- Primeros pasos
- Instalación y configuración
- Task Mining sin asistencia
- Recursos adicionales
- Guía de análisis de Task Mining sin asistencia
- Solución de problemas
- Glosario
- Preguntas frecuentes
Introducción
Esta guía sirve como introducción al trabajo con los resultados del análisis de Unassisted Task Mining después de crear un proyecto, completar el registro de acciones y ejecutar un análisis. Está destinado a analistas empresariales, administradores de proyectos y otras personas que quieran aprender a interpretar los resultados de Unassisted Task Mining e identificar tareas con potencial de optimización. Esta guía también proporciona orientación sobre cómo manejar los resultados inesperados y el ruido del análisis.
Para generar resultados, el algoritmo de IA busca ocurrencias de la misma secuencia de pasos dentro de los datos registrados. Funciona sin ningún contexto y, por lo tanto, puede presentar candidatos a tareas que no capturan completamente las tareas de la vida real desde el principio hasta el final.
A veces, los resultados del análisis pueden incluir tareas y pasos que son irrelevantes desde una perspectiva empresarial. Esto se considera ruido. Para identificar los candidatos a la automatización, es importante que el revisor diferencie entre tareas de alta calidad y ruido.
Diferentes tipos de resultados de Task Mining
Los candidatos a tarea identificados por el algoritmo de IA pueden alinearse con tareas de la vida real, pero también pueden diferir de lo que se espera. No todos los candidatos a tarea son adecuados para la automatización y el revisor debe estar familiarizado con los diferentes tipos de resultados que puede encontrar. Los candidatos a tarea identificados pueden:
- No mostrar las tareas esperadas
- Mostrar tareas inesperadas
- Dividir una tarea de la vida real en varias
- Capturar parcialmente una tarea sin el inicio y el final reales
- No mostrar una tarea realista
1. Los resultados no muestran las tareas esperadas
Unassisted Task Mining aplica un algoritmo para identificar candidatos a tareas, que pueden ser buenos candidatos para la automatización o la optimización de procesos. No se garantiza que el algoritmo de IA lo detecte todo, y puede detectar un proceso parcial o incluso un proceso más grande de lo esperado. Siguiendo los pasos proporcionados en este documento, el revisor puede determinar si las tareas candidatas identificadas son adecuadas para la automatización. Dado que no se garantiza que Unassisted Task Mining detecte tareas conocidas o seleccione cada variación o iteración, no debe utilizarse únicamente para supervisar tareas conocidas.
2. Los resultados muestran tareas inesperadas
Task Mining sin asistencia identifica tareas candidatas que luego se clasifican según la probabilidad de que sean mejores oportunidades de automatización. Es posible que algunos resultados no sean representativos de ninguna tarea real, pero el revisor puede identificarlos como buenos candidatos para la automatización en función de los pasos presentados en este documento.
3. Los resultados dividen las tareas reales en varias tareas candidatas a Task Mining
El algoritmo de Task Mining sin asistencia busca la secuencia de pasos más frecuente y consistente. Dependiendo de la coherencia de los usuarios con la ejecución de la tarea, una tarea de la vida real puede dividirse en varias tareas candidatas en los resultados. El final de una tarea candidata puede ser el inicio de la siguiente. La tarea candidata aún puede ser adecuada para acciones de automatización o mejora de procesos. En ese caso, recomendamos combinar estas subtareas en el Process Definition Document (PDD) exportando todos los seguimientos relevantes a Task Capture y combinándolos en un solo documento. Combinar las subtareas volviendo a calcular en Task Mining puede no producir resultados óptimos si las subtareas comparten los pasos iniciales y finales.
4. Los resultados capturan parcialmente una tarea sin el inicio o el final reales
El algoritmo de IA identifica las secuencias de pasos más consistentes como tarea candidata. Dependiendo de la variabilidad de los usuarios que ejecutan la tarea, la mitad de una tarea puede ser más consistente que el inicio y / o el final, lo que hace que el algoritmo detecte esta subtarea como candidata en lugar de la tarea de principio a fin.
Es probable que esto suceda cuando el inicio y / o el final de una tarea implica aplicaciones altamente multifuncionales, como Outlook, Excel, etc. Es probable que estas aplicaciones se utilicen durante varias tareas, y es difícil para el algoritmo distinguir apariciones específicas de ellas como inicio o final de una tarea candidata. En este caso, recomendamos centrarse en la mayor parte de las tareas, no cubrir el 100% de todos los clics que hace un usuario. Si la tarea es candidata adecuada para la automatización, el inicio y el final que faltan se pueden agregar al crear la automatización.
5. Los resultados muestran una tarea poco realista
Es posible que la tarea candidata descubierta no parezca realista o no sea una tarea reconocible. Si una tarea candidata no tiene sentido desde una perspectiva empresarial, es probable que sea ruido y pueda descartarse.
Priorizar tareas candidatas para el análisis
Dependiendo de los datos registrados, el algoritmo de Task Mining puede identificar muchas tareas candidatas. Por lo tanto, es importante que el revisor priorice qué candidatos analizar primero para no perder tiempo en candidatos de tarea que probablemente no sean candidatos de automatización adecuados. La página Resultados de la detección y sus KPI proporcionan información para esta priorización.
Las tareas candidatas en los resultados de Discovery están ordenadas por la probabilidad de que sean un candidato de automatización adecuado. Cuanto más arriba esté la tarea candidata en la lista, más probabilidades hay de que sea una buena candidata a la automatización. La tarea candidata con el nombre 'Tarea 0' ha sido identificada como mejor candidata de automatización por el algoritmo Unassisted Task Mining, teniendo en cuenta varios factores, incluida la repetibilidad y la complejidad. Sin embargo, esta clasificación no indica la calidad general de los resultados de Task Mining, pero es más probable que la "Tarea 0" sea mejor que la "Tarea 10".
El revisor también puede modificar la clasificación estándar haciendo clic en los encabezados de las columnas. Las tres opciones de orden disponibles para la columna Nombre de tarea son de mayor a menor potencial de automatización, de menor a mayor potencial de automatización y según el nombre de la tarea.
Utiliza el botón Solo tareas significativas para filtrar y mostrar solo las tareas que tienen al menos 5 acciones, 3 pasos y 30 segundos de tiempo de ejecución. Esto debería reducir el ruido de los resultados.
![]()
Concéntrate en grupos de tareas más grandes. Los candidatos a tarea que se agrupan a menudo son candidatos a tarea más significativos. Busca el mejor representante de la tarea dentro de un grupo de tareas. Al analizar una tarea candidata que es representativa del grupo, puede ocurrir que esta tarea candidata tenga un alto potencial de automatización, pero la tarea de principio a fin no sea del todo correcta. En ese caso, recomendamos comprobar los candidatos a tareas alternativas del grupo para obtener un mejor representante. Una vez que el revisor haya encontrado un mejor representante, puede seleccionarlo y marcarlo como nuevo representante para este grupo de tareas.
Dentro de un grupo de tareas, céntrate en las tareas de mayor rango. Por lo general, las alternativas de tareas mejor clasificadas dentro de un grupo son de mayor calidad. Las alternativas de tareas clasificadas por encima de 10 o 20 suelen ser de menor calidad.
Durante el análisis de los candidatos a tareas alternativas, puede quedar claro que algunos de ellos se relacionan con una tarea diferente a la representativa. En este caso, el revisor puede crear un nuevo grupo de tareas basado en estas tareas alternativas.
Investiga las métricas de los diferentes candidatos a tarea. Cada candidato a tarea muestra diferentes métricas como el tiempo total dedicado por los usuarios a esta tarea, el número de usuarios que han realizado esta tarea, el número de pasos en la tarea más representativa, etc. Considere estas métricas en su análisis y aplique sus propios criterios en función del contexto empresarial de su proyecto de Task Mining, por ejemplo, podemos ver que la Tarea 7 tiene un tiempo total, un número de seguimientos y pasos mucho más bajos en comparación con la Tarea 1 y el Grupo de tareas Nuevo. Esto podría indicar que la Tarea 7 tiene un potencial de automatización más bajo. Sin embargo, ten en cuenta que no hay directrices generales sobre el tiempo total grande o pequeño que se mantienen en todos los estudios de Task Mining. Estas métricas siempre deben interpretarse en el contexto empresarial del proyecto específico de Task Mining.
Utiliza la funcionalidad de marcar y cambiar el nombre. Al priorizar las diferentes tareas candidatas para un análisis más profundo, es importante mantener una visión general de lo que se ha priorizado o incluso de lo que ya se ha analizado. Marcar y cambiar el nombre de los candidatos a tareas puede ayudar a estructurar el análisis.
Analizar candidatos a tareas individuales
Una vez que el revisor haya priorizado las diferentes tareas candidatas, puede comenzar su análisis. Para guiar al revisor, la siguiente sección proporciona primero algunos puntos de vista a tener en cuenta durante el análisis y, posteriormente, una guía paso a paso sobre cómo navegar por la vista de análisis.
Tener en cuenta durante el análisis
Los pasos se basan en pantallas. La tarea candidata y sus pasos se muestran en el nivel de una interfaz/pantalla de usuario única y no representan acciones de clic o escritura individuales. Los clics múltiples o las acciones de escritura que se producen en la misma pantalla generalmente se agruparán por el algoritmo de Task Mining. Por lo tanto, el gráfico no muestra cada clic o acción de escritura individual.
Una tarea candidata necesita al menos dos pasos (pantallas) para ser identificada como tal. Para que el algoritmo de Task Mining identifique un candidato a tarea, debe constar de un paso de inicio y un paso final claros. Por lo tanto, una tarea que solo se realiza en una pantalla no se identificará como candidata a tarea.
Los pasos son los mismos en los diferentes candidatos a tarea. Los pasos no están vinculados a un candidato a tarea específico. Un paso que se produce en un candidato a tarea también puede ocurrir en otro. Esto significa que acciones como cambiar el nombre de un paso tendrán efecto en todo el proyecto.
El algoritmo de enmascaramiento PII puede marcar incorrectamente o no marcar algo como PII. El módulo PII es un algoritmo de IA que puede detectar PII. Puede ocurrir que el algoritmo cometa un error y parte de la PII no esté enmascarada o el texto que no sea PII esté enmascarado. Estos errores dependen del texto detectado en la pantalla, así como del contexto de las propias palabras. Si el texto no es capturado por el OCR o está parcialmente cortado, es posible que no esté enmascarado. Además, si las otras palabras en la pantalla son diferentes, es posible que el mismo texto se identifique como PII en una pantalla y no PII en otra.
Si un candidato a tarea no tiene sentido visual al examinar los seguimientos, es probable que no sea un candidato a tarea de alta calidad. El algoritmo puede detectar candidatos a tareas ruidosos e irrelevantes, especialmente en los rangos inferiores de la clasificación de tareas. Estas tareas candidatas pueden ser muy cortas o muy largas y extremadamente variables. Una vez que esto quede claro después de examinar algunos seguimientos, no debes perder el tiempo intentando interpretarlos.
Busca la mayor parte del proceso (regla 80/20). Los candidatos a tareas pueden no alinearse completamente con las tareas de la vida real esperadas, sino que solo cubren parcialmente subpartes de ellas. Como ya se ha mencionado anteriormente, dependiendo de la variabilidad de los usuarios que ejecutan la tarea, ciertos pasos de una tarea pueden ser más coherentes que otros, lo que hace que el algoritmo solo detecte ciertos pasos de la tarea como candidatos en lugar de la tarea completa de principio a fin.
La tarea candidata puede seguir siendo adecuada para la automatización independientemente de los pasos que falten. Estos se pueden añadir al crear la automatización.
Desplácese por los resultados. Los seguimientos de un candidato a tarea y las capturas de pantalla de los pasos se ordenan cronológicamente. Por lo tanto, se recomienda desplazarse por las listas para revisar los resultados en varios puntos.
Análisis paso a paso
Para analizar de cerca los candidatos de tarea priorizados, siga los pasos a continuación. Esto ayudará a diferenciar entre los candidatos a la automatización y las tareas ruido
- Analizar el paso de inicio y finalización de la tarea candidata para determinar su calidad
- Haz clic en el paso, esto mostrará las capturas de pantalla en el lado derecho de la pantalla.
- Examina las capturas de pantalla del paso de inicio y final del candidato a tarea para comprender lo que está sucediendo. Un paso de alta calidad es coherente en la aplicación utilizada y el trabajo que se realiza. Si las capturas de pantalla del paso de inicio o final muestran muchas pantallas y acciones diferentes, sus seguimientos serán muy inconsistentes. Esto es una indicación de que el candidato a la tarea probablemente no sea un buen candidato para la automatización.
- Las capturas de pantalla están ordenadas cronológicamente, por lo que es una buena práctica revisar las capturas de pantalla al principio, en medio y al final de la lista.
- Cambia el nombre de los pasos para que mantengas una visión general de los pasos revisados.
- Abrir y revisar los pasos clave del proceso
-
Encuentra pasos clave ajustando el filtro de ocurrencia de pasos en la parte inferior. Intenta equilibrar la varianza y la comprensibilidad. Empujar el control deslizante más hacia la izquierda generalmente reduce la complejidad a costa de la integridad. Para hacerlo más fácil, debes mover el control deslizante hacia la izquierda para tener solo 2-3 pasos además del paso de inicio y final.
-
Filtrar para seguimientos de alta calidad. El filtro para los seguimientos de ruta más frecuentes puede proporcionar el seguimiento más útil, por lo que se recomienda analizar estos seguimientos primero. Aplique el filtro para ver solo los seguimientos que siguen esta ruta más frecuente. Este filtro está disponible en el panel de filtros
-
Revisa las capturas de pantalla como se describe en el análisis de los pasos de inicio y finalización. Algunos pasos inconsistentes y ruidosos son aceptables, pero idealmente, un candidato a tarea con alto potencial de automatización tendrá al menos algunos pasos de alta calidad en el medio del gráfico que forman parte de la mayoría de los seguimientos.
-
Renombra los pasos. Esto te ayuda a mantener una visión general de qué pasos se han revisado.
-
- Revisar seguimientos
- Los seguimientos están ordenados cronológicamente. Recomendamos revisar los seguimientos al principio, en el centro y hacia el final.
- Una tarea candidata de alta calidad contendrá muchos seguimientos que se parecen. Busque los siguientes indicadores:
- Los seguimientos tienen pasos similares en medio del seguimiento.
- Los seguimientos tienen sentido desde una perspectiva empresarial.
- Consulta las capturas de pantalla para ver si la información de seguimiento del elemento en el que se trabaja es la misma dentro de cada seguimiento, pero diferente entre seguimientos (por ejemplo, ID de incidencia, nombre del cliente, número de factura, etc.). Asegúrate de analizar esto en el nivel correcto, ya que un número de factura puede aparecer en varios seguimientos, pero cada seguimiento cubre una línea diferente de la factura.
- Si durante el análisis de los seguimientos determinas que la tarea candidata es de mala calidad, se recomienda no centrarse en ellos y pasar a la siguiente tarea candidata en tu lista de prioridades.
- Filtra los seguimientos de baja calidad. Incluso un candidato a tarea de alta calidad contendrá algunos seguimientos de baja calidad, en los que el algoritmo cometió un error. Estos seguimientos a menudo serán mucho más largos o mucho más cortos que otros e incluirán ruido o acciones irrelevantes. Elimínalos aplicando los filtros situados junto a la barra de búsqueda. Ajusta los filtros en función de los histogramas para filtrar los seguimientos.
A menudo, los seguimientos de alta calidad formarán una protuberancia mayor dentro del histograma. Si hay pequeños picos en los bordes, lejos del volumen principal del histograma, recomendamos usar los controles deslizante para eliminarlos y ver si mejoran el gráfico de la tarea y los seguimientos. Los seguimientos con recuentos de pasos y acciones muy bajos o muy altos probablemente no sean candidatos de tarea adecuados.
Si deseas volver a una configuración de filtro específica en el futuro, utiliza la funcionalidad de guardar vistas .
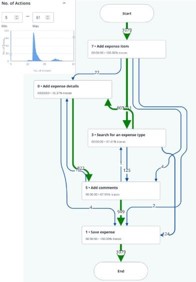
- Si el paso deseado no se muestra en el gráfico, ve a un seguimiento específico. Establezca la frecuencia en 100 % y elimine el filtro "Mostrar solo pasos clave". A continuación, vuelve a todos los seguimientos y filtra por el paso deseado.
- Volver a calcular pasos
- Una vez que haya seleccionado seguimientos de alta calidad e identificado las actividades clave, se recomienda volver a calcular. Seleccione solo los pasos clave que deben incluirse en la tarea candidata, omita los pasos irrelevantes o con mucho ruido y defina el orden correcto de los pasos.
Tenga en cuenta que esto también reducirá aún más los pasos que tiene disponibles para el siguiente cálculo. Por lo tanto, reducir los candidatos de tarea podría resultar más difícil. La opción de volver a calcular también incluye un historial de versiones que le permite volver a cargar una versión anterior de una tarea candidata si no está satisfecho con el resultado de un nuevo cálculo.
Cambiar el nombre de los pasos
El cambio de nombre de los pasos tiene dos finalidades. Primero, hace que los pasos sean más interpretables. En segundo lugar, le permite distinguir entre alta calidad y ruido. Dado que los pasos pueden ocurrir en varias tareas candidatas, cambiarles el nombre le ahorrará la molestia de volver a revisarlas en la siguiente tarea candidata. Algunas prácticas recomendadas:
- Paso de alta calidad: cambiar el nombre a Nombre de la aplicación + verbo + nombre. No es posible filtrar por aplicaciones, pero puede filtrar por nombres de paso. Cuando se utilizan varias aplicaciones para la tarea, el análisis es más fácil.
- Pasos de ruido: cambiar el nombre a ruido.