- Overview
- UI Automation
- About the UI Automation activity package
- Applications and technologies automated with UI Automation
- Project compatibility
- UI-ANA-016 - Pull Open Browser URL
- UI-ANA-017 - ContinueOnError True
- UI-ANA-018 - List OCR/Image Activities
- UI-DBP-006 - Container Usage
- UI-DBP-013 - Excel Automation Misuse
- UI-DBP-030 - Forbidden Variables Usage In Selectors
- UI-DBP-031 - Activity verification
- UI-PRR-001 - Simulate Click
- UI-PRR-002 - Simulate Type
- UI-PRR-003 - Open Application Misuse
- UI-PRR-004 - Hardcoded Delays
- UI-REL-001 - Large Idx in Selectors
- UI-SEC-004 - Selector Email Data
- UI-SEC-010 - App/Url Restrictions
- UI-USG-011 - Non Allowed Attributes
- UX-SEC-010 - App/Url Restrictions
- UX-DBP-029 - Insecure Password Use
- UI-PST-001 - Audit Log Level in Project Settings
- UiPath Browser Migration Tool
- Clipping region
- Computer Vision Recorder
- About Data Scraping
- Example of Using Data Scraping
- Activities index
- Activate
- Anchor Base
- Attach Browser
- Attach Window
- Block User Input
- Callout
- Check
- Click
- Click Image
- Click Image Trigger
- Click OCR Text
- Click Text
- Click Trigger
- Close Application
- Close Tab
- Close Window
- Context Aware Anchor
- Copy Selected Text
- Element Attribute Change Trigger
- Element Exists
- Element Scope
- Element State Change Trigger
- Export UI Tree
- Extract Structured Data
- Find Children
- Find Element
- Find Image
- Find Image Matches
- Find OCR Text Position
- Find Relative Element
- Find Text Position
- Get Active Window
- Get Ancestor
- Get Attribute
- Get Event Info
- Get From Clipboard
- Get Full Text
- Get OCR Text
- Get Password
- Get Position
- Get Source Element
- Get Text
- Get Visible Text
- Go Back
- Go Forward
- Go Home
- Google Cloud Vision OCR
- Hide Window
- Highlight
- Hotkey Trigger
- Hover
- Hover Image
- Hover OCR Text
- Hover Text
- Image Exists
- Indicate On Screen
- Inject .NET Code
- Inject Js Script
- Invoke ActiveX Method
- Key Press Trigger
- Load Image
- Maximize Window
- Microsoft Azure Computer Vision OCR
- Microsoft OCR
- Microsoft Project Oxford Online OCR
- Minimize Window
- Monitor Events
- Mouse Trigger
- Move Window
- Navigate To
- OCR Text Exists
- On Element Appear
- On Element Vanish
- On Image Appear
- On Image Vanish
- Open Application
- Open Browser
- Refresh Browser
- Replay User Event
- Restore Window
- Save Image
- Select Item
- Select Multiple Items
- Send Hotkey
- Set Clipping Region
- Set Focus
- Set Text
- Set To Clipboard
- Set Web Attribute
- Show Window
- Start Process
- System Trigger
- Take Screenshot
- Tesseract OCR
- Text Exists
- Tooltip
- Type Into
- Type Secure Text
- Use Foreground
- Wait Attribute
- Wait Element Vanish
- Wait Image Vanish
- Accessibility Check
- Application Event Trigger
- Block User Input
- Check/Uncheck
- Check App State
- Check Element
- Click
- Click Event Trigger
- Drag and Drop
- Extract Table Data
- Find Elements
- For Each UI Element
- Get Browser Data
- Get Clipboard
- Get Text
- Get URL
- Go to URL
- Highlight
- Hover
- Inject Js Script
- Keyboard Shortcuts
- Keypress Event Trigger
- Mouse Scroll
- Navigate Browser
- Select Item
- Set Browser Data
- Set Clipboard
- Set Runtime Browser
- Set Focus
- Set Text
- Take Screenshot
- Type Into
- Unblock User Input
- Use Application/Browser
- Window Operation
- Perform browser search and retrieve results using UI Automation APIs
- Web Browsing
- Find Images
- Click Images
- Trigger and Monitor Events
- Create and Override Files
- HTML Pages: Extract and Manipulate Information
- Window Manipulation
- Automated List Selection
- Find and Manipulate Window Elements
- Manage Text Automation
- Load and Process Images
- Manage Mouse Activated Actions
- Automate Application Runtime
- Automated Run of a Local Application
- Browser Navigation
- Web Automation
- Trigger Scope Example
- Enable UI Automation support in DevExpress
- Computer Vision Local Server
- Mobile Automation
- Release notes
- About the mobile device automation architecture
- Project compatibility
- Get Log Types
- Get Logs
- Get Page Source
- Get Device Orientation
- Get Session Identifier
- Install App
- Manage Current App
- Manage Other App
- Open DeepLink
- Open URL
- Mobile Device Connection
- Directional Swipe
- Draw Pattern
- Positional Swipe
- Press Hardware Button
- Set Device Orientation
- Take Screenshot
- Take Screenshot Part
- Element Exists
- Execute Command
- Get Attribute
- Get Selected Item
- Get Text
- Set Selected Item
- Set Text
- Swipe
- Tap
- Type Text
- Terminal
- Release notes
- About the Terminal activity package
- Project compatibility
- Best practices
- Find Text
- Get Color at Position
- Get Cursor Position
- Get Field
- Get Field at Position
- Get Screen Area
- Get Text
- Get Text at Position
- Move Cursor
- Move Cursor to Text
- Send Control Key
- Send Keys
- Send Keys Secure
- Set Field
- Set Field at Position
- Terminal Session
- Wait Field Text
- Wait Screen Ready
- Wait Screen Text
- Wait Text at Position

UI Automation activities
About Data Scraping
Data scraping enables you to extract structured data from your browser, application or document to a database,.csv file or even Excel spreadsheet.
It is recommended to run your web automations on Internet Explorer 11 and above, Mozilla Firefox 50 or above, or the latest version of Google Chrome.
Structured data is a specific kind of information that is highly organized and is presented in a predictable pattern. For example, all Google search results have the same structure: a link at the top, a string of the URL and a description of the web page. This structure enables Studio to easily extract the information, as it always knows where to find it.
The scraping wizard can be opened from the Design tab, by clicking the Data Scraping button.

The main steps of the data scraping wizard are:
- Select the first and last fields in the web page, document or application that you want to extract data from, so that Studio can deduce the pattern of the information.

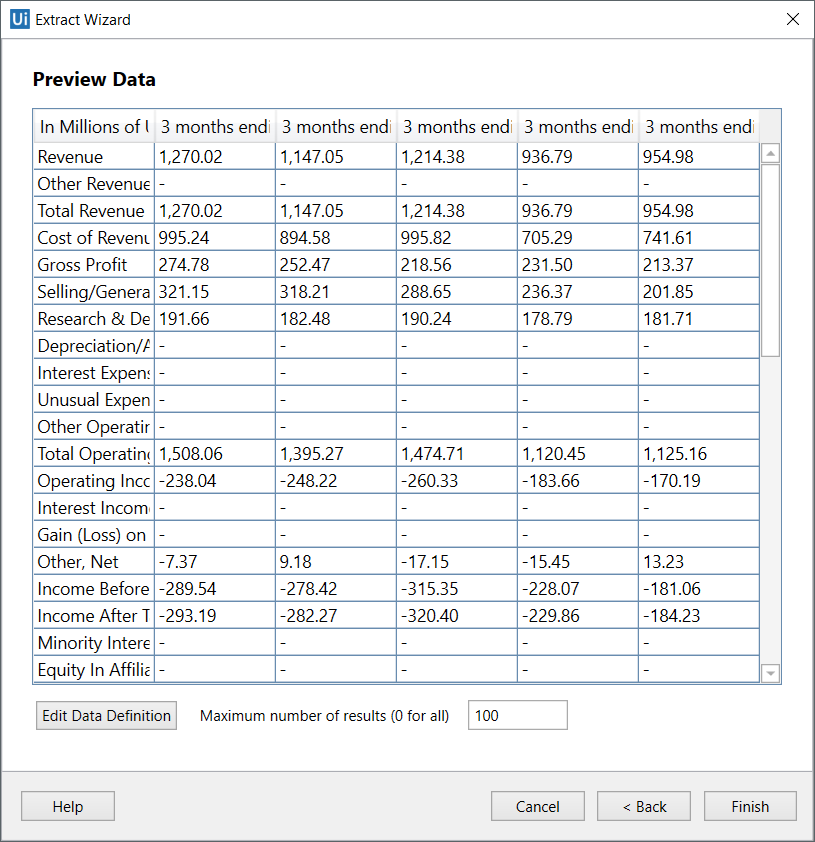
Studio automatically detects if you indicated a table cell, and asks you if you want to extract the entire table. If you click Yes, the Extract Wizard displays a preview of the selected table data.
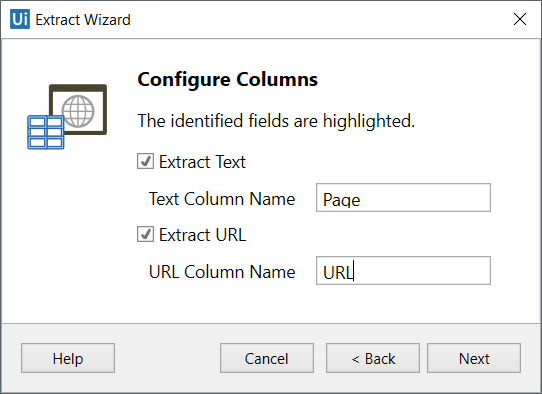
- Customize column headers and choose whether or not to extract URLs.
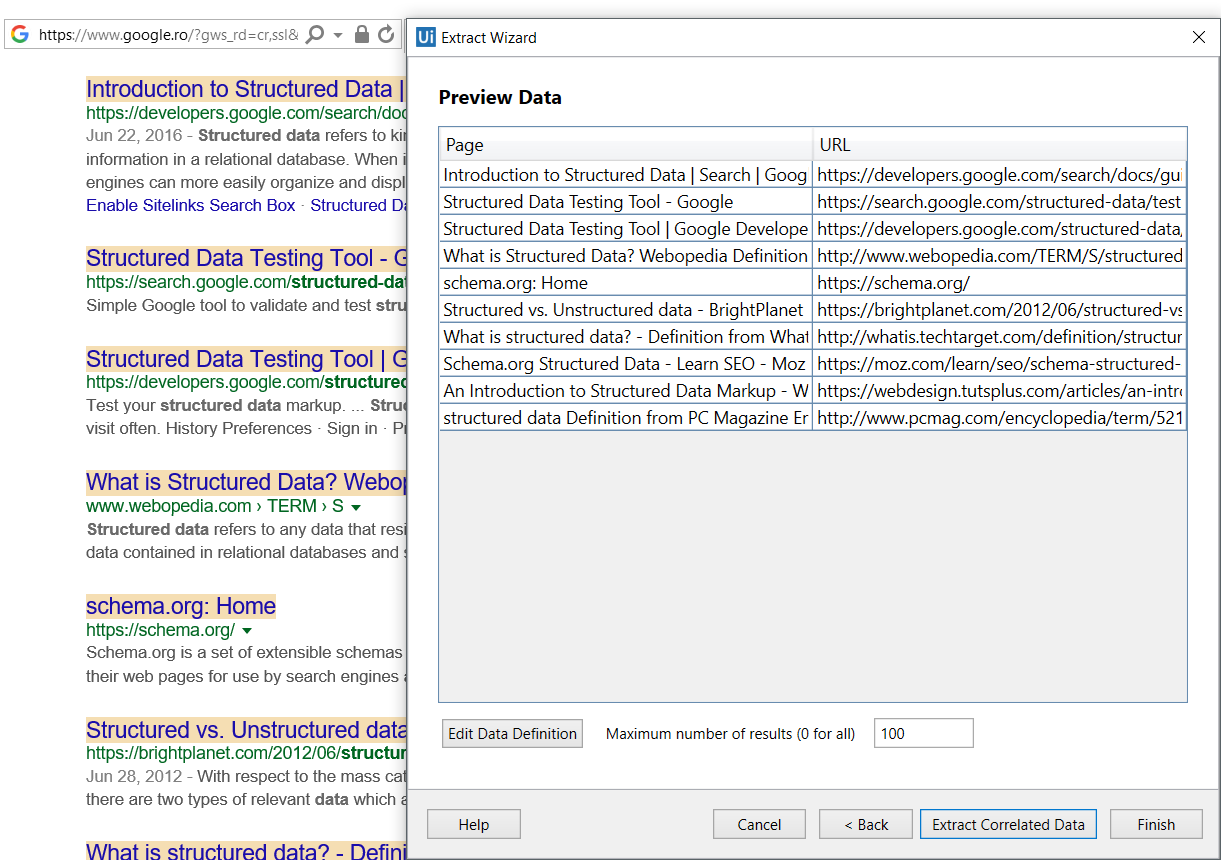
- Preview the data, edit the number of maximum results to be extracted and change the order of the columns.
-
Optionally click Extract Correlated Data. This enables you to go through the Extract Wizard again, to extract additional info and add it as a new column in the same table.
-
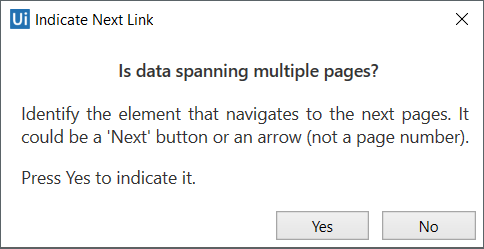
Indicate the Next button in the web page, application or document (if the information you want to extract spans multiple pages).
After you are finished with the wizard, a sequence is generated in Studio.
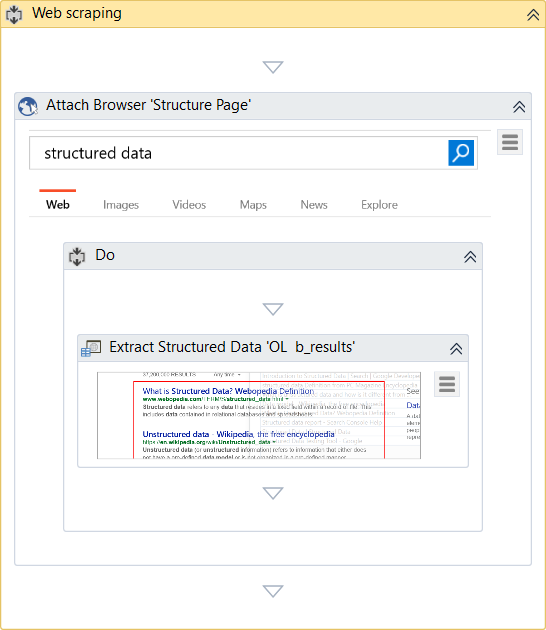
Data scraping always generates a container (Attach Browser or Attach Window) with a selector for the top-level window and an Extract Structured Data activity with a partial selector, thus ensuring a correct identification of the app to be scraped.
Additionally, the Extract Structured Data activity also comes with an automatically generated XML string (in the ExtractMetadata property) that indicates the data to be extracted.
Lastly, all the scraped information is stored in a DataTable variable, that you can later use to populate a database, a.csv file or an Excel spreadsheet.