Saiba mais sobre automação por agentes e orquestração com UiPath
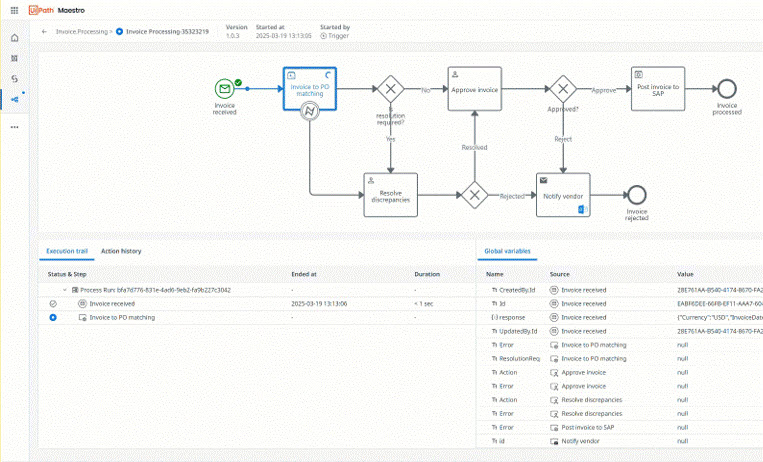
Maestro
Coordene agentes de IA, automações e pessoas em processos completos para fornecer resultados mensuráveis
Dê os primeiros passos com a UiPath
Orquestrar um processo de negócios de ponta a ponta em um único fluxo de trabalho
Crie seu primeiro projeto no Studio
Crie seu primeiro agente no Studio Web
Crie agentes de conversa usando nosso designer de pouco código no Studio Web
Saiba como os conectores fornecem acesso seguro e padronizado a sistemas externos
Tópicos populares
Permita o tráfego de rede necessário para o Automation Cloud
Instale o Studio em sua máquina
Crie suas primeiras automações passo a passo
Escolha onde seus dados do Automation Cloud são armazenados
Crie e execute automações em um navegador
Novidades
Agentic solutions for your industry
Deploy conversational agents to Microsoft Teams and Slack
Integration Service connections are now available in Orchestrator
Split and classify multi-document packets using a trainable ML model
Agents, Maestro, and MCP Servers now available in Automation Suite