- Überblick
- Erste Schritte
- Erstellen von Modellen
- Verbrauchen von Modellen
- Modelldetails
- Öffentliche Endpunkte für Automation Cloud und Test Cloud
- Öffentliche Endpunkte für Automation Cloud und Test Cloud – Öffentlicher Sektor
- 1040 – Dokumententyp
- 1040 Formular C – Dokumententyp
- 1040 Formular D – Dokumententyp
- 1040 Formular E – Dokumententyp
- 1040x – Dokumententyp
- 3949a – Dokumententyp
- 4506T – Dokumententyp
- 709 – Dokumententyp
- 941x – Dokumententyp
- 9465 – Dokumententyp
- ACORD125 – Dokumententyp
- ACORD126 – Dokumententyp
- ACORD131 – Dokumententyp
- ACORD140 – Dokumententyp
- ACORD25 – Dokumententyp
- Kontoauszüge – Dokumententyp
- Frachtbrief – Dokumententyp
- Gründungsurkunde – Dokumententyp
- Ursprungszeugnis – Dokumententyp
- Überprüfungen – Dokumententyp
- Children Product Certificate – Dokumententyp
- CMS 1500 – Dokumententyp
- EU-Konformitätserklärung – Dokumententyp
- Finanzberichte – Dokumententyp
- FM1003 – Dokumententyp
- I9 – Dokumententyp
- Ausweise – Dokumententyp
- Rechnungen – Dokumententyp
- Rechnungen2 – Dokumententyp
- Rechnungen Australien – Dokumententyp
- Rechnungen China – Dokumententyp
- Rechnungen Hebräisch – Dokumententyp
- Rechnungen Indien – Dokumententyp
- Rechnungen Japan – Dokumententyp
- Rechnungen Versand – Dokumententyp
- Packlisten – Dokumententyp
- Gehaltsabrechnungen – Dokumententyp
- Reisepässe – Dokumententyp
- Bestellungen – Dokumententyp
- Zahlungsbelege – Dokumententyp
- Belege2 – Dokumententyp
- Zahlungsbelege Japan – Dokumententyp
- Zahlungsavis – Dokumententyp
- UB04 – Dokumententyp
- Angaben zum Abschluss von Hypotheken in den USA – Dokumententyp
- Betriebskostenabrechnungen – Dokumententyp
- Fahrzeugbrief – Dokumententyp
- W2 – Dokumententyp
- W9 – Dokumententyp
- Unterstützte Sprachen
- Insights-Dashboards
- Daten und Sicherheit
- Protokollierung
- Lizenzierung
- Anleitungen zu …
- Fehlersuche und ‑behebung

Document Understanding-Benutzerhandbuch.
UiPath® Helix Extractor 1.0
Das Helix Extractor 1.0 Large Language Model (LLM) ist unsere neueste Datenextraktionsmodelltechnologie, die entwickelt wurde, um Modelle der aktuellen Generation zu ersetzen, die in UiPath® Document UnderstandingTM verwendet werden. Während Helix Extractor 1.0 ähnlich wie frühere Modelle funktioniert, wurde er mit einer Vielzahl von Dokumenten trainiert. Dadurch kann er gängige Dokumenttypen mit wenig oder gar keinem Schulungsaufwand verarbeiten. Helix Extractor 1.0 LLM zeichnet sich durch seine generative Architektur aus, die die Genauigkeit erheblich verbessert und die Extraktion vereinfacht. Darüber hinaus können Sie das Modell mit Ihren eindeutigen Datasets feinabstimmen.
Weitere Informationen zur Helix Extractor 1.0-Architektur und den für das Training verwendeten Techniken finden Sie auf der Seite Helix Extractor 1.0 in unserem KI-Blog.
Verfügbarkeit
Derzeit ist der UiPath Helix Extractor in modernen Document Understanding-Projekten nur für Mandanten mit Sitz in den USA (ausgenommen GxP und Government Cloud) verfügbar.
Der UiPath Helix Extractor ist sowohl für klassische als auch für moderne Projekte verfügbar, wenn öffentliche Endpunkte in den folgenden Regionen verwendet werden:
- Öffentliche Endpunkte für Extraktionsmodelle in Europa basieren auf dem Helix Extractor, mit Ausnahme von Finanzberichten.
- Die folgenden öffentlichen Endpunkte für Extraktionsmodelle basieren auf dem Helix Extractor in der Region Japan:
- Rechnungen China
- Rechnungen Japan
- Receipts Japan
Verbesserungen gegenüber der vorherigen Generation
Das Helix Extractor LLM bietet zahlreiche Verbesserungen gegenüber vorherigen Modellen.Es verbessert die Genauigkeit, insbesondere bei Tabellen, passt sich an verschiedene Dokumentlayouts an, um den Anmerkungsaufwand zu reduzieren, und erhöht die Automatisierungsraten.
Zu den wichtigsten Verbesserungen gehören:
- Verbesserte Genauigkeit: Das Helix Extractor LLM bietet eine höhere Genauigkeitsrate und eine bessere F1-Punktzahl für halbstrukturierte Dokumente wie Rechnungen, Belege und Bestellungen. Dies gewährleistet eine präzise und konsistente Datenextraktion.
- Mühelose Anmerkung: Das Modell reduziert die manuelle Arbeit, da nur eine Anmerkung pro Dokument erforderlich ist, sodass nicht jede Feldinstanz auf jeder Seite mit Anmerkungen versehen werden muss.
- Verbesserte Automatisierung: Mit einer größeren Korrelation zwischen Konfidenzniveau und Genauigkeit verbessert das Helix Extractor LLM die Automatisierungsraten und reduziert gleichzeitig die Anzahl der Dokumente, die für die gleiche Genauigkeit an das Action Center gesendet werden.
In unseren internen Tests hat der Helix Extractor seinen Vorgänger in der Leistung übertroffen. Die False-Positive-Rate wurde um etwa 15 % reduziert, und die False-Negative-Rate sank um nahezu 17 %.
So verwenden Sie den Helix Extractor
Das Helix Extractor LLM ist exklusiv für moderne Document Understanding-Projekte verfügbar.Trotz der Einführung des Helix Extractor verwenden alle bestehenden Projektversionen weiterhin die aktuellen Modellversionen. Dadurch wird ein nahtloser Übergang ohne Unterbrechung der laufenden Produktionsworkflows sichergestellt.
Um mit dem Trainieren eines vorhandenen Dokumenttyps im Helix Extractor zu beginnen, heben Sie in einigen Dokumenten die Bestätigung aller Felder auf und bestätigen Sie sie erneut.
-
Wählen Sie den Dokumenttyp aus, den Sie im Helix Extractor trainieren möchten.
-
Wählen Sie ein Dokument aus.
-
Wählen Sie alle Felder aus dem Dokument aus und wählen Sie Löschen.
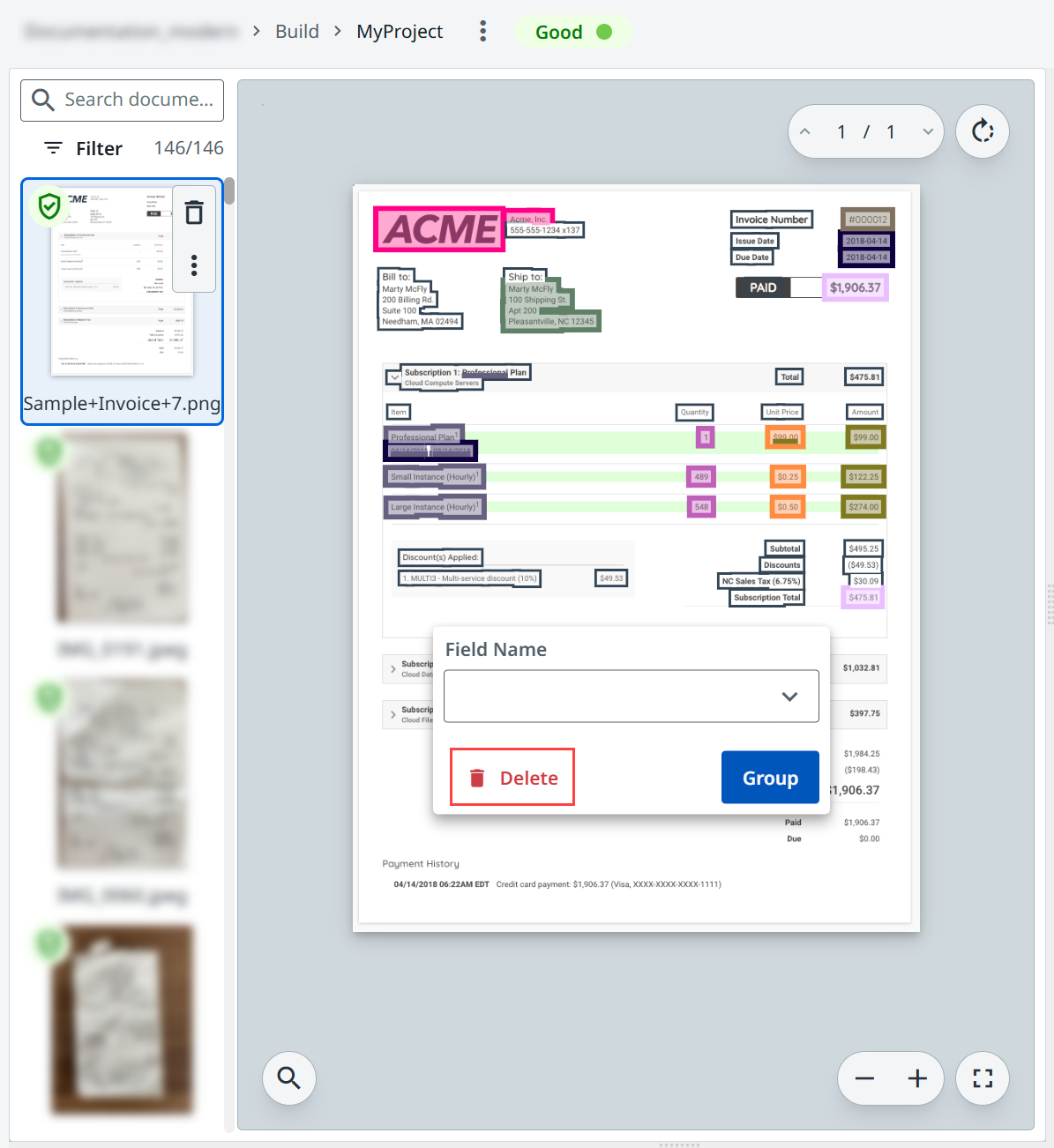
-
Versehen Sie alle Felder aus dem Dokument mit Anmerkungen und wählen Sie Bestätigen aus.
Hinweis:Wiederholen Sie die Schritte 3 und 4 , bis das Training für den gewählten Dokumenttyp initiiert wird.
So überprüfen Sie, ob der Helix Extractor aktiviert ist
Überprüfen Sie nach dem Trainieren Ihrer Modelle im Helix Extractor die Modellversion, um sicherzustellen, dass der Helix Extractor aktiviert ist.
-
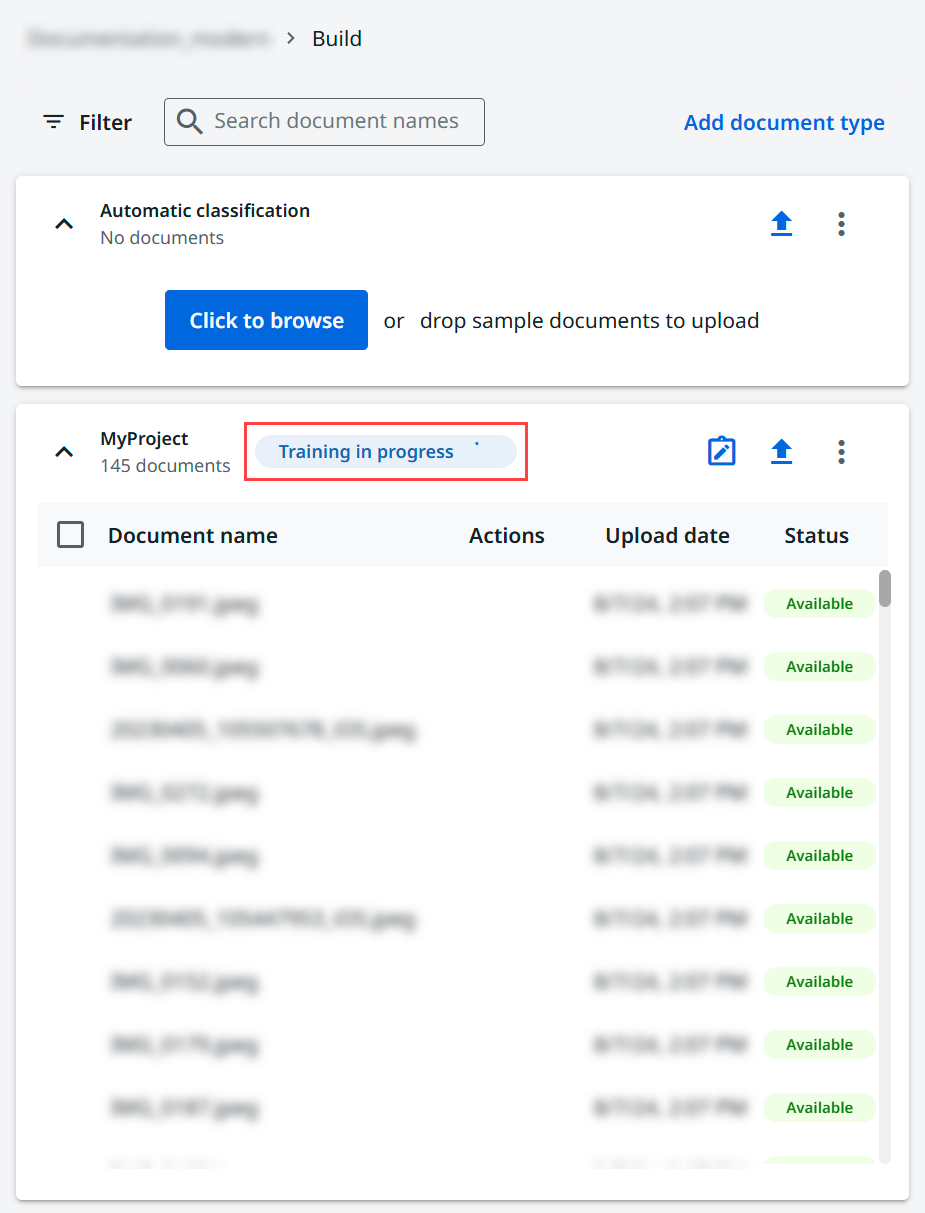
Gehen Sie zur Seite Veröffentlichen und erstellen Sie eine neue Projektversion.
-
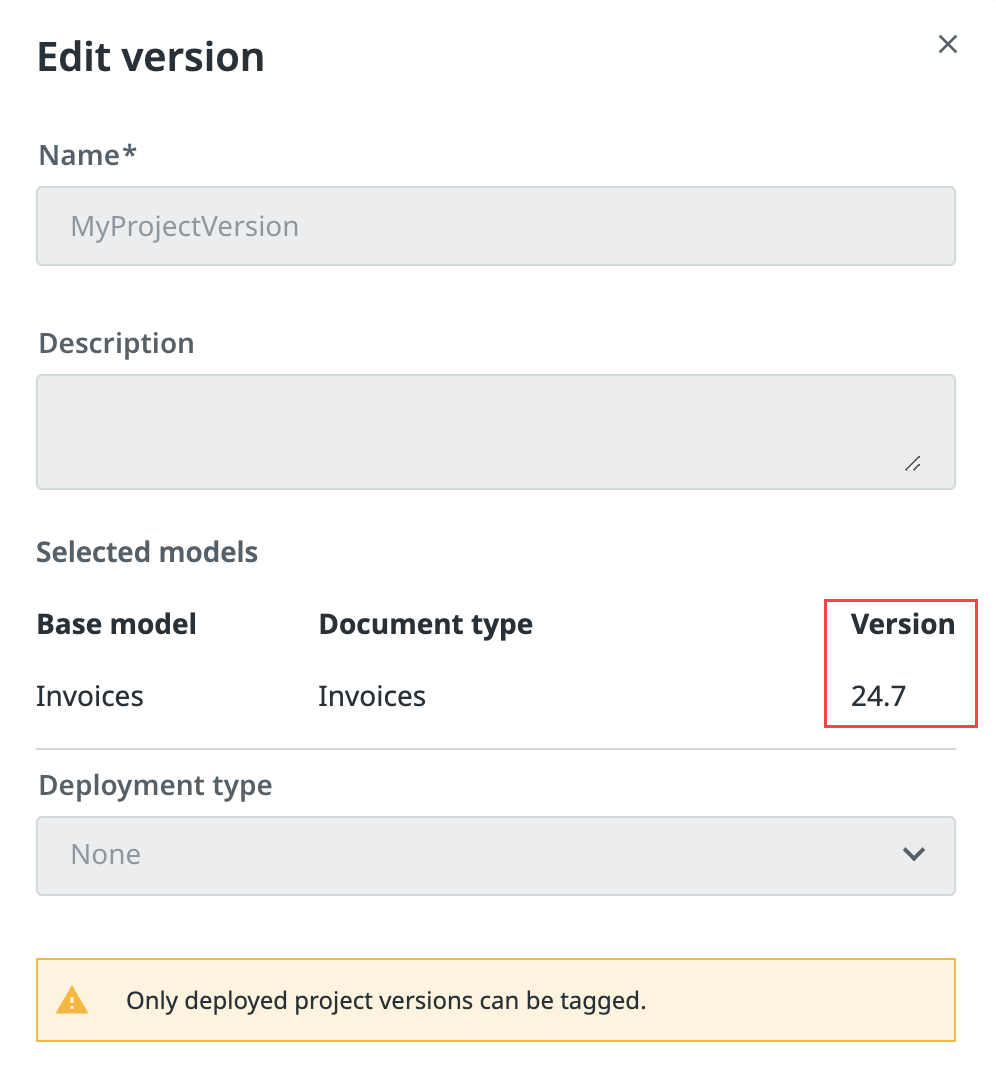
Wählen Sie das Drei-Punkte-Symbol ⋮ neben der Projektversion und Version bearbeiten aus, um die Modellversion zu überprüfen.
Hinweis:Alle Modelle, Version 24.7 und höher, sind UiPath Helix Extractor Modelle.
Optimieren der Ergebnisse
Die von Ihnen gewählten Feldnamen können sich erheblich auf die Leistung des Modells auswirken. Um optimale Ergebnisse sicherzustellen, verwenden Sie natürliche Sprache und die richtige Grammatik für Feldnamen. Sie sollten nur allgemein akzeptierte Akronyme wie Number (No), Account (Acct), Address (Addr) und Suite (Apt) verwenden. Derzeit werden nur westeuropäische Sprachen unterstützt. Stellen Sie daher sicher, dass die ausgewählten Feldnamen mit diesen Sprachen übereinstimmen. Verwenden Sie keine nicht beschreibenden Namen wie „Spalte 3“, es sei denn, das Dokument verwendet diese Terminologie ausdrücklich.
Auswahl zwischen dem Helix Extractor und dem Legacy-Modelltyp
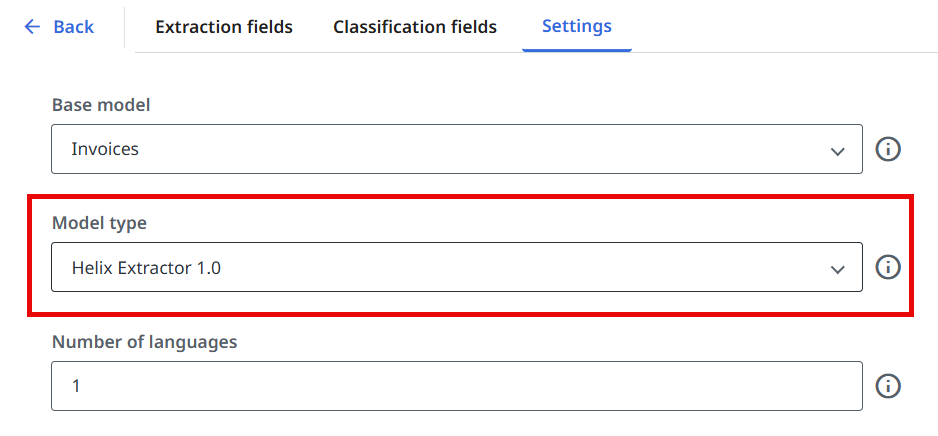
Der UiPath Helix Extractor unterstützt derzeit nur lateinische Skriptsprachen. Wenn Sie ein Modell in anderen als lateinischen Skriptsprachen trainieren müssen, wählen Sie den Legacy-Modelltyp. Wenn das Legacy-Modell ausgewählt ist, wählen Sie das entsprechende Basismodell für Ihren Dokumententyp.
Um zwischen dem Helix Extractor- oder dem Legacy-Modelltyp zu wählen, navigieren Sie zur Registerkarte Einstellungen im Document Type Manager und wählen Sie den benötigten Modelltyp aus der Dropdownliste Modelltyp aus.
Es ist erforderlich, eine neue Projektversion zu veröffentlichen, nachdem die Änderungen bereitgestellt wurden.
Bekannte Einschränkungen von UiPath® Helix Extractor
Die folgenden Einschränkungen gelten derzeit für UiPath Helix Extractor:
- Die extrahierten Felder müssen genau mit dem Text in den Dokumenten übereinstimmen. Dieser Prozess beinhaltet keine Zusammenfassung oder andere Arten der Textanalyse.
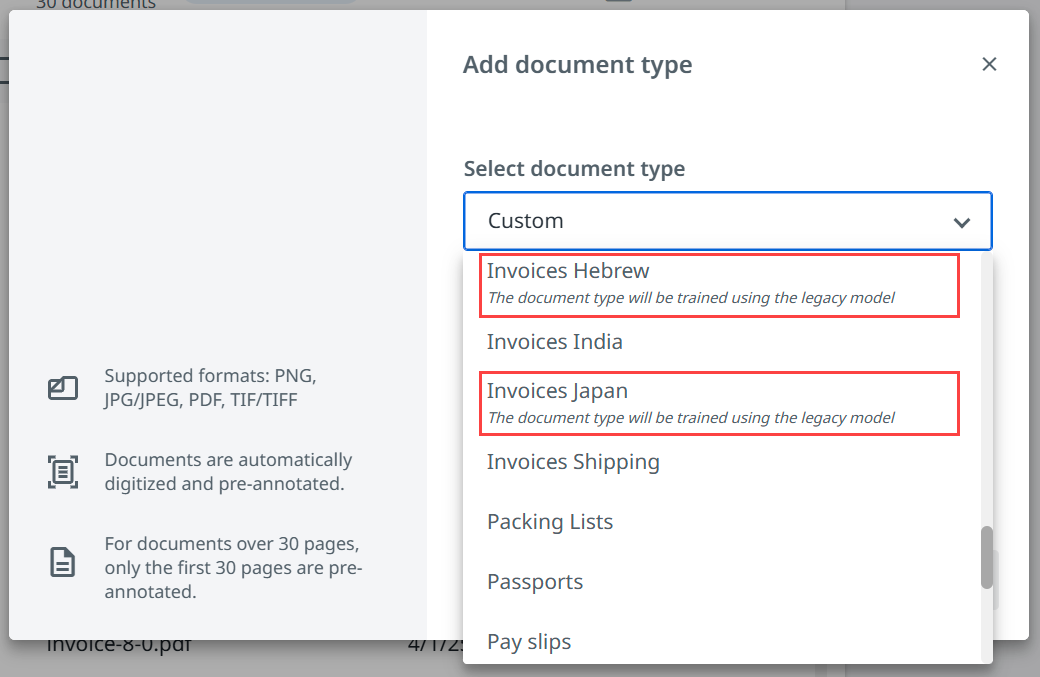
- Die folgenden Dokumenttypen basieren derzeit nicht auf dem Helix Extractor und arbeiten weiterhin mit der vorherigen Generation:
- Financial Statements
- Rechnungen China
- Rechnungen Hebräisch
- Rechnungen Japan
Bei Dokumenttypen, die derzeit nicht vom Helix Extractor-Modell unterstützt werden, wird die folgende Meldung in der Dropdownliste Dokumenttyp hinzufügen angezeigt: Der Dokumenttyp wird mit dem Legacy-Modell trainiert.
Der UiPath Helix Extractor unterstützt derzeit keine nicht-lateinischen Skriptsprachen.