- Visão geral
- Automação de Interface Gráfica
- Sobre o pacote de atividades UIAutomation
- Aplicativos e tecnologias automatizados com a Automação de Interface Gráfica
- Compatibilidade do projeto
- UI-ANA-016 - Extrair URL de navegador aberto
- UI-ANA-017 - ContinuarComErro verdadeiro
- UI-ANA-018 - Listar atividades de OCR/Imagem
- UI-DBP-006 - Uso do contêiner
- UI-DBP-013 - Uso Incorreto da Automação do Excel
- UI-DBP-030 - Uso de variáveis proibidas em seletores
- UI-DBP-031 - Verificação de atividades
- UI-PRR-001 - Simular clique
- UI-PRR-002 - Simular Digitação
- UI-PRR-003 - Uso incorreto do aplicativo aberto
- UI-PRR-004 - Atrasos Embutidos em Código
- UI-REL-001 - Idx grande em Seletores
- UI-SEC-004 - Dados de e-mail do seletor
- UI-SEC-010 — restrições de app/URL
- UI-USG-011 - Atributos não permitidos
- UX-SEC-010 — restrições de app/URL
- UX-DBP-029 - Uso de senha não segura
- UI-PST-001 - Nível de log de auditoria nas configurações do projeto
- Ferramenta de Migração de Navegador do UiPath
- Região do Recorte
- Computer Vision Recorder
- Índice de atividades
- Ativar
- Anchor Base
- Anexar Navegador
- Anexar Janela
- Block User Input
- Texto Explicativo
- Marcar
- Click
- Clicar na Imagem
- Click Image Trigger
- Click OCR Text
- Clicar no Texto
- Click Trigger
- Close Application
- Fechar Guia
- Close Window
- Context Aware Anchor
- Copy Selected Text
- Element Attribute Change Trigger
- Element Exists
- Element Scope
- Element State Change Trigger
- Export UI Tree
- Extrair Dados Estruturados
- Find Children
- Localizar Elemento
- Localizar Imagem
- Find Image Matches
- Find OCR Text Position
- Localizar Elemento Relativo
- Find Text Position
- Get Active Window
- Get Ancestor
- Get Attribute
- Get Event Info
- Get From Clipboard
- Obter Texto Completo
- Get OCR Text
- Get Password
- Get Position
- Get Source Element
- Get Text
- Obter Texto Visível
- Voltar
- Avançar
- Ir para a Página Inicial
- Google Cloud Vision OCR
- Hide Window
- Highlight
- Hotkey Trigger
- Hover
- Focalizar Imagem
- Hover OCR Text
- Focalizar Texto
- Imagem Existe
- Indicate On Screen
- Inject .NET Code
- Inject Js Script
- Invoke ActiveX Method
- Key Press Trigger
- Carregar Imagem
- Maximize Window
- Microsoft Azure Computer Vision OCR
- Microsoft OCR
- Microsoft Project Oxford Online OCR
- Minimize Window
- Monitorar eventos
- Mouse Trigger
- Move Window
- Navegar Para
- OCR Text Exists
- On Element Appear
- On Element Vanish
- Aparecer Na Imagem
- Desaparecer Na Imagem
- Abrir Aplicativo
- Abrir Navegador
- Atualizar Navegador
- Replay User Event
- Restore Window
- Save Image
- Select Item
- Select Multiple Items
- Enviar Tecla de Acesso
- Set Clipping Region
- Set Focus
- Set Text
- Set To Clipboard
- Set Web Attribute
- Show Window
- Iniciar Processo
- System Trigger
- Take Screenshot
- Tesseract OCR
- Texto Existe
- Dica de ferramenta
- Type Into
- Digitar Texto Seguro
- Use Foreground
- Wait Attribute
- Esperar Elemento Desaparecer
- Aguardar Imagem Desaparecer
- Verificação de acessibilidade
- Application event trigger
- Block User Input
- Check/Uncheck
- Check App State
- Check Element
- Click
- Click Event Trigger
- Drag and Drop
- Extract Table Data
- Localizar elementos
- For Each UI Element
- Get Browser Data
- Obter Área de Transferência
- Get Text
- Get URL
- Go To URL
- Highlight
- Hover
- Inject Js Script
- Keyboard Shortcuts
- Keypress Event Trigger
- Mouse Scroll
- Navigate Browser
- Save Image
- Select Item
- Set Browser Data
- Definir Área de Transferência
- Set Runtime Browser
- Set Focus
- Set Text
- Take Screenshot
- Type Into
- Unblock User Input
- Use Application/Browser
- Window operation
- Realize pesquisa no navegador e recupere resultados usando APIs de Automação de interface gráfica
- Navegação na Web
- Localizar imagens
- Clicar em imagens
- Disparar e monitorar eventos
- Criar e substituir arquivos
- Páginas HTML: extrair e manipular informações
- Manipulação de janelas
- Seleção automatizada de listas
- Localizar e manipular elementos de janela
- Gerenciar automação de texto
- Carregar e processar imagens
- Gerenciar ações ativadas pelo mouse
- Automatizar o runtime de aplicativos
- Execução automatizada de um aplicativo local
- Navegação em navegador
- Automação da Web
- Exemplo de escopo de disparador
- Habilitar o suporte de Automação de Interface Gráfica no DevExpress
- Computer Vision Local Server
- Automação Móvel
- Notas de versão
- Sobre a arquitetura de automação de dispositivos móveis
- Compatibilidade do projeto
- Get Log Types
- Get Logs
- Get Page Source
- Get Device Orientation
- Get Session Identifier
- Instalar Aplicativo
- Gerenciar Aplicativo Atual
- Manage Other App
- Open DeepLink
- Abrir URL
- Mobile Device Connection
- Deslizar Direcional
- Padrão de Desenho
- Positional Swipe
- Press Hardware Button
- Set Device Orientation
- Take Screenshot
- Obter parte da captura de tela
- Element Exists
- Execute Command
- Get Attribute
- Get Selected Item
- Get Text
- Set Selected Item
- Set Text
- Deslizar
- Tap
- Type Text
- Terminal
- Notas de versão
- Sobre o pacote de atividades Terminal
- Compatibilidade do projeto
- Melhores práticas
- Find Text
- Get Color At Position
- Get Cursor Position
- Get Field
- Obter Campo na Posição
- Obter Área da Tela
- Get Text
- Obter Texto na Posição
- Mover Cursor
- Mover cursor para o texto
- Enviar Tecla de Controle
- Send Keys
- Send Keys Secure
- Set Field
- Definir Campo na Posição
- Terminal Session
- Aguardar Texto do Campo
- Wait Screen Ready
- Aguardar Texto da Tela
- Aguardar Texto na Posição
- APIs de automação codificadas em terminais

Atividades do UIAutomation
Métodos de extração de saída ou tela
Os métodos de saída ou extração de tela se referem a essas atividades que permitem que você extraia dados de um elemento ou documento de interface gráfica especificado, como um arquivo .pdf.
Para entender qual é o melhor para automatizar seu processo de negócios, vamos ver a diferença entre eles.
| Método de Tapabilidade | Velocidade | Precisão | Execução em segundo plano | Extrair a posição do texto | Extrair texto oculto | Compatível com o Citrix |
|---|---|---|---|---|---|---|
| Texto Completo | 10/10 | 100% | sim | não | sim | não |
| Nativo | 8/10 | 100% | não | sim | não | não |
| OCR | 3/10 | 98% | não | sim | não | sim |
Texto Completo é o método padrão, ele é rápido e preciso, mas diferente do método Nativo, ele não consegue extrair as coordenadas de tela do texto.
Ambos os métodos funcionam apenas com aplicativos de área de trabalho, mas o método Nativo funciona apenas com aplicativos que são criados para renderizar texto com a Graphics Device Interface (GDI).
O OCR não é 100% preciso, mas pode ser usado para extrair textos que os outros dois métodos não detectaram, pois ele funciona com todos os aplicativos, incluindo o Citrix. O Studio usa dois mecanismos de OCR por padrão: o Google Tesseract e o Microsoft Modi.
Os idiomas podem ser alterados para os mecanismos de OCR e você pode descobrir como Instalar os idiomas de OCR.
| Método de Tapabilidade | Suporte a várias linguagens | Tamanho de área preferível | Compatibilidade com a inversão de cor | Definir o formato de texto esperado | Filtrar os caracteres permitidos | Melhor com o Microsoft Fonts |
|---|---|---|---|---|---|---|
| Google Tesseract | Pode ser adicionado | Pequeno | sim | sim | sim | não |
| Microsoft MODI | Compatível por padrão | Grande | não | não | não | sim |
Para começar a extrair texto de várias fontes, clique no botão Extração de Tela, no grupo Assistentes, na aba Design da faixa de opções.
O assistente de extração de tela permite que você aponte em um elemento de interface gráfica e extraia texto dele, usando um dos três métodos de saída descritos acima. O Studio escolhe automaticamente um método de extração de tela para você e exibe-o no topo da janela Assistente de Extração de Tela.
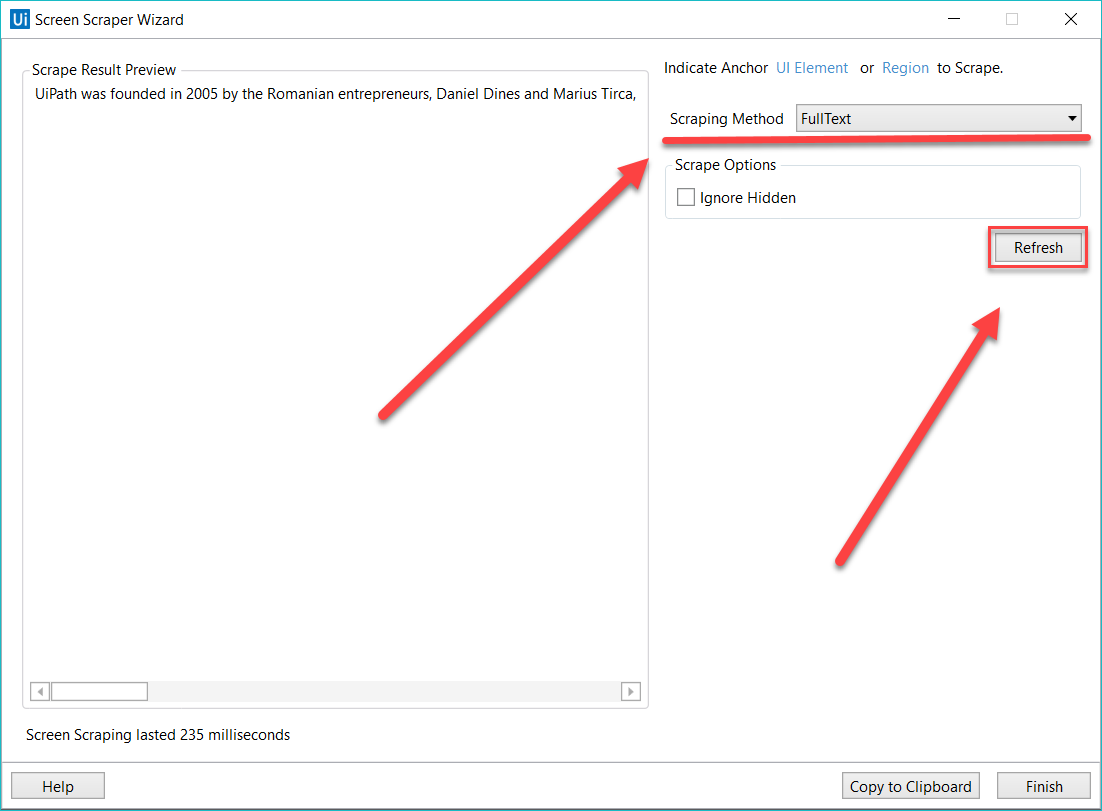
Para alterar o método de extração de tela, selecione outro no painel Opções e clique em Atualizar.
Quando estiver satisfeito com os resultados da extração, clique em Copiar para Área de Transferência e depois em Finalizar. A última opção copia o texto extraído para a área de transferência, e ele pode ser adicionado a uma atividade Generate Data Table no painel Designer . Assim como a gravação da área de trabalho, a extração de tela gera um contêiner (com o seletor da janela de nível superior) que contém atividades e seletores parciais para cada atividade.
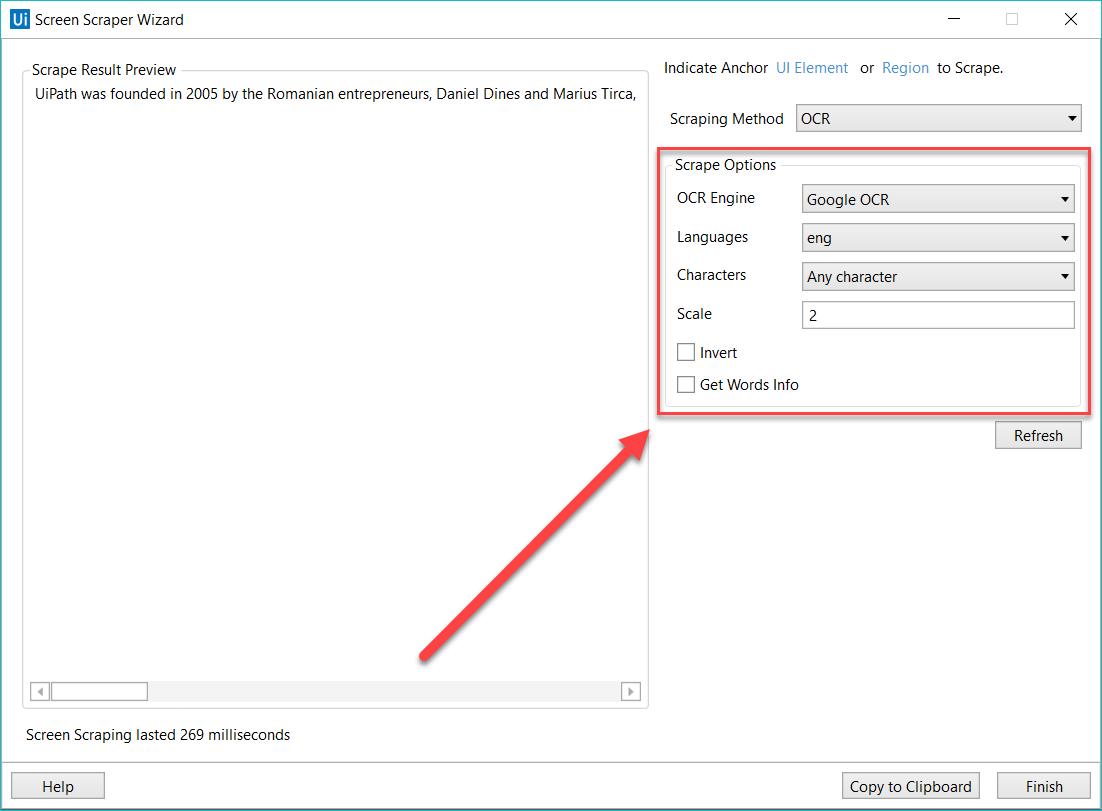
Cada tipo de extração de tela vem com recursos diferentes no Assistente de Extração de Tela, no painel Opções:
- Texto Completo

- Ignorar Oculto – Quando essa caixa de seleção estiver selecionada, o texto oculto do elemento de interface gráfica selecionado não será copiado.
- Nativo

- Sem Formatação – Quando essa caixa de seleção estiver selecionada, o texto copiado não extrai informações de formatação do texto. Caso contrário, a posição relativa do texto extraído será mantida.
- Obter Informações de Palavras – Quando esta caixa de seleção estiver selecionada, o Studio também extrairá as coordenadas da tela de cada palavra. Além disso, o campo Separadores Personalizados será exibido, o que permite que você especifique os caracteres usados como separadores. Se o campo estiver vazio, todos os separadores de texto conhecidos serão usados.
- Google OCR

- Idiomas – Apenas inglês está disponível por padrão.
- Caracteres – Permite que você selecione os tipos de caracteres a serem extraídos. As seguintes opções estão disponíveis, Todos os caracteres, Apenas números, Letras, Letras maiúsculas, Letras minúsculas, Número de telefone, Moeda, Data e Personalizados. Se você selecionar Personalizados, dois campos adicionais, Permitidos e Negados, são exibidos e permitem que você crie regras personalizadas sobre os tipos de caracteres a serem extraídos e os que devem ser evitados.
- Inverter – Quando essa caixa de seleção estiver selecionada, as cores do elemento de interface gráfica serão invertidas antes da extração. Isso é útil quando o plano de fundo estiver mais escuro que a cor do texto.
- Escala – O fator de dimensionamento do elemento ou imagem de interface gráfica selecionado. Quanto mais alto o número, mais a imagem é ampliada. Isso pode fornecer uma leitura melhor de OCR e é recomendado para imagens pequenas.
- Obter Informações sobre Palavras – Obtém a posição na tela de cada palavra extraída.
Observação:
Em algumas instâncias do Studio, o mecanismo do Google Tesseract pode ter arquivos de treinamento (Sobre arquivos de treinamento: Wikipedia, GitHub) que não funcionam para idiomas que não sejam o inglês. A execução de um projeto com esses arquivos corrompidos pode causar exceções. Para corrigir esse problema, baixe o arquivo de treinamento para o idioma que você deseja usar aqui. Copie-o para a pasta tessdata no diretório de instalação da UiPath. Para verificar se os arquivos de treinamento baixados funcionam, baixe este projeto de teste.
- UiPath Screen OCR
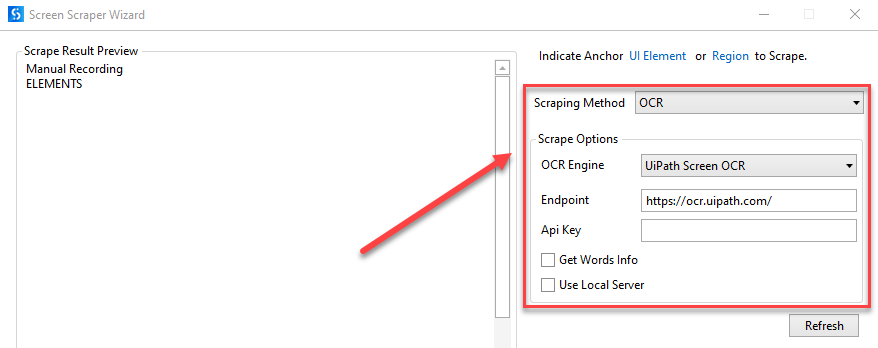
- Ponto de Extremidade – O ponto de extremidade no qual o modelo de OCR está hospedado, seja publicamente seja por meio de uma Habilidade de ML no AI Center.
- Chave de API – A chave de API do ponto de extremidade.
- Obter Informações sobre Palavras – Obtém a posição na tela de cada palavra extraída.
- Usar Servidor Local — selecione essa opção se você quiser executar o OCR localmente (requer o Computer Vision Local Server Pack)
- Microsoft OCR
Importante:
O mecanismo de extração do Microsoft OCR não é compatível com os fluxos de trabalho do .NET 5.

- Idiomas – Permite que você altere o idioma do texto extraído. O inglês fica selecionado por padrão.
- Escala – O fator de dimensionamento do elemento ou imagem de interface gráfica selecionado. Quanto mais alto o número, mais a imagem é ampliada. Isso pode fornecer uma leitura melhor de OCR e é recomendado para imagens pequenas.
- Obter Informações sobre Palavras – Obtém a posição na tela de cada palavra extraída.
Além de tirar texto de um elemento de interface gráfica indicado, você também pode extrair o valor de vários tipos de atributos, sua posição de tela exata e seu ancestral.
Esse tipo de informação pode ser extraído por meio de atividades dedicadas que são encontradas no painel Atividades, em Automação de interface gráfica > Elemento > Localizar e Automação de interface gráfica > Elemento > Atributo.
Essas atividades são:
-
Obter Ancestral – Permite que você recupere um ancestral de um elemento de interface gráfica especificado. Você pode indicar em qual nível da hierarquia de interface gráfica localizar o ancestral, e armazenar os resultados em uma variável UiElement.
-
Obter Atributo – Recupera o valor de um atributo de elemento de interface gráfica especificado. Depois que você indicar o elemento de interface gráfica na tela, uma lista suspensa com todos os atributos disponíveis será exibida.
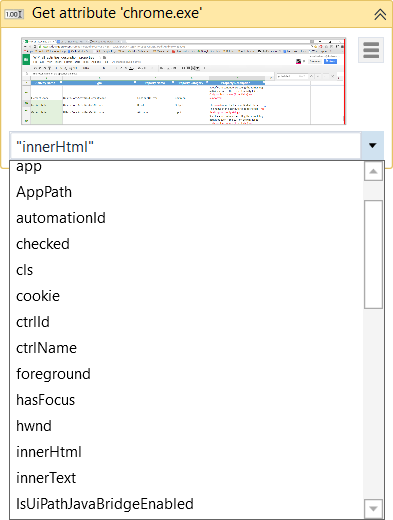
-
Obter Posição – Recupera o retângulo de limite do UiElement especificado, e é compatível apenas com as variáveis Rectangle.
O UiPath Studio também possui o Relative Scraping, um método de extração que identifica o local do texto a ser recuperado em relação a uma âncora. Para saber mais, consulte Extração relativa.
Também é possível gerar tabelas a partir de dados não estruturados e armazenar as informações nas variáveis DataTable, usando o Assistente de Extração de Tela. Para obter mais informações, consulte Geração de tabelas a partir de dados não estruturados.