- Introducción
- Información general
- Cómo pueden las empresas utilizar Communications Mining™
- Primeros pasos con Communications Mining™
- Configuración de su cuenta
- Equilibrio
- Clústeres
- Deriva del concepto
- Cobertura
- Conjuntos de datos
- Campos generales
- Etiquetas (predicciones, niveles de confianza, jerarquía de etiquetas y sentimiento de etiqueta)
- Modelos
- Transmisiones
- Clasificación del modelo
- Proyectos
- Precisión
- Recordar
- Mensajes anotados y no anotados
- Campos extraídos
- Fuentes
- Taxonomías
- Formación
- Predicciones positivas y negativas verdaderas y falsas
- Validación
- Mensajes
- Control y administración de acceso
- Gestionar fuentes y conjuntos de datos
- Comprender la estructura de datos y los permisos
- Crear o eliminar un origen de datos en la GUI
- Preparando datos para cargar archivos .CSV
- Cargar un archivo CSV en un origen
- Crear un conjunto de datos
- Fuentes y conjuntos de datos multilingües
- Habilitar sentimiento en un conjunto de datos
- Modificar la configuración del conjunto de datos
- Eliminar un mensaje
- Eliminar un conjunto de datos
- Exportar un conjunto de datos
- Utilizar integraciones de Exchange
- Entrenamiento y mantenimiento de modelos
- Comprender las etiquetas, los campos generales y los metadatos
- Jerarquía de etiquetas y mejores prácticas
- Comparar casos de uso de análisis y automatización
- Convertir tus objetivos en etiquetas
- Descripción general del proceso de entrenamiento del modelo
- Anotación generativa
- Estado de Dastaset
- Entrenamiento de modelos y mejores prácticas de anotación
- Entrenamiento con análisis de sentimiento de etiqueta habilitado
- Comprender los requisitos de datos
- Entrenamiento
- Introducción a Refinar
- Explicación de la precisión y la recuperación
- Precisión y recuperación
- Cómo funciona la validación
- Comprender y mejorar el rendimiento del modelo
- Razones para etiquetar una precisión media baja
- Entrenamiento utilizando la etiqueta Comprobar y la etiqueta Perdida
- Entrenamiento mediante la etiqueta de aprendizaje (refinar)
- Entrenamiento mediante Buscar (Refinar)
- Comprender y aumentar la cobertura
- Mejorar el equilibrio y utilizar Reequilibrar
- Cuándo dejar de entrenar tu modelo
- Uso de campos generales
- Extracción generativa
- Uso de análisis y supervisión
- Automations and Communications Mining™
- Desarrollador
- Uso de la API
- Tutorial de la API
- Fuentes
- Conjuntos de datos
- Comentarios
- Archivos adjuntos
- Predictions
- Crear una transmisión
- Actualizar una transmisión
- Obtener una transmisión por nombre
- Obtener todas las transmisiones
- Eliminar una transmisión
- Obtener resultados de la transmisión
- Obtener comentarios de una transmisión (heredado)
- Avanzar una transmisión
- Restablecer una transmisión
- Etiquetar una excepción
- Desetiquetar una excepción
- Eventos de auditoría
- Obtener todos los usuarios
- Cargar datos
- Descargando datos
- Integración de Exchange con el usuario del servicio de Azure
- Integración de Exchange con la autenticación de aplicaciones de Azure
- Integración de Exchange con Azure Application Authentication y Graph
- Guía de migración: servicios web de Exchange (EWS) a la API de Microsoft Graph
- Obtener datos para Tableau con Python
- Integración de Elasticsearch
- Extracción de campos general
- Integración de Exchange autohospedado
- Marco de automatización de UiPath®
- Actividades oficiales de UiPath®
- Cómo aprenden las máquinas a entender palabras: una guía para las incrustaciones en PNL
- Aprendizaje basado en solicitudes con Transformers
- Efficient Transformers II: destilación de conocimientos y ajuste
- Transformadores eficientes I: mecanismos de atención
- Modelado de intenciones jerárquico profundo no supervisado: obtener valor sin datos de entrenamiento
- Corregir el sesgo de anotación con Communications Mining™
- Aprendizaje activo: mejores modelos ML en menos tiempo
- Todo está en los números: evaluar el rendimiento del modelo con métricas
- Por qué es importante la validación del modelo
- Comparación de Communications Mining™ y Google AutoML para la inteligencia de datos conversacional
- Licencia
- Preguntas frecuentes y más

Guía del usuario de Communications Mining
Cómo pueden las empresas utilizar Communications Mining™
Esta página cubre una descripción general de los siguientes temas:
- Tipos de datos óptimos para Communications Mining.
- Pilares de valor clave para Communications Mining y cómo se vinculan a los casos de uso.
- Casos de uso típicos en análisis y automatización.
- Ejemplos en todos los sectores en los que se puede implementar Communications Mining.
- Ejemplos de clientes de dónde se implementa Communications Mining.
- Qué herramientas de UiPath® puedes combinar con Communications Mining, incluidos RPA y Document Understanding™.
Tipos de datos óptimos para Communications Mining
 | Communications Mining está optimizado para datos de comunicaciones asíncronas de formato corto, como correos electrónicos (por ejemplo, bandejas de entrada de correo electrónico compartidas), tickets, respuestas de encuestas y notas de casos. |
 | Communications Mining no admite actualmente datos de llamadas y chat en tiempo real. Para el análisis histórico de los datos de chat y llamadas, la plataforma puede admitirlos si los volúmenes son lo suficientemente grandes. |
 | Communications Mining no procesa de forma nativa los archivos adjuntos, que son documentos, pero se pueden combinar con Document Understanding™ para procesar tanto correos electrónicos como archivos adjuntos. |
Communications Mining solo se utiliza para analizar y automatizar correos electrónicos de direcciones de correo electrónico corporativas y no la dirección de correo electrónico personal de un individuo, por ejemplo, john.doe@yahoo.com o jane.doe@gmail.com.
Pilares de valor para Communications Mining
Communications Mining puede generar valor para las empresas de muchas maneras. En última instancia, los objetivos empresariales determinarán el valor que busca el propietario de un caso de uso, y los pilares de valor se alinearán con casos de uso específicos.
El siguiente diagrama detalla algunos de los pilares de valor clave que Communications Mining puede soportar, y algunos de los casos de uso que se alinean con ellos:

Caso de uso: análisis
Como se ha descrito hasta ahora, Communications Mining abre oportunidades significativas tanto para el análisis como para la automatización para los clientes.
Para el análisis, algunos grupos clave de casos de uso incluyen:

Caso de uso: automatización
Para la automatización, los casos de uso típicos son:

Ejemplos del sector
Por lo general, los clientes preguntan dónde se puede implementar Communications Mining y la respuesta es en cualquier lugar.
En todas las industrias, cada proceso y acción en pantalla, desde la atención al cliente hasta el pedido de piezas en la fabricación, pasando por cotizaciones de seguros, reclamaciones y renovaciones, comienza con alguna forma de comunicación.
A medida que las empresas crecen, necesitan soluciones, como Communications Mining, que les ayuden a gestionar eficazmente estas comunicaciones. De lo contrario, corren el riesgo de quedarse atrás.
Ejemplo de casos de uso de clientes
La siguiente lista contiene algunos ejemplos específicos de cómo nuestros clientes suelen utilizar Communications Mining:

Combinar herramientas de UiPath® con Communications Mining
Aunque Communications Mining puede ser parte de una solución, aprovechando muchas herramientas diferentes de UiPath, o un ejercicio de descubrimiento, también utilizando Process Mining o Task Mining, o ambos, su integración más directa e impactante es con RPA y Document Understanding™.
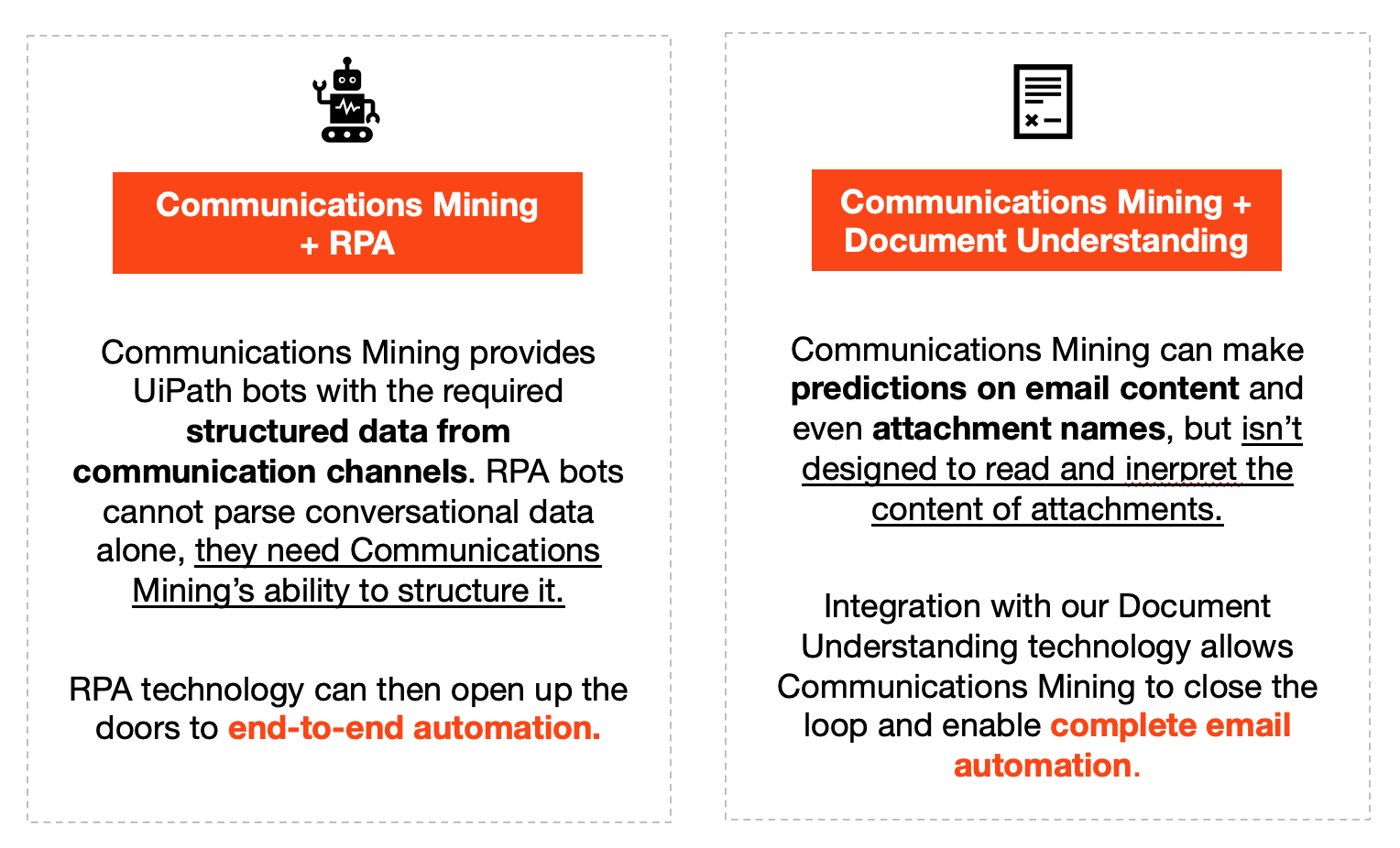
Communications Mining y RPA
Como se ha explicado en la sección anterior, Communications Mining actúa como habilitador de la automatización inteligente al proporcionar datos estructurados a las automatizaciones posteriores para que tomen medidas.
Esta transición suele ser a un UiPath® Robot. El siguiente diagrama proporciona una descripción general de alto nivel de cómo Communications Mining y RPA pueden trabajar juntos:

Para obtener más detalles sobre cómo Communications Mining se combina con RPA para la automatización, consulta la Introducción a la documentación de la API.
Aunque Communications Mining está optimizado para interactuar con otras herramientas de UiPath, otras aplicaciones que priorizan la API aprovechan las predicciones de Communications Mining para facilitar los casos de uso de análisis y automatización.
Communications Mining y Document Understanding


Communications Mining y Document Understanding pueden manejar diferentes tipos de datos, pero en última instancia pueden unirse para formar una potente solución combinada.
Todas las empresas del mundo procesan documentos que se intercambian a través de comunicaciones:
- Communications Mining y Document Understanding permiten a las empresas comprender y automatizar procesos de servicio complejos E2E
- Tareas en las que antes los empleados necesitaban leer tanto mensajes como documentos para completar su trabajo.
- Crean una fuente de datos completamente nueva para los robots de UiPath. Por primera vez, las empresas pueden automatizar algunos de los procesos de servicio más intensivos y que consumen más tiempo.
Cómo funcionan juntos Communications Mining y Document Understanding
La siguiente imagen contiene un flujo de trabajo gráfico de cómo Communications Mining y Document Understanding trabajan juntos:

- Tipos de datos óptimos para Communications Mining
- Pilares de valor para Communications Mining
- Caso de uso: análisis
- Caso de uso: automatización
- Ejemplos del sector
- Ejemplo de casos de uso de clientes
- Combinar herramientas de UiPath® con Communications Mining
- Communications Mining y RPA
- Communications Mining y Document Understanding