktualisieren (Refresh).
Wenn Sie mit den Scraping-Ergebnissen zufrieden sind, klicken Sie auf In Zwischenablage kopieren und Fertigstellen. Mit letzterer Option wird der extrahierte Text in die Zwischenablage kopiert und kann einer Aktivität Datentabelle generieren des Panels Designer hinzugefügt werden. Genau wie bei Desktop-Aufzeichnung erzeugt, das Aktivitäten und partielle Selektoren für jede Aktivität enthält.
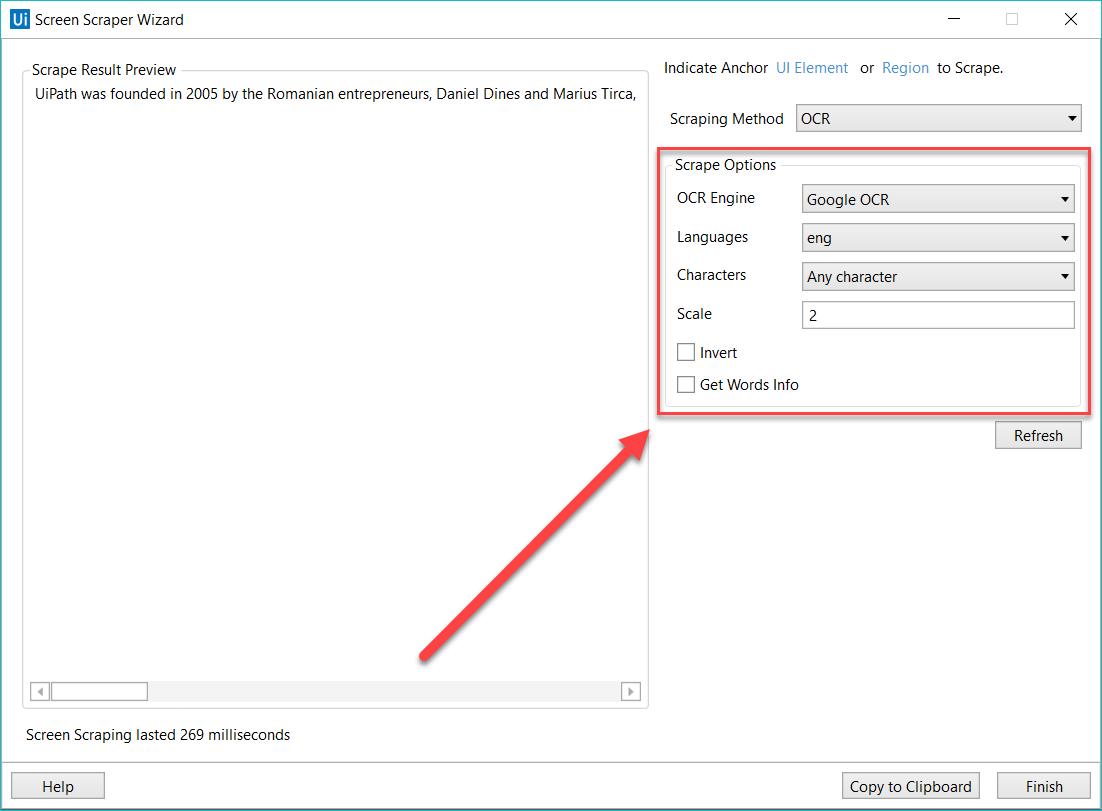
Für jede neue Art von Screen-Scraping gibt es im Screen Scraper Wizard im Panel Optionen (Options) verschiedene Funktionen:
- FullText

- Ignore Hidden – wenn dieses Kontrollkästchen aktiviert ist, wird der ausgeblendete Text des ausgewählten UI-Elements nicht kopiert.
- Nativ

- Keine Formatierung(No Formatting) – Wenn dieses Kontrollkästchen aktiviert ist, extrahiert der kopierte Text keine Formatierungsinformationen aus dem Text. Andernfalls wird die relative Position des extrahierten Texts festgehalten.
- Informationen abrufen – Wenn dieses Kontrollkästchen aktiviert ist, extrahiert Studio auch die Bildschirmkoordinaten jedes Wortes. Darüber hinaus wird das Feld „Benutzerdefinierte Trennzeichen“ angezeigt, mit dem Sie die Zeichen angeben können, die als Trennzeichen verwendet werden. Wenn das Feld leer ist, werden alle bekannten Texttrennzeichen verwendet.
- Google OCR

- Sprachen – nur Englisch ist standardmäßig verfügbar.
- Zeichen(Characters) – Hier können Sie auswählen, welche Zeichenarten extrahiert werden sollen. Die folgenden Optionen sind verfügbar: Beliebiges Zeichen(Any character), Nur Zahlen(Numbers only), Buchstaben(Letters), Großbuchstaben(Uppercase), Kleinbuchstaben(Lowercase), Telefonnummern(Phone numbers), Währung(Currency), Datum(Date) und Benutzerdefiniert(Custom). Wenn Sie Benutzerdefiniert(Custom) auswählen, werden zwei zusätzliche Felder angezeigt: Zugelassen(Allowed) und (Denied), mit denen Sie benutzerdefinierte Regeln erstellen können, anhand derer Zeichen extrahiert bzw. vermieden werden.
- Umkehren (Invert) – wenn dieses Kontrollkästchen aktiviert ist, werden die Farben des UI-Elements vor dem Scraping umgekehrt. Dies ist nützlich, wenn der Hintergrund dunkler ist als die Textfarbe.
- Skalierung (Scale) – der Skalierungsfaktor des ausgewählten UI-Elements oder Bilds. Je höher die Zahl ist, desto mehr vergrößern Sie das Bild. Dies kann zu einer besseren OCR-Erkennung führen und wird bei kleinen Bildern empfohlen.
- Get Words Info – Ruft die Position jedes einzelnen extrahierten Worts auf dem Bildschirm ab.
Hinweis:
In einigen Instanzen von Studio verfügt die Google Tesseract-Engine möglicherweise über Trainingsdateien (über Trainingsdateien: Wikipedia, GitHub), die für bestimmte nicht-englische Sprachen nicht funktionieren. Das Ausführen eines Projekts mit diesen beschädigten Trainingsdateien kann einen Ausnahmefehler auslösen. Um dieses Problem zu beheben, laden Sie die Trainingsdatei für die Sprache, die Sie verwenden möchten, hier herunter und kopieren Sie sie in den Ordner „tessdata“ aus dem UiPath-Installationsverzeichnis. Um zu überprüfen, ob die heruntergeladenen Trainingsdateien funktionieren, können Sie dieses Testprojekt herunterladen .
- UiPath Screen OCR
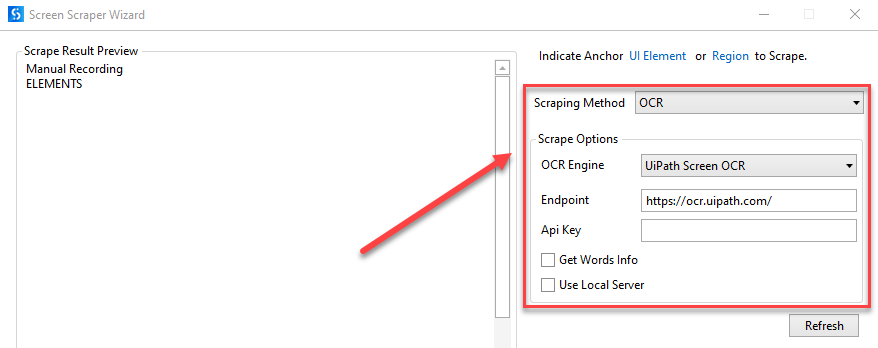
- Endpunkt – Der Endpunkt, an dem das OCR-Modell öffentlich oder über eine ML-Fähigkeit im AI Center gehostet wird.
- API-Schlüssel – Der API-Schlüssel des Endpunkts.
- Get Words Info – Ruft die Position jedes einzelnen extrahierten Worts auf dem Bildschirm ab.
- Lokalen Server verwenden – Wählen Sie diese Option aus, wenn Sie die OCR lokal ausführen möchten (erfordert das Computer Vision Local Server-Paket)
- Microsoft OCR
Wichtig:
Die Microsoft OCR Scraping-Engine unterstützt keine .NET 5-Workflows.

- Languages – ermöglicht es Ihnen, die Sprache des extrahierten Texts zu ändern. Standardmäßig ist Englisch ausgewählt.
- Skalierung (Scale) – der Skalierungsfaktor des ausgewählten UI-Elements oder Bilds. Je höher die Zahl ist, desto mehr vergrößern Sie das Bild. Dies kann zu einer besseren OCR-Erkennung führen und wird bei kleinen Bildern empfohlen.
- Wortinfo abrufen(Get Words Info) – Ruft die Position jedes einzelnen extrahierten Worts am Bildschirm ab.
Neben dem Abrufen von Text aus einem angegebenen UI-Element können Sie auch den Wert mehrerer Attributtypen, seine genaue Bildschirmposition und seine Vorgänger extrahieren.
Diese Art von Informationen kann über dedizierte Aktivitäten extrahiert werden, die sich im Panel Aktivitäten (Activities) unter UI Automation > Element > Find und UI Automation > Element > Attribute befinden.
Diese Aktivitäten sind:
-
Vorgänger abrufen (Get Ancestor) – Ermöglicht das Abrufen eines Vorgängers aus einem angegebenen UI-Element. Sie können angeben, auf welcher Ebene der UI-Hierarchie der Vorgänger gesucht werden soll, und die Ergebnisse in einer UiElement-Variablen speichern.
-
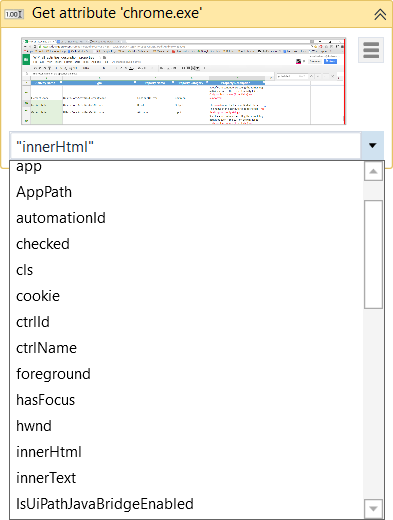
Attribut abrufen (Get Attribute) – Ruft den Wert des angegebenen UI-Element-Attributs ab. Sobald Sie das UI-Element am Bildschirm angeben, wird eine Dropdown-Liste mit allen verfügbaren Attributen angezeigt.
-
Position abrufen (Get Position) – Ruft das umgebende Rechteck des angegebenen UI-Elements ab und unterstützt nur Rechtecks-Variablen.
UiPath Studio verfügt außerdem über Relatives Scraping, eine Scraping-Methode, die den Speicherort des Texts identifiziert, der relativ zu einem Anker abgerufen werden soll. Weitere Informationen dazu finden Sie unter Relatives Scraping.
Sie können Tabellen auch aus unstrukturierten Daten generieren und die Informationen in DataTable-Variablen speichern, indem Sie den Screen Scraping Wizard verwenden. Weitere Informationen finden Sie unter Generieren von Tabellen aus unstrukturierten Daten.