- Visão geral
- Introdução
- Criação de modelos
- Consumo de modelos
- Detalhes do modelo
- Pontos de extremidade públicos para o Automation Cloud e Test Cloud
- Pontos de extremidade públicos para a Automation Cloud e Test Cloud Public Sector
- 1040 – tipo de documento
- 1040 Agendamento C – tipo de documento
- 1040 Agendamento D – tipo de documento
- 1040 Agendamento E – tipo de documento
- 1040x – tipo de documento
- 3949a – tipo de documento
- 4506T – tipo de documento
- 709 – tipo de documento
- 941x – tipo de documento
- 9465 – tipo de documento
- ACORD125 – tipo de documento
- ACORD126 – tipo de documento
- ACORD131 – tipo de documento
- ACORD140 – tipo de documento
- ACORD25 – tipo de documento
- Extratos bancários – tipo de documento
- Conhecimentos de embarque – tipo de documento
- Certificado de incorporação – tipo de documento
- Certificado de origem – tipo de documento
- Verificações – tipo de documento
- Certificado de produto infantil – tipo de documento
- CMS 1500 – tipo de documento
- Declaração de conformidade UE – tipo de documento
- Demonstrações financeiras – tipo de documento
- FM1003 – tipo de documento
- I9 – tipo de documento
- Cartões de identificação – tipo de documento
- Faturas – tipo de documento
- Faturas2 - tipo de documento
- Faturas Austrália – tipo de documento
- Faturas China – tipo de documento
- Faturas hebraicas – tipo de documento
- Faturas Índia – tipo de documento
- Faturas Japão – tipo de documento
- Faturas de Envio – tipo de documento
- Listas de embalagem – tipo de documento
- Holerites – tipo de documento
- Passaportes – tipo de documento
- Ordens de compra – tipo de documento
- Recibos – tipo de documento.
- Recibos2 - tipo de documento
- Recibos Japão – tipo de documento
- Avisos de Remessa – tipo de documento
- UB04 – tipo de documento
- Divulgações de fechamentos de hipotecas dos EUA - tipo de documento
- Contas de serviços públicos – tipo de documento
- Títulos de veículos – tipo de documento
- W2 – tipo de documento
- W9 – tipo de documento
- Idiomas suportados
- Painéis de insights
- Dados e segurança
- Geração de logs
- Licenciamento
- Como fazer
- Solução de problemas

Guia do usuário do Document Understanding.
UiPath® Helix Extractor 1.0
O modelo de linguagem grande do Helix Extractor 1.0 (LLM) é nossa mais recente tecnologia de modelo de extração de dados, projetada para substituir modelos de geração atual usados dentro do UiPath® Document UnderstandingTM. Embora o Helix Extractor 1.0 opere de forma semelhante aos modelos anteriores, ele foi treinado usando uma ampla variedade de documentos. Isso permite que ele processe tipos de documentos comuns com pouco ou nenhum treinamento necessário. O que diferencia o Helix Extractor 1.0 LLM é sua arquitetura generativa, que melhora significativamente a precisão e simplifica a extração. Além disso, você também pode ajustar o modelo com seus conjuntos de dados exclusivos.
Para obter mais informações sobre a arquitetura do Helix Extractor 1.0 e as técnicas usadas para treinamento, consulte a página Helix Extractor 1.0 em nosso blog de IA.
Disponibilidade
Atualmente, o UiPathHelix Extractor está disponível apenas para tenants baseados nos EUA (excluindo GxP e Government Cloud) em projetos modernos do Document Understanding.
O UiPath Helix Extractor está disponível para projetos clássicos e modernos ao usar pontos de extremidade públicos nas seguintes regiões:
- Pontos de extremidade públicos para modelos de extração na Europa são baseados no Helix Extractor, exceto para Demonstrações financeiras.
- Os seguintes pontos de extremidade públicos para modelos de extração são baseados no Helix Extractor na Região do Japão:
- Faturas da China
- Faturas do Japão
- Recibos Japão
Melhorias em relação à geração anterior
O Helix Extractor LLM oferece inúmeros aprimoramentos em relação aos modelos anteriores. Melhora a precisão, especialmente com tabelas, adapta-se a vários layouts de documentos para reduzir os esforços de anotação e aumenta as taxas de automação.
As principais melhorias incluem:
- Precisão aprimorada: o Helix Extractor LLM oferece uma taxa de precisão maior e uma pontuação F1 superior para documentos semiestruturados, como faturas, recibos e ordens de compra. Isso garante uma extração de dados precisa e consistente.
- Anotação sem esforço: o modelo reduz o trabalho manual exigindo apenas uma anotação por documento, eliminando a necessidade de anotar cada instância de campo em cada página.
- Automação aprimorada: com uma maior correlação entre nível de confiança e precisão, o Helix Extractor LLM aprimora as taxas de automação enquanto reduz o número de documentos enviados ao Action Center para o mesmo nível de precisão.
A partir de nossos testes internos, o Helix Extractor superou seu antecessor em desempenho. Reduziu a taxa de falsos positivos em cerca de 15% e a taxa de falsos negativos caiu quase 17%.
Como usar o Helix Extractor
O Helix Extractor LLM está disponível exclusivamente para projetos modernos do Document Understanding.Apesar da introdução do Helix Extractor, todas as versões do projeto existentes ainda usarão versões de modelos atuais.Isso garante uma transição perfeita sem qualquer interrupção nos fluxos de trabalho de produção em andamento.
Para iniciar o treinamento de um tipo de documento existente no Helix Extractor, desative e ative a confirmação de todos os campos em alguns documentos.
-
Escolha o tipo de documento que você deseja treinar no Helix Extractor.
-
Selecione um documento.
-
Selecione todos os campos do documento e escolha Excluir.
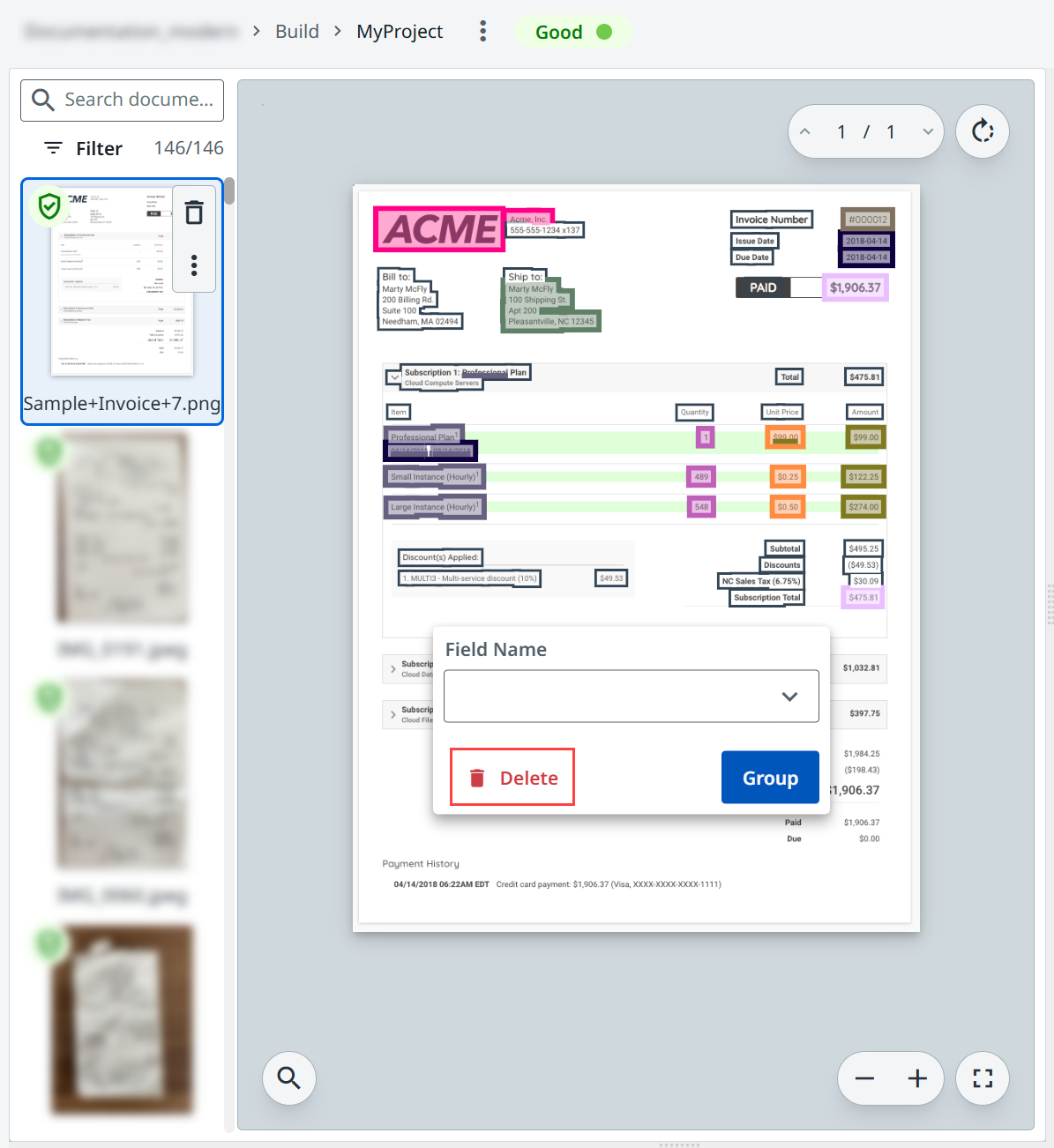
-
Anote todos os campos do documento e selecione Confirmar.
Observação:Repita as etapas 3 e 4 até que o treinamento seja iniciado no tipo de documento escolhido.
Como verificar se o Helix Extractor está habilitado
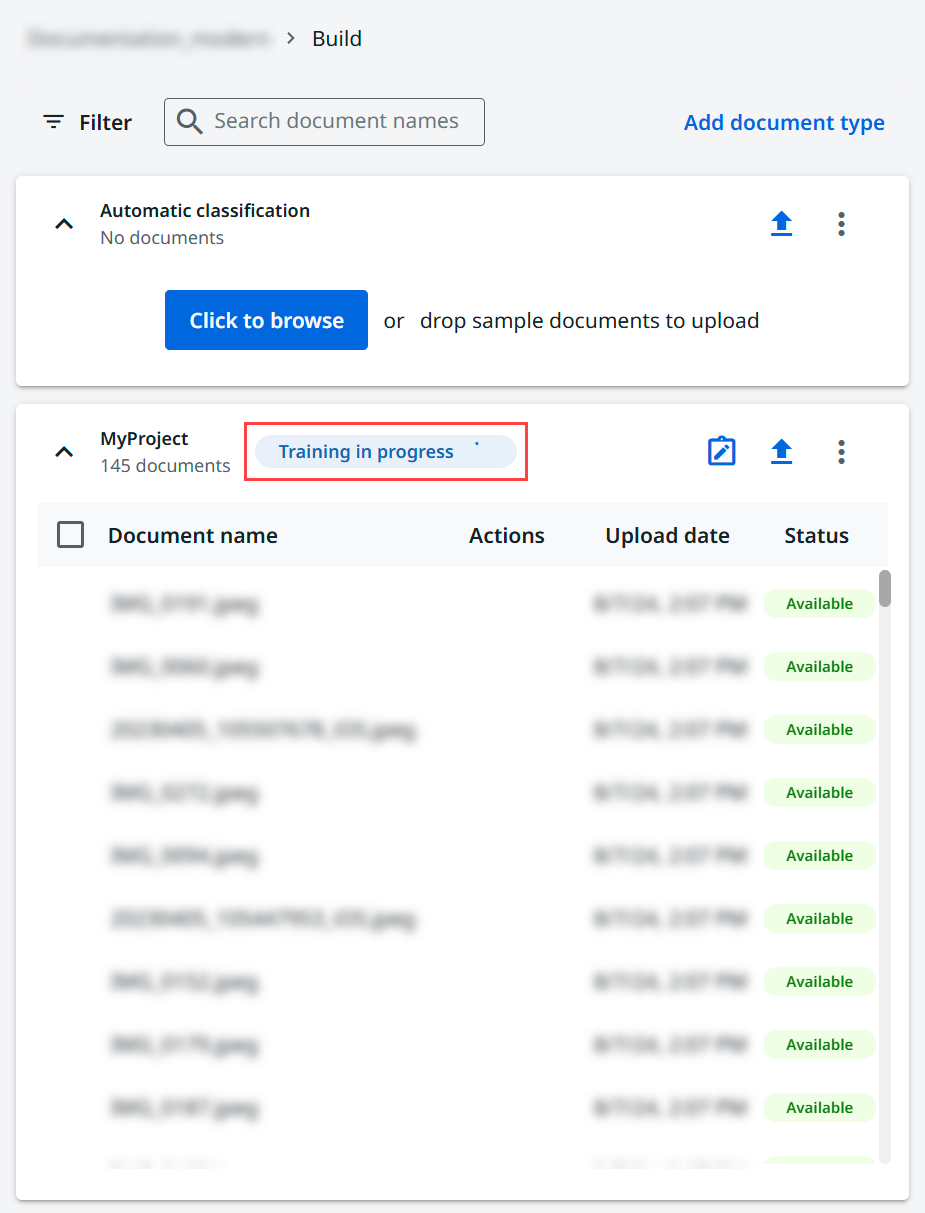
Após treinar seus modelos no Helix Extractor, verifique a versão do modelo para certificar-se de que o Helix Extractor esteja habilitado.
-
Acesse a página Publicar e crie uma nova versão do projeto.
-
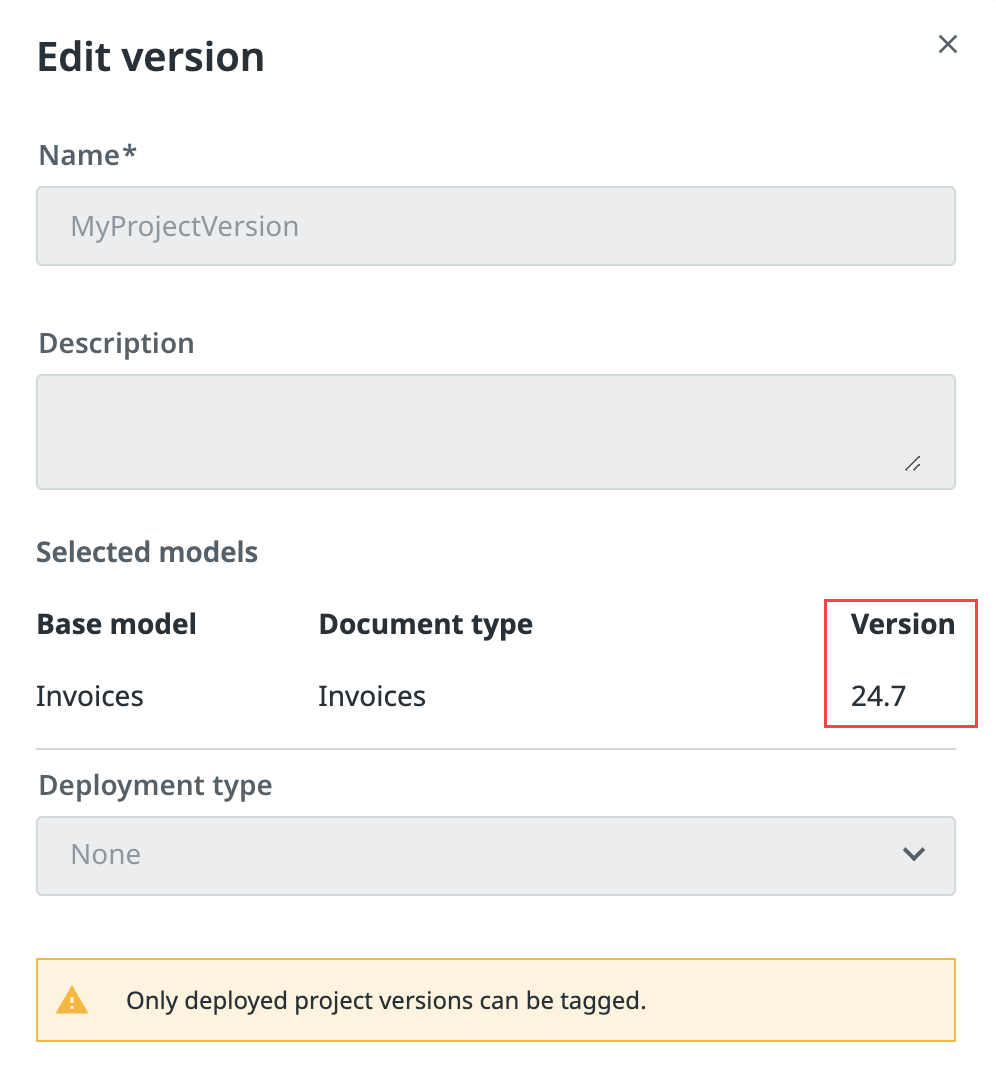
Selecione o ícone de três pontos ⋮ ao lado da versão do projeto e escolha Editar Versão para verificar a versão do modelo.
Observação:Todos os modelos da versão 24.7 ou superior são modelos do UiPath Helix Extractor.
Otimizando resultados
Os nomes de campos que você escolher podem afetar muito o desempenho do modelo. Para garantir resultados ideais, use linguagem natural e gramática adequada para nomes de campos. Você deve usar apenas acrônimos amplamente reconhecidos, como Número (Nº), Conta (Cta), Endereço (End) e Apartamento (Apto). Atualmente apenas idiomas da Europa Ocidental são compatíveis, então certifique-se de que os nomes de campos escolhidos alinhem-se com esses idiomas. Abstenha-se de usar nomes não descritivos, como "Coluna 3", a menos que o documento use especificamente essa terminologia.
Escolha entre o Helix Extractor e o tipo de modelo legado
O UiPath Helix Extractor atualmente é compatível apenas com escrita de idiomas latinos. Se você precisar treinar um modelo em idiomas de escrita não latina, escolha o tipo de modelo legado. Se o modelo legado estiver selecionado, escolha o modelo base apropriado para seu tipo de documento.
Para escolher entre o tipo de modelo Helix Extractor ou legado, navegue até a guia Configurações no Document Type Manager e selecione o tipo de modelo necessário na lista suspensa Tipo de modelo .
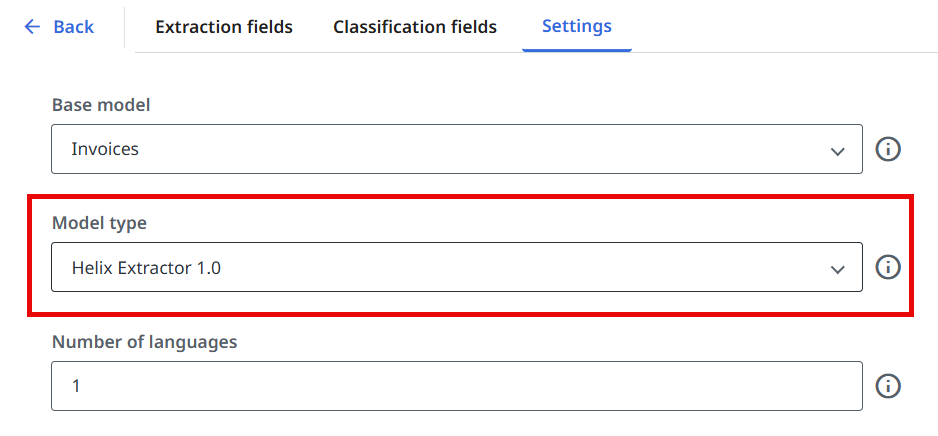
É necessário publicar uma nova versão do projeto após a implantação das alterações.
Limitações conhecidas do UiPath™ Helix Extractor
As seguintes limitações aplicam-se atualmente ao UiPathHelix Extractor:
- Os campos extraídos devem corresponder exatamente ao texto nos documentos. Esse processo não inclui resumo ou outros tipos de análise de texto.
- Os seguintes tipos de documento não são baseados atualmente no Helix Extrator e ainda funcionam na geração anterior:
- Demonstrações financeiras
- Faturas da China
- Faturas em hebraico
- Faturas do Japão
Os tipos de documentos que não são atualmente compatíveis com o modelo do Helix Extractor têm a seguinte mensagem na lista suspensa Adicionar tipo de documento : O tipo de documento será treinado usando o modelo legado.
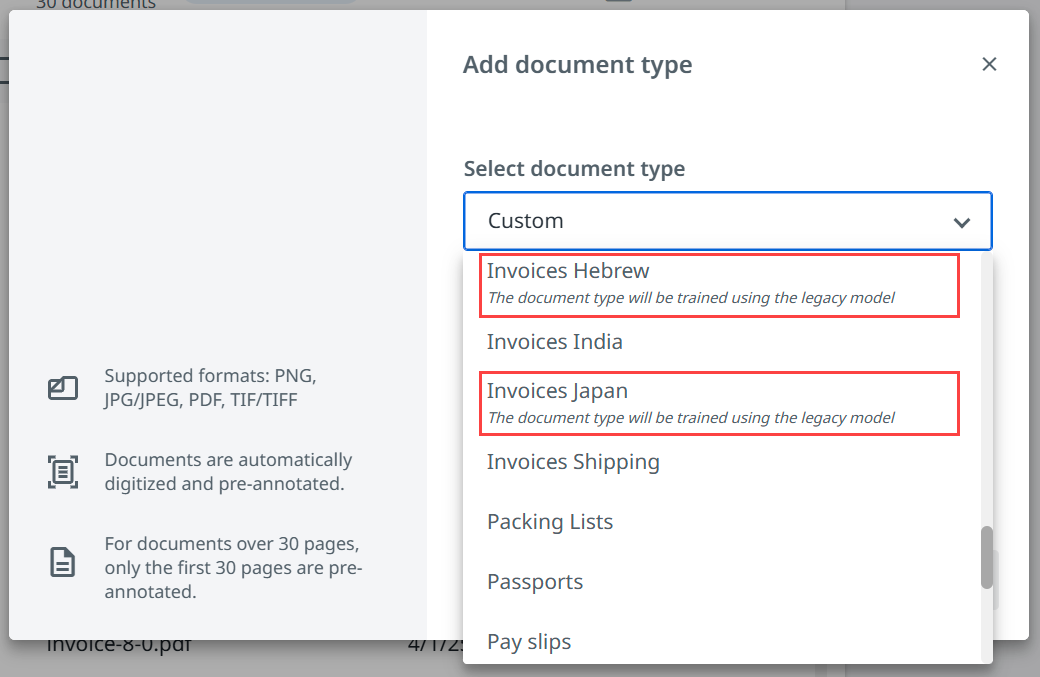
O UiPathHelix Extractor atualmente não é compatível com idiomas de escrita não latina.