了解基于 UiPath 的智能体自动化和编排
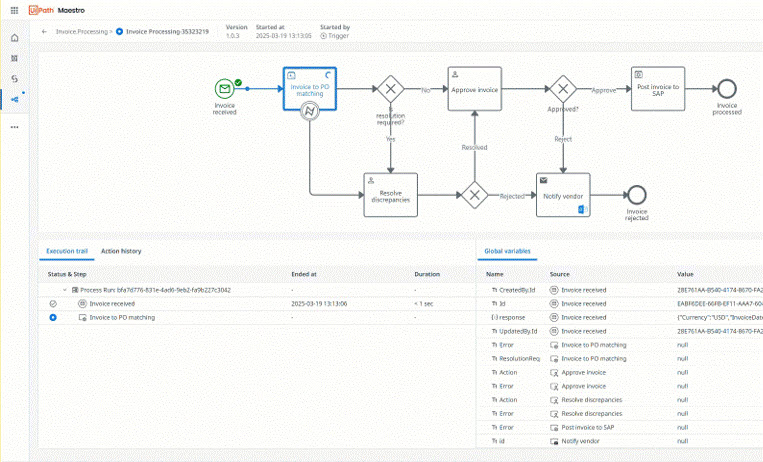
Maestro
在端到端流程中编排 AI 智能体、自动化和人员,以交付可衡量的结果
开始使用 UiPath
构建基本的端到端流程
在单个工作流中编排端到端业务流程
创建简单的 RPA 自动化
在 Studio 中创建您的第一个项目
构建您的第一个智能体
在 Studio Web 中构建您的第一个智能体
构建对话智能体
在 Studio Web 中使用我们的低代码设计器创建对话智能体
连接器
了解连接器如何提供对外部系统的安全、标准化访问
热门主题
配置防火墙
允许 Automation Cloud 所需的网络流量
安装 Studio
在计算机上安装 Studio
Studio 教程
逐步构建您的第一个自动化
数据驻留
选择 Automation Cloud 数据的存储位置
Studio Web 概述
在浏览器中创建和运行自动化
新增功能
Industry & Department Solutions now available
Agentic solutions for your industry
New deployment channels for conversational agents
Deploy conversational agents to Microsoft Teams and Slack
Integration Service connections in Orchestrator
Integration Service connections are now available in Orchestrator
Trainable splitter in Document Understanding
Split and classify multi-document packets using a trainable ML model
New agentic capabilities in Automation Suite
Agents, Maestro, and MCP Servers now available in Automation Suite