- Démarrage
- Paramétrage et configuration
- Unassisted Task Mining
- Ressources supplémentaires
- Guide d'analyse Unassisted Task Mining
- Résolution des problèmes
- Glossaire
- FAQ
Introduction
Ce guide sert d'introduction à l'utilisation des résultats d'analyse Unassisted Task Mining une fois qu'un projet est créé, que l'enregistrement des actions est terminé et qu'une analyse est exécutée. Il est destiné aux analystes métier, aux administrateurs de projet et à tous ceux qui souhaitent apprendre à interpréter les résultats de Unassisted Task Mining et à identifier les tâches présentant un potentiel d'optimisation. Ce guide fournit également des conseils sur la gestion des résultats inattendus et du bruit généré par l'analyse.
Pour générer des résultats, l'algorithme d'IA recherche les occurrences de la même séquence d'étapes dans les données enregistrées. Il fonctionne sans contexte et peut donc présenter des candidats à la tâche qui ne capturent pas entièrement les tâches réelles du début à la fin.
Parfois, les résultats de l’analyse peuvent inclure des tâches et des étapes non pertinentes d’un point de vue commercial. Ceci est considéré comme du bruit. Pour identifier les candidats à l'automatisation, il est important que le réviseur fasse la différence entre les tâches de haute qualité et le bruit.
Différents types de résultats Task Mining
Les tâches candidates identifiées par l'algorithme d'IA peuvent s'aligner sur des tâches réelles, mais elles peuvent également différer de ce qui est attendu. Toutes les tâches candidates ne se prêtent pas à l’automatisation, et le réviseur doit être familiarisé avec les différents types de résultats qu’ils peuvent rencontrer. Les candidats à la tâche identifiés peuvent :
- Ne pas afficher les tâches attendues
- Afficher les tâches inattendues
- Diviser une tâche réelle en plusieurs tâches
- Capturez partiellement une tâche sans le début et la fin réels
- Ne pas afficher une tâche réaliste
1. Les résultats n'affichent pas les tâches attendues
Unassisted Task Mining applique un algorithme pour identifier les tâches candidates, qui peuvent être de bons candidats à l'automatisation ou à l'optimisation des processus. Il n'est pas garanti que l'algorithme d'IA détecte tout, et il peut détecter un processus partiel ou même un processus plus volumineux que prévu. En suivant les étapes fournies dans ce document, le réviseur peut déterminer si les tâches candidates identifiées sont appropriées pour l'automatisation. Étant donné qu' Il n'est pas garanti qu'Unassisted Task Mining détecte les tâches connues ou qu'il sélectionne chaque variation ou itération, il ne doit pas être utilisé uniquement pour surveiller les tâches connues.
2. Les résultats affichent des tâches inattendues
Unassited Task Mining identifie les tâches candidates qui sont ensuite classées en fonction de leur probabilité de constituer de meilleures opportunités d’automatisation. Certains résultats peuvent ne pas être représentatifs d’une tâche réelle, mais le réviseur peut toujours les identifier comme de bons candidats à l’automatisation en fonction des étapes présentées dans ce document.
3. Les résultats divisent les tâches réelles en plusieurs tâches candidates Task Mining
L’algorithme Unassisted Task Mining recherche la séquence d’étapes cohérente et la plus fréquente. Selon la cohérence avec laquelle les utilisateurs ont exécuté la tâche, une tâche réelle peut être divisée en plusieurs tâches candidates dans les résultats. La fin d'une tâche candidate peut être le début de la suivante. La tâche candidate peut toujours convenir pour des actions d’automatisation ou d’amélioration des processus. Dans ce cas, nous vous recommandons de combiner ces sous-tâches dans le document de définition de processus (DDP) en exportant toutes les traces pertinentes vers Task Capture et en les combinant en un seul document. La combinaison des sous-tâches en effectuant un recalcul dans Task Mining peut ne pas produire des résultats optimaux si les sous-tâches partagent les étapes de début et de fin.
4. Les résultats capturent partiellement une tâche sans le début ou la fin réels
L'algorithme d'IA identifie les séquences d'étapes les plus cohérentes en tant que tâches candidates. Selon la variabilité des utilisateurs exécutant la tâche, le milieu d'une tâche peut être plus cohérent que le début et/ou la fin, ce qui oblige l'algorithme à détecter cette sous-tâche comme candidate au lieu de la tâche complète de bout en bout.
Cela est susceptible de se produire lorsque le début et/ou la fin d'une tâche implique des applications hautement multifonctionnelles telles qu'Outlook, Excel, etc. Ces applications sont probablement utilisées lors de plusieurs tâches, et il est difficile pour l'algorithme de distinguer leurs occurrences spécifiques comme le début ou la fin d'une tâche candidate. Dans ce cas, nous vous recommandons de vous concentrer sur l'essentiel des tâches, et de ne pas couvrir 100 % de tous les clics effectués par un utilisateur. Si la tâche est malgré tout un candidat approprié pour l'automatisation, le début et la fin manquants peuvent être ajoutés lors de la construction de l'automatisation.
5. Les résultats montrent une tâche irréaliste
La tâche candidate découverte peut ne pas sembler réaliste ou ne pas être une tâche reconnaissable. Si une tâche candidate n’a pas de sens d’un point de vue métier, c’est probablement du bruit et peut être ignoré.
Hiérarchisation des tâches candidates pour l'analyse
Selon les données enregistrées, l'algorithme Task Mining peut identifier de nombreux candidats de tâches. Par conséquent, il est important que le réviseur priorise les candidats à analyser en premier pour ne pas perdre de temps sur des tâches candidates qui ne sont probablement pas des candidats appropriés pour l'automatisation. La page Résultats de la découverte (Discovery Results) et ses ICP fournissent des données pour cette hiérarchisation.
Les tâches candidates dans les résultats de la découverte sont triées en fonction de leur probabilité d'automatisation. Plus le candidat de la tâche est élevé dans la liste, plus il est probable qu'il s'agisse d'un bon candidat d'automatisation. Le candidat à la tâche avec le nom « Tâche 0 » a été identifié comme le meilleur candidat à l'automatisation par l'algorithme Unassisted Task Mining, en tenant compte de divers facteurs, notamment la répétabilité et la complexité. Cependant, ce classement n’indique pas la qualité globale des résultats de Task Mining, mais le classement « Tâche 0 » est plus susceptible d’être supérieur à la « Tâche 10 ».
Le réviseur peut également modifier le tri standard en cliquant sur les en-têtes de colonne. Les trois options de tri disponibles pour la colonne Nom de la tâche vont du potentiel d'automatisation le plus élevé au plus faible, du potentiel d'automatisation le plus faible au plus élevé et sont classées par ordre alphabétique du nom de la tâche.
Utilisez le bouton Tâches importantes uniquement pour filtrer afin d'afficher uniquement les tâches ayant au moins 5 actions, 3 étapes et 30 secondes d'exécution. Cela devrait réduire le bruit provenant des résultats.
![]()
Concentrez-vous sur des groupes de tâches plus importants. Les candidats de tâche qui sont regroupés sont souvent des candidats de tâche plus significatifs. Recherchez la meilleure tâche représentative au sein d’un groupe de tâches. Lors de l’analyse d’un candidat de tâche qui est le représentant du groupe, il peut se produire que ce candidat de tâche ait un potentiel d’automatisation élevé, mais la tâche de bout en bout ne soit pas entièrement correcte. Dans ce cas, nous vous recommandons de vérifier les tâches alternatives candidates du groupe pour obtenir une meilleure représentation. Une fois que le réviseur a trouvé un meilleur représentant, il peut le sélectionner et le marquer comme nouveau représentant pour ce groupe de tâches.
Au sein d'un groupe de tâches, concentrez-vous sur les tâches les mieux classées. En règle générale, les alternatives de tâches les mieux classées au sein d'un groupe sont de qualité supérieure. Les alternatives de tâches classées après 10 ou 20 sont généralement de qualité médiocre.
Lors de l'analyse des tâches alternatives candidates, il peut apparaître clairement que certaines d'entre elles sont liées à une tâche différente de la tâche représentative. Dans ce cas, le réviseur peut créer un nouveau groupe de tâches basé sur ces tâches alternatives.
Examiner les métriques des différents candidats à la tâche. Chaque candidat à la tâche affiche différentes mesures, telles que le temps total passé par les utilisateurs sur cette tâche, le nombre d'utilisateurs ayant effectué cette tâche, le nombre d'étapes dans la tâche la plus représentative, etc. Tenez compte de ces mesures dans votre analyse et appliquez vos propres critères en fonction du contexte métier de votre projet Task Mining. Par exemple, nous pouvons voir que la tâche 7 a un temps total, un nombre de traces et d'étapes beaucoup plus faible par rapport à la tâche 1 et au groupe de tâches Nouveau. Cela peut indiquer que la tâche 7 a un potentiel d'automatisation inférieur. Cependant, veuillez noter qu'il n'existe aucune instruction globale concernant le temps total, grand ou petit, qui s’applique à l’ensemble des études Task Mining. Ces mesures doivent toujours être interprétées dans le contexte métier du projet Task Mining spécifique.
Utilisez la fonctionnalité de signet et de changement de nom. Lors de la hiérarchisation des différentes tâches candidates à une analyse plus approfondie, il est important de garder un aperçu de ce qui a été prioritairement, voire déjà analysé. La mise en signet et le changement de nom des tâches candidates peuvent aider à structurer l’analyse.
Analyse des tâches individuelles
Une fois que le réviseur a hiérarchisé les différentes tâches candidates, votre analyse peut commencer. Pour guider le réviseur, la section suivante fournit d’abord quelques informations à garder à l’esprit pendant l’analyse, puis fournit un guide étape par étape sur la façon de naviguer dans la vue d’analyse.
À garder à l'esprit pendant l'analyse
Les étapes sont basées sur des écrans. Le candidat de la tâche et ses étapes s'affichent au niveau d'une interface/d'un écran utilisateur unique et ne représentent pas d'actions de clic ou de saisie individuelles. Les actions de clic ou de saisie effectuées sur un même écran sont généralement regroupées par l'algorithme Task Mining. Par conséquent, le graphique n'affiche pas chaque action de clic ou de saisie individuelle.
Un candidat de tâche a besoin d’au moins deux étapes (écrans) pour être identifié comme tel. Pour que l'algorithme Task Mining identifie une tâche candidat, il doit comprendre une étape de début et de fin claires. Par conséquent, une tâche effectuée uniquement sur un seul écran ne sera pas identifiée comme un candidat de tâche.
Les étapes sont les mêmes pour l’ensemble des différentes tâches candidates. Les étapes ne sont pas liées à un candidat de tâche spécifique. Une étape qui se produit dans un candidat de tâche peut également se produire dans un autre. Cela signifie que les actions telles que le changement de nom d'une étape auront un effet sur l'ensemble du projet.
L’algorithme de masquage des PII peut marquer à tort ou ne pas marquer un élément comme PII. Le module PII est un algorithme d’IA qui peut détecter les informations personnelles. Il peut arriver que l'algorithme commet une erreur et que certaines informations personnelles ne soient pas masquées ou qu'un texte qui n'est pas un élément spécifique puisse être masqué. Ces erreurs dépendent du texte détecté à l'écran ainsi que du contexte des mots eux-mêmes. Si le texte n’est pas capturé par l’OCR ou est partiellement coupée, il est possible que le texte ne soit pas masqué. De plus, si les autres mots à l'écran sont différents, il est possible qu'un même texte soit identifié comme PII sur un écran et non sur l'autre.
Si un candidat de tâche n'a pas de sens visuel lors de l'examen des traçages, il ne s'agit probablement pas d'un candidat de tâche de haute qualité. L'algorithme peut détecter des tâches candidates bruyantes et non pertinentes, en particulier dans les classements inférieurs du classement des tâches. Ces tâches candidates peuvent être très courtes ou très longues et extrêmement variables. Une fois que cela devient clair après avoir examiné quelques traces, vous ne devez pas perdre votre temps à essayer de les interpréter.
Recherchez la majorité du processus (Règle 80/20). Les tâches candidates peuvent ne pas s’aligner entièrement sur les tâches réelles attendues, mais n’en couvrir que partiellement les sous-parts. Comme déjà mentionné ci-dessus, en fonction de la variabilité des utilisateurs exécutant la tâche, certaines étapes d'une tâche peuvent être plus cohérentes que d'autres, ce qui oblige l'algorithme à ne détecter que certaines étapes de la tâche comme candidat au lieu de la tâche complète de bout en bout.
La tâche candidate peut toujours convenir à l'automatisation, quelles que soient les étapes manquantes. Ceux-ci peuvent être ajoutés lors de la construction de l’automatisation.
Faites défiler les résultats. Les traçages d'un candidat à la tâche et les captures d'écran des étapes sont triés par ordre chronologique. Il est donc recommandé de faire défiler les listes pour examiner les résultats à plusieurs points.
Analyse étape par étape
Pour analyser de près les tâches candidates prioritaires, suivez les étapes ci-dessous. Cela aidera à différencier les candidats à l’automatisation des tâches bruyantes
- Analyser l'étape de début et de fin de la tâche candidate pour déterminer sa qualité
- Cliquez sur l'étape pour afficher les captures d'écran sur le côté droit de l'écran.
- Examinez les captures d’écran de l’étape de début et de fin du candidat pour comprendre ce qui se passe. Une étape de haute qualité est cohérente dans l'application utilisée et le travail effectué. Si les captures d'écran de l'étape de début ou de fin affichent de nombreux écrans et actions différents, ses traçages seront très incohérents. Cela indique que le candidat de la tâche n’est probablement pas un bon candidat pour l’automatisation.
- Les captures d'écran sont classées par ordre chronologique, il est donc recommandé de passer en revue les captures d'écran au début, au milieu et à la fin de la liste.
- Renommer les étapes, cela vous aide à garder un aperçu des étapes qui ont été révisées.
- Ouvrir et revoir les étapes clés du processus
-
Trouvez des étapes clés en ajustant le filtre d'occurrence d'étape en bas. Essayez d'équilibrer la variance et la compréhension. Pousser le curseur plus à gauche réduit généralement la complexité au détriment de l'exhaustivité. Pour faciliter la tâche, vous devez déplacer le curseur vers la gauche pour qu'il n'y ait que 2 à 3 étapes en plus de l'étape de début et de fin.
-
Filtrez pour des traçages de haute qualité. Le filtre pour les traçages de chemin les plus fréquents peut fournir la trace la plus utile, il est donc recommandé d’analyser d’abord ces traçages. Appliquez le filtre pour voir uniquement les traçages suivant ce chemin le plus fréquent. Ce filtre est disponible dans le panneau Filtre
-
Examinez les captures d’écran comme décrit dans l’analyse des étapes de début et de fin. Certaines étapes incohérentes et bruyantes sont acceptables, mais dans l’idéal, un candidat à une tâche ayant un potentiel d’automatisation élevé aura au moins quelques étapes de haute qualité au milieu du graphique qui font partie de la plupart des traces.
-
Renommez les étapes. Cela vous aide à garder un aperçu des étapes qui ont été révisées.
-
- Examiner les traçages
- Les traçages sont classés par ordre chronologique. Nous vous recommandons de passer en revue les traces au début de la liste, au milieu et vers la fin.
- Une tâche candidate de haute qualité contiendra de nombreuses traces qui se ressemblent. Recherchez les indicateurs suivants :
- Les traces ont des étapes similaires au milieu de la trace.
- Les traçages ont un sens du point de vue métier.
- Vérifiez les captures d'écran pour voir si les informations de traçage sur l'élément sur lequel est en cours d'exécution sont les mêmes dans chaque traçage, mais différentes entre les traçages (par exemple, l'ID du problème, le nom du client, le numéro de facture, etc.). Assurez-vous d'analyser cela au bon niveau, car un numéro de facture peut apparaître dans plusieurs traçages, mais chaque traçage couvre une ligne différente de la facture.
- Si vous déterminez lors de l’analyse des traces que le candidat de la tâche est de mauvaise qualité, il est recommandé de ne pas vous concentrer sur eux et de passer au candidat de tâche suivant dans votre liste de priorité.
- Filtrez les traçages de faible qualité. Même un candidat de tâche de haute qualité contiendra des traçages de faible qualité, où l'algorithme a fait une erreur. Ces traces seront souvent beaucoup plus longues ou beaucoup plus courtes que les autres et incluent du bruit ou des actions non pertinentes. Supprimez-les en appliquant les filtres situés à côté de la barre de recherche. Ajustez les filtres en fonction des histogrammes pour filtrer les traçages.
Souvent, les tracés de haute qualité forment une bosse plus grande dans l'histogramme. S'il y a de petits pics sur les bords, loin de la majeure partie de l'histogramme, nous vous recommandons d'utiliser les curseurs pour les supprimer et voir si cela améliore le graphique de la tâche et les traces. Les traces avec un nombre d'étapes et d'actions très faible ou très élevé ne sont probablement pas des tâches candidates appropriées.
Si vous souhaitez revenir à un paramètre de filtre spécifique à l’avenir, utilisez la fonctionnalité enregistrer les vues .
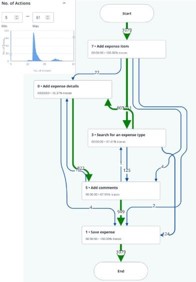
- Si l' étape souhaitée ne s'affiche pas dans le graphique, rendez-vous dans un traçage spécifique. Définissez l'occurrence sur 100 % et supprimez le filtre « Afficher uniquement les étapes clés ». Revenez ensuite à tous les traçages et filtrez l'étape souhaitée.
- Recalculer les étapes
- Une fois que vous avez sélectionné des traces de haute qualité et identifié les activités clés, nous vous recommandons de recalculer. Sélectionnez uniquement les étapes clés qui doivent être incluses dans la tâche candidate, omettez les étapes non pertinentes ou bruyantes et définissez l'ordre correct des étapes.
Notez que cela réduira également le nombre d’étapes disponibles pour le prochain recalcul. Par conséquent, il peut être plus difficile de restreindre les tâches candidates. L'option de recalcul comprend également un historique des versions qui vous permet de recharger une version précédente d'une tâche candidate si vous n'êtes pas satisfait du résultat d'un recalcul.
Renommer les étapes
Le changement de nom des étapes sert à deux fins. Premièrement, cela rend les étapes plus interprétables. Deuxièmement, il vous permet de faire la distinction entre la haute qualité et le bruit. Étant donné que les étapes peuvent se produire dans plusieurs tâches candidates, les renommer vous évitera de les revoir à nouveau dans la tâche candidate suivante. Quelques bonnes pratiques :
- Étape de haute qualité : renommer en Nom de l'application + verbe + nom. Il n'est pas possible de filtrer les applications, mais vous pouvez filtrer les noms d'étape. Lorsque plusieurs applications sont utilisées pour la tâche, cela facilite l'analyse.
- Étapes du bruit : renommer en bruit.