- Before you begin
- Getting started
- Integrations
- Working with process apps
- Working with dashboards and charts
- Working with process graphs
- Working with Discover process models and Import BPMN models
- Showing or hiding the menu
- Context information
- Export
- Filters
- Sending automation ideas to UiPath® Automation Hub
- Tags
- Due dates
- Compare
- Conformance checking
- Root cause analysis
- Simulating automation potential
- Triggering an automation from a process app
- Viewing Process data
- Creating apps
- Loading data
- Transforming data
- Customizing dashboards
- Publishing Dashboards
- App templates
- Notifications
- Additional resources
In the Process Mining portal, you can easily create new apps. When you select the Create new app button, a wizard opens that guides you through the process of creating a new app step-by-step. When you leave Create new app wizard at any step, the current state is saved. You can continue creating the app with the state you left the wizard before.
To upload data for a process app**,** you need to have consumption units on your account. Refer to Enabling the Process Mining service for more information on AI Units.
Scenarios
Creating a Process app
- Create new app
- Select app template
- Define the app properties
- Select the data source
- Select the process mining type
- Finish the app creation
Creating a new app
- In the Process Mining portal, go to the Development tab, and select Create new app.
Note:
If this is your first app, you can select Create new app on the Welcome to Process Mining page. You will be re-directed to the Development tab.
A wizard starts and the Select app template step is displayed, where you can select an app template to be used for your app.
Selecting the app template
You can choose to use an existing app template as a starting point for a new app.
Refer to App templates for an overview of the available app templates.
- Select the Create app button on the tile representing the application template you want to use as a base for your new app.
Tip:
You can start entering the name of the app template in the Search field to filter for specific app templates and find the app template more easily.
The Basic details step is displayed with the default information from the process app type you selected.
Defining the app properties
-
Edit the name to define a unique name for the new process app in the App name field.
Note:If an app with the name you enter already exists for your tenant a message is displayed, and the Save and Next button is disabled.
-
If desired, edit the description in the Description field.
-
Select Next.
Note:It can happen that you enter a name for an app that already exists but that you do not see in the All process apps list. In this case, it can be an app for which you do not have View permission.
The Data source step is displayed.
Selecting the data source
You can use a sample dataset, upload a dataset with .csv files, or load data using an extractor. The data is loaded after you have created the new process app.
For performance and security reasons, it is strongly recommended to use a small dataset for app development and testing data transformations. The development dataset is used for testing the data transformations. It does not affect the data displayed in the dashboards of the published process app. Once your app is ready to be used by business users, you can publish the app and load new data for use in the published process app.
- Select the applicable option for your data source.
- Select Next.
Use Theobald extractor
Use Theobald extractor is the recommended option for process apps that use an SAP source system.
If you selected an app template that uses an SAP source system, the Use Theobald extractor option is the default option for loading data.
You can copy the details for use in the extractor in the Upload data using Theobald step later in the app creation process. Refer to Finishing the app creation.
Refer to Loading data using Theobald Xtract Universal for more information.
Use CData extractor
The Use CData extractor option is the default option for app templates that use a source system that is supported by CData.
You can copy the details for use in the extractor in the Upload data using CData step later in the app creation process. See Finishing the app creation.
Refer to Loading data using CData Sync for more information.
Use sample data
The Use sample data option is only enabled if sample data is available for the process app.
Upload a dataset
It is also possible to upload a dataset using .csv files.
For large amounts of data, it is recommended to use CData Sync or Theobald Xtract Universal (for SAP) to upload data.
When you create a new process app, always make sure that the data is in the required format for the app template that you use to create a new app. Check out App Templates.
Table names and field names are case-sensitive. Always make sure that the field names (column headers) in your dataset match the field names listed in the input tables and that the file names match the table names.
Make sure the .csv files have the suffix _raw.
Follow these steps to upload data files.
- Drag and drop one or more files that contain the data for the process app, or select
 to select the files from your computer.
to select the files from your computer. - Check the detected details for your dataset for Encoding, Delimiter, and Quote character. If needed, select the appropriate settings.
Upload data using extractor
You can copy the details for use in the extractor in the Upload data using extractor step later in the app creation process. Refer to Finishing the app creation.
Selecting the process mining type
You can select the process mining type for the process model to be used for the app.
Discover process model and Import BPMN model introduce detailed semantic events for exclusive, parallel, and loop behaviors that enhance process precision but may affect app scalability. As a result, this might impact the maximum number of real events supported in a Process mining app.
- Select the process mining type for your process app.
- Select Next.
Directly follows graph
Directly follows process models (adjacency graphs) focus on simplicity and readability, showing a clear and direct representation of the event log. These process models are intuitive and easy to understand, making them valuable for easily understanding the basic flow of activities. While they may not capture all the complex behaviors in the process, such as parallelism, Directly follows process models provide a useful starting point for process analysis.
The Directly follows relationship represents the order in which activities occur in a process. It is based on event logs that contain records of activities performed during the execution of a process. By analyzing the event logs, Process Mining techniques can identify which activities are typically executed one after another. Between these two activities, an edge is defined as A➝B.
If, for example, paths A→B and C→D in a process can be performed in parallel, the activities of the two paths can occur in the event log in any order. In the "directly follows graph" approach, these events will not be considered to run in parallel, and the resulting process flow can be the following: A➝C➝B➝D.
A Discover process model or a BPMN process model however will take parallel structures into account.
Discover process model
Discovering a process model allows you to have a better understanding of your process structure. By analyzing the whole process (the whole event log) with advanced process mining techniques, activities that happen in parallel, are part of a decision, or are part of a more complex loop are automatically discovered. These relationships are called the process semantics.
The following table describes the process semantic types used in discover process models.
| Semantic node type | Description | Visual representation |
| Parallel gateway (AND) | Represents two or more branches that happen in parallel. | |
| Exclusive choice gateway (XOR) | Represents an exclusive choice (decision point) between two or more branches. | |
| Loop gateway | Represents a repeatable sub-process with one loop body path and one or more rework paths. |
Import BPMN model
Select Import BPMN model if you want to import your own BPMN 2.0 model and use it as a process mining type for your process app.
With the BPMN model, advanced process algorithms will map your event log data on top of the BPMN model, allowing you to analyze how the BPMN model and your data relate.
-
Drag and drop the
.bpmnfile that contains the BPMN 2.0 model you want to import.
When the file is successfully imported, the Next button will be enabled.
If you want to use a different BPMN model after you created the process app, you can import a BPMN model in Process manager.
BPMN model requirements
The following sections describe the requirements to successfully import a BPMN 2.0 model for use in Process Mining.
General requirements for the BPMN model
- The BPMN must adhere to the BPMN 2.0 standard.
- The BPMN must contain a single process definition.
- The BPMN can only contain supported elements.
- All nodes in the BPMN should have an id.
- The BPMN model should contain no more than 999 nodes.
Supported BPMN elements
The following BPMN elements ares supported:
- Start events
- End events
- Tasks
- Exclusive choice gateways
- Parallel gateways
- Sequence flows
Task and flow requirements
| Requirement | Example |
| A start event must be defined, and there can only be one start event. | |
| An end event must be defined, and there can only be one end event. | |
| At least one activity task must be defined. | |
| There must be at least two sequence flows defined for the BMPM model. | |
| The tasks must have unique labels. | |
| All sequence flows must have a source and a target. | |
| Each task must have a single incoming, and a single outgoing sequence flow. | |
| The start event only has a single outgoing edge. | |
| The end event only has a single incoming edge. | |
| All nodes and sequence flows in the BPMN are connected in a single model. |
Gateway requirements
The gateways in the BPMN must form pairs. Each pair has an opening gateway, which splits the process flow into multiple process flows. Each pair has a closing gateway, which joins the split process flows into a single flow. This structure is called a block. The flows inside a block may contain other, nested blocks. However, the only flows to enter and exit the flows within a block, are via the split and join gateways.
The following illustration shows an example of a BPMN model with gateway pairs, forming blocks. The blocks are highlighted.
| Requirement | Example |
| Each gateway is either a split or a join gateway. | |
| A split gateway has a single incoming edge, and at least 2 outgoing edges. | 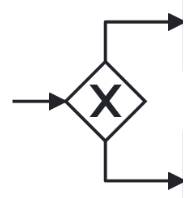 |
| A join gateway has at least 2 incoming edges, and a single outgoing edge. | 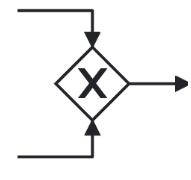 |
| For every split gateway, there is a corresponding join gateway of the same type, and vice versa. | |
| Every split-join gateway pair and the elements between them are a single-entry-single-exit component: a model component that has only a single entry edge and a single exit edge. | |
| Each path from a split gateway its corresponding join gateway must also be a single-entry-single-exit. | |
| There cannot be any direct sequence flows between corresponding splitting and joining parallel gateways. | |
| Every exclusive choice split-join gateway pair that describes a loop flow to a previous point in the process cannot have an empty main path and an empty redo path, as this allows for indefinite looping without a task being executed. |
Finishing the app creation
Process apps
When you are creating a process app, follow these steps to finish the app creation.
- Review the app details.
- Select Submit.
The process app is created and will be displayed in the Process apps in development list. A progress bar is displayed to indicate the progress of the data run of your process app.
When the data run is completed, the new app will be published and displayed in the Process apps in development list.
You can now customize the app and edit the transformations to your needs. Check out Customizing dashboards.
The app is in development mode and only available in the development environment. To make the app available to business users, you must publish the app. Check out Publishing Dashboards.
Upload data using extractor
If you have selected the Upload data using extractor option in the Selecting the data source step, the Upload data using extractor step is displayed.
End of upload API
When loading data using an extractor, you use the End of upload API in the post-event of in the extraction job to signal that the extraction was finished. See Create a job.
- Copy the End of upload API and save it, for example, in a Notepad file.
- Select Finish.
Upload data using CData Sync
If you have selected the Use CData extractor option in the Selecting the data source step, the Upload data using CData step is displayed.
- Copy the details for creating a destination connection from CDdata Sync and save them, for example, in a TXT file.
- Copy the End of upload API and save it, for example, in a TXT file.
- Select Finish.
- Follow the steps described in Loading data using CData Sync and use the above details to set up CData Sync.
Upload data using Theobald Xtract Universal
If you have selected the Use Theobald extractor option in the Selecting the data source step, the Upload data using Theobald step is displayed.
- Download the configuration files from Theobald.
- Copy the details for the Shared access signature from Theobald and save them, for example, in a Notepad file.
- Copy the End of upload API and save it, for example, in a Notepad file.
- Select Finish.
- Follow the steps described in Loading data using Theobald Xtract Universal and use the above details to set up Theobald Xtract Universal.
- Scenarios
- Creating a Process app
- Creating a new app
- Selecting the app template
- Defining the app properties
- Selecting the data source
- Use Theobald extractor
- Use CData extractor
- Use sample data
- Upload a dataset
- Upload data using extractor
- Selecting the process mining type
- Directly follows graph
- Discover process model
- Import BPMN model
- BPMN model requirements
- Finishing the app creation
- Process apps